 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking and Simplifying Bootstrapped Graph Latents
Dec 05, 2023


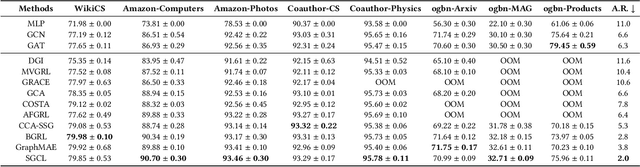
Graph contrastive learning (GCL) has emerged as a representative paradigm in graph self-supervised learning, where negative samples are commonly regarded as the key to preventing model collapse and producing distinguishable representations. Recent studies have shown that GCL without negative samples can achieve state-of-the-art performance as well as scalability improvement, with bootstrapped graph latent (BGRL) as a prominent step forward. However, BGRL relies on a complex architecture to maintain the ability to scatter representations, and the underlying mechanisms enabling the success remain largely unexplored. In this paper, we introduce an instance-level decorrelation perspective to tackle the aforementioned issue and leverage it as a springboard to reveal the potential unnecessary model complexity within BGRL. Based on our findings, we present SGCL, a simple yet effective GCL framework that utilizes the outputs from two consecutive iterations as positive pairs, eliminating the negative samples. SGCL only requires a single graph augmentation and a single graph encoder without additional parameters. Extensive experiments conducted on various graph benchmarks demonstrate that SGCL can achieve competitive performance with fewer parameters, lower time and space costs, and significant convergence speedup.
Scaling Up, Scaling Deep: Blockwise Graph Contrastive Learning
Jun 03, 2023



Oversmoothing is a common phenomenon in graph neural networks (GNNs), in which an increase in the network depth leads to a deterioration in their performance. Graph contrastive learning (GCL) is emerging as a promising way of leveraging vast unlabeled graph data. As a marriage between GNNs and contrastive learning, it remains unclear whether GCL inherits the same oversmoothing defect from GNNs. This work undertakes a fundamental analysis of GCL from the perspective of oversmoothing on the first hand. We demonstrate empirically that increasing network depth in GCL also leads to oversmoothing in their deep representations, and surprisingly, the shallow ones. We refer to this phenomenon in GCL as long-range starvation', wherein lower layers in deep networks suffer from degradation due to the lack of sufficient guidance from supervision (e.g., loss computing). Based on our findings, we present BlockGCL, a remarkably simple yet effective blockwise training framework to prevent GCL from notorious oversmoothing. Without bells and whistles, BlockGCL consistently improves robustness and stability for well-established GCL methods with increasing numbers of layers on real-world graph benchmarks. We believe our work will provide insights for future improvements of scalable and deep GCL frameworks.
MaskGAE: Masked Graph Modeling Meets Graph Autoencoders
May 20, 2022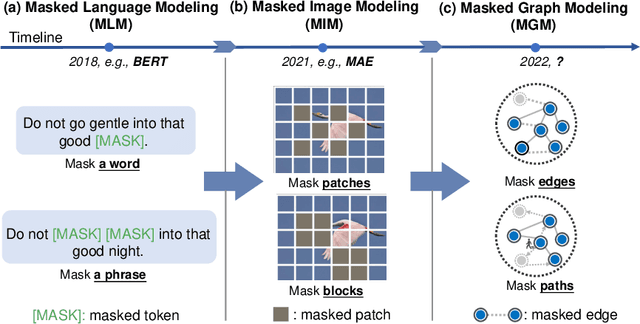
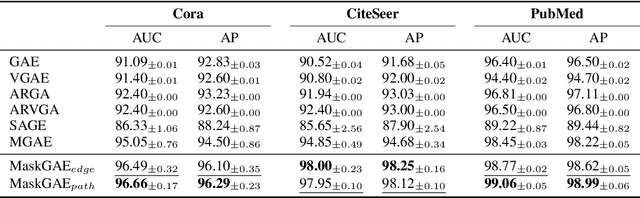

