 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasp-Then-Plan with Failure Attribution: A Closed Two-Stage Framework for Precise and Generalizable Robotic Manipulation
Jun 02, 2026In robotic manipulation, the tight coupling between grasping and motion planning often obscures the true source of failure, leading to inefficient trial-and-error. To enable efficient long-horizon manipulation, we propose GTP-FA (Grasp-Then-Plan with Failure Attribution), a task-oriented two-stage grasp-then-plan framework that generates grasp candidates and performs downstream motion planning conditioned on the selected grasp. Given a failed manipulation trajectory, we learn a failure attribution model that generalizes to unseen grasps and produces a stable distribution over failure modes for diagnosis-guided optimization. Based on these attribution results, we then optimize both modules in a diagnosis-driven manner: on the grasping side, we inject task-level priors and risk penalties into grasp candidate scoring and optimization to suppress unstable or task-incompatible grasps; on the planning side, we target high-risk initial states through data collection and fine-tuning to address genuine planning bottlenecks. We evaluate the proposed framework in both simulation and real-robot experiments, and show that GTP-FA improves the corresponding base learners across RL, IL, diffusion-policy, and VLA-based settings, achieving substantially higher overall task success rates.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
InternVQA: Advancing Compressed Video Quality Assessment with Distilling Large Foundation Model
Feb 26, 2025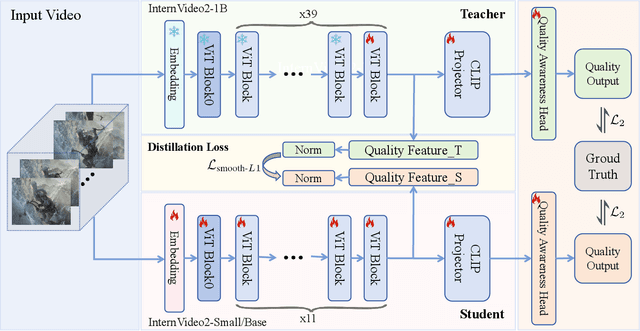
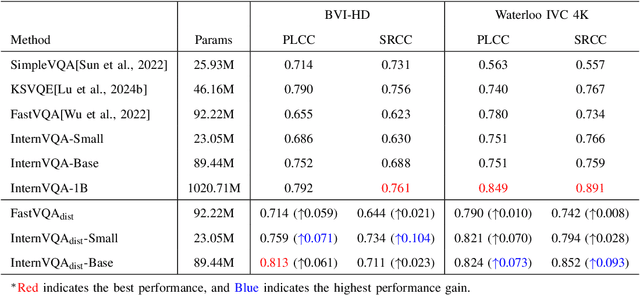
Video quality assessment tasks rely heavily on the rich features required for video understanding, such as semantic information, texture, and temporal motion. The existing video foundational model, InternVideo2, has demonstrated strong potential in video understanding tasks due to its large parameter size and large-scale multimodal data pertaining. Building on this, we explored the transferability of InternVideo2 to video quality assessment under compression scenarios. To design a lightweight model suitable for this task, we proposed a distillation method to equip the smaller model with rich compression quality priors. Additionally, we examined the performance of different backbones during the distillation process. The results showed that, compared to other methods, our lightweight model distilled from InternVideo2 achieved excellent performance in compression video quality assessment.
DHIL-GT: Scalable Graph Transformer with Decoupled Hierarchy Labeling
Dec 06, 2024



Graph Transformer (GT) has recently emerged as a promising neural network architecture for learning graph-structured data. However, its global attention mechanism with quadratic complexity concerning the graph scale prevents wider application to large graphs. While current methods attempt to enhance GT scalability by altering model architecture or encoding hierarchical graph data, our analysis reveals that these models still suffer from the computational bottleneck related to graph-scale operations. In this work, we target the GT scalability issue and propose DHIL-GT, a scalable Graph Transformer that simplifies network learning by fully decoupling the graph computation to a separate stage in advance. DHIL-GT effectively retrieves hierarchical information by exploiting the graph labeling technique, as we show that the graph label hierarchy is more informative than plain adjacency by offering global connections while promoting locality, and is particularly suitable for handling complex graph patterns such as heterophily. We further design subgraph sampling and positional encoding schemes for precomputing model input on top of graph labels in an end-to-end manner. The training stage thus favorably removes graph-related computations, leading to ideal mini-batch capability and GPU utilization. Notably, the precomputation and training processes of DHIL-GT achieve complexities linear to the number of graph edges and nodes, respectively. Extensive experiments demonstrate that DHIL-GT is efficient in terms of computational boost and mini-batch capability over existing scalable Graph Transformer designs on large-scale benchmarks, while achieving top-tier effectiveness on both homophilous and heterophilous graphs.
MLAN: Language-Based Instruction Tuning Improves Zero-Shot Generalization of Multimodal Large Language Models
Nov 19, 2024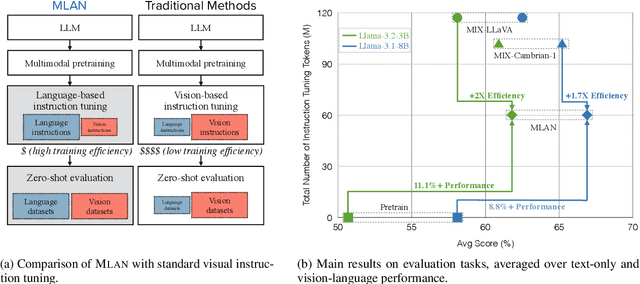
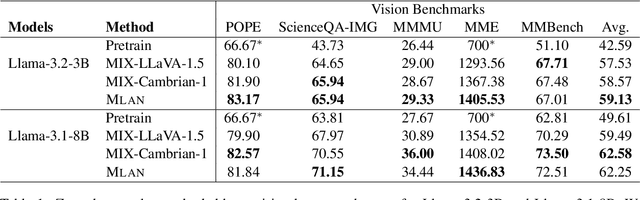
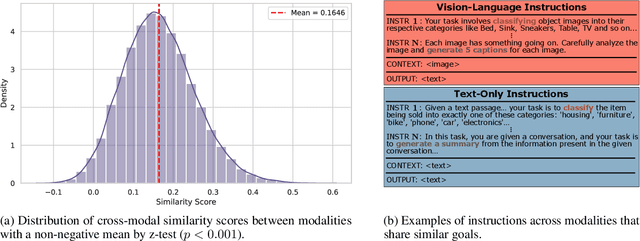
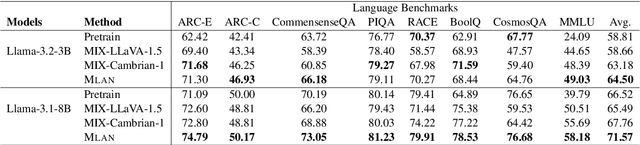
We present a novel instruction tuning recipe to improve the zero-shot task generalization of multimodal large language models. In contrast to existing instruction tuning mechanisms that heavily rely on visual instructions, our approach focuses on language-based instruction tuning, offering a distinct and more training efficient path for multimodal instruction tuning. We evaluate the performance of the proposed approach on 9 unseen datasets across both language and vision modalities. Our results show that our language-only instruction tuning is able to significantly improve the performance of two pretrained multimodal models based on Llama 2 and Vicuna on those unseen datasets. Interestingly, the language instruction following ability also helps unlock the models to follow vision instructions without explicit training. Compared to the state of the art multimodal instruction tuning approaches that are mainly based on visual instructions, our language-based method not only achieves superior performance but also significantly enhances training efficiency. For instance, the language-only instruction tuning produces competitive average performance across the evaluated datasets (with even better performance on language datasets) with significant training efficiency improvements (on average 4x), thanks to the striking reduction in the need for vision data. With a small number of visual instructions, this emerging language instruction following ability transfers well to the unseen vision datasets, outperforming the state of the art with greater training efficiency.
Q-Mamba: On First Exploration of Vision Mamba for Image Quality Assessment
Jun 13, 2024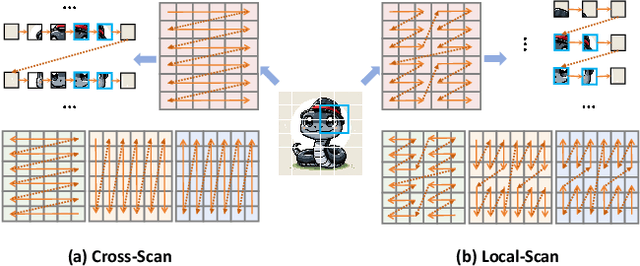
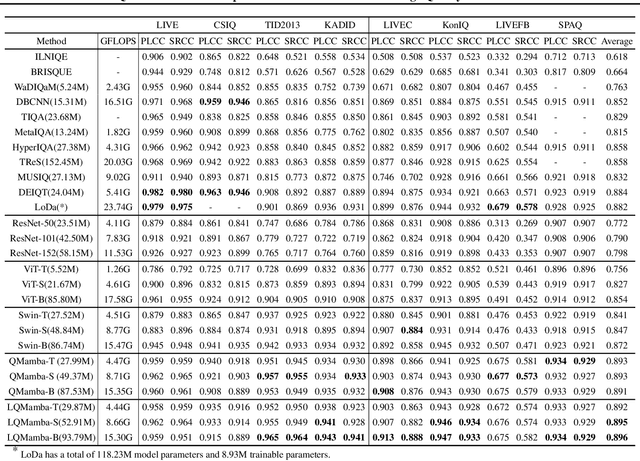
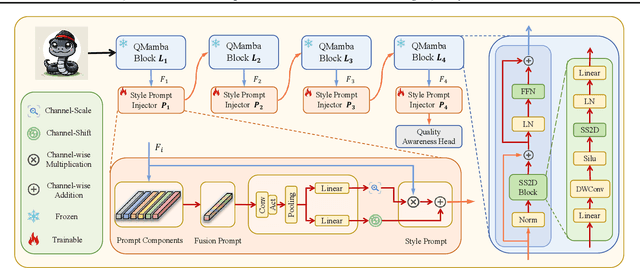
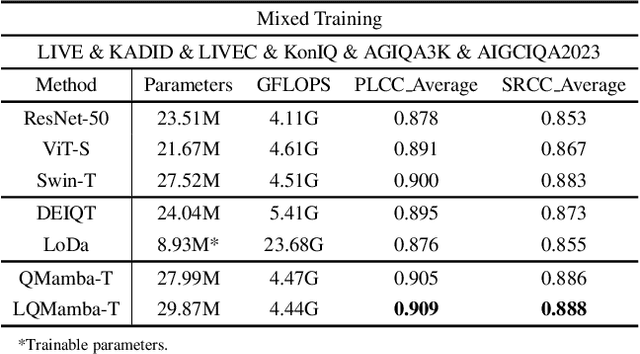
In this work, we take the first exploration of the recently popular foundation model, i.e., State Space Model/Mamba, in image quality assessment, aiming at observing and excavating the perception potential in vision Mamba. A series of works on Mamba has shown its significant potential in various fields, e.g., segmentation and classification. However, the perception capability of Mamba has been under-explored. Consequently, we propose Q-Mamba by revisiting and adapting the Mamba model for three crucial IQA tasks, i.e., task-specific, universal, and transferable IQA, which reveals that the Mamba model has obvious advantages compared with existing foundational models, e.g., Swin Transformer, ViT, and CNNs, in terms of perception and computational cost for IQA. To increase the transferability of Q-Mamba, we propose the StylePrompt tuning paradigm, where the basic lightweight mean and variance prompts are injected to assist the task-adaptive transfer learning of pre-trained Q-Mamba for different downstream IQA tasks. Compared with existing prompt tuning strategies, our proposed StylePrompt enables better perception transfer capability with less computational cost. Extensive experiments on multiple synthetic, authentic IQA datasets, and cross IQA datasets have demonstrated the effectiveness of our proposed Q-Mamba.
Unifews: Unified Entry-Wise Sparsification for Efficient Graph Neural Network
Mar 20, 2024Graph Neural Networks (GNNs) have shown promising performance in various graph learning tasks, but at the cost of resource-intensive computations. The primary overhead of GNN update stems from graph propagation and weight transformation, both involving operations on graph-scale matrices. Previous studies attempt to reduce the computational budget by leveraging graph-level or network-level sparsification techniques, resulting in downsized graph or weights. In this work, we propose Unifews, which unifies the two operations in an entry-wise manner considering individual matrix elements, and conducts joint edge-weight sparsification to enhance learning efficiency. The entry-wise design of Unifews enables adaptive compression across GNN layers with progressively increased sparsity, and is applicable to a variety of architectural designs with on-the-fly operation simplification. Theoretically, we establish a novel framework to characterize sparsified GNN learning in view of a graph optimization process, and prove that Unifews effectively approximates the learning objective with bounded error and reduced computational load. We conduct extensive experiments to evaluate the performance of our method in diverse settings. Unifews is advantageous in jointly removing more than 90% of edges and weight entries with comparable or better accuracy than baseline models. The sparsification offers remarkable efficiency improvements including 10-20x matrix operation reduction and up to 100x acceleration in graph propagation time for the largest graph at the billion-edge scale.
Video Quality Assessment Based on Swin TransformerV2 and Coarse to Fine Strategy
Jan 16, 2024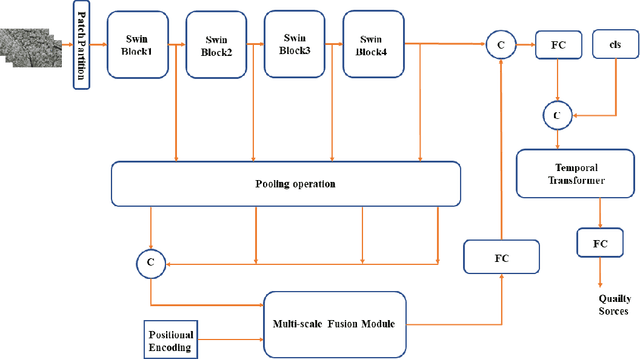