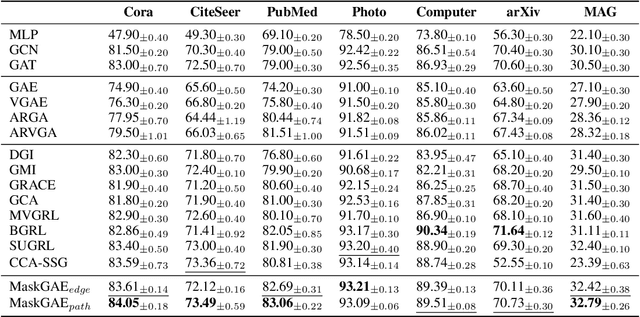
We present masked graph autoencoder (MaskGAE), a self-supervised learning framework for graph-structured data. Different from previous graph autoencoders (GAEs), MaskGAE adopts masked graph modeling (MGM) as a principled pretext task: masking a portion of edges and attempting to reconstruct the missing part with partially visible, unmasked graph structure. To understand whether MGM can help GAEs learn better representations, we provide both theoretical and empirical evidence to justify the benefits of this pretext task. Theoretically, we establish the connections between GAEs and contrastive learning, showing that MGM significantly improves the self-supervised learning scheme of GAEs. Empirically, we conduct extensive experiments on a number of benchmark datasets, demonstrating the superiority of MaskGAE over several state-of-the-arts on both link prediction and node classification tasks. Our code is publicly available at \url{https://github.com/EdisonLeeeee/MaskGAE}.
FastGCL: Fast Self-Supervised Learning on Graphs via Contrastive Neighborhood Aggregation
May 02, 2022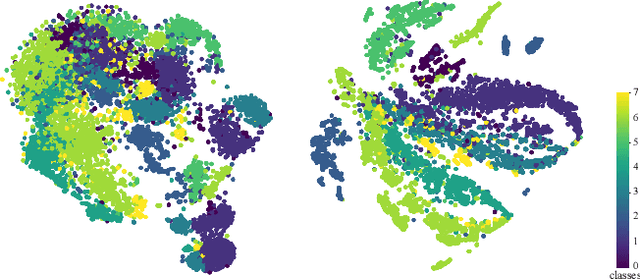

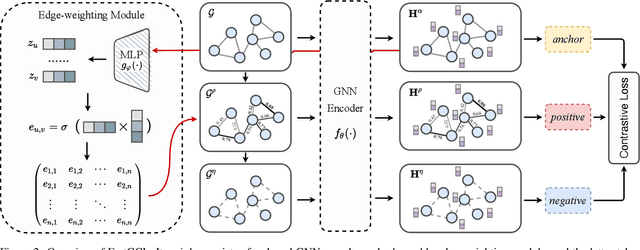
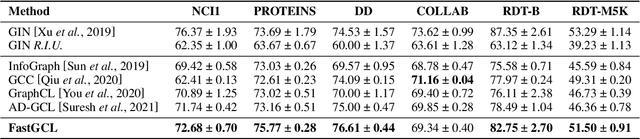
Graph contrastive learning (GCL), as a popular approach to graph self-supervised learning, has recently achieved a non-negligible effect. To achieve superior performance, the majority of existing GCL methods elaborate on graph data augmentation to construct appropriate contrastive pairs. However, existing methods place more emphasis on the complex graph data augmentation which requires extra time overhead, and pay less attention to developing contrastive schemes specific to encoder characteristics. We argue that a better contrastive scheme should be tailored to the characteristics of graph neural networks (e.g., neighborhood aggregation) and propose a simple yet effective method named FastGCL. Specifically, by constructing weighted-aggregated and non-aggregated neighborhood information as positive and negative samples respectively, FastGCL identifies the potential semantic information of data without disturbing the graph topology and node attributes, resulting in faster training and convergence speeds. Extensive experiments have been conducted on node classification and graph classification tasks, showing that FastGCL has competitive classification performance and significant training speedup compared to existing state-of-the-art methods.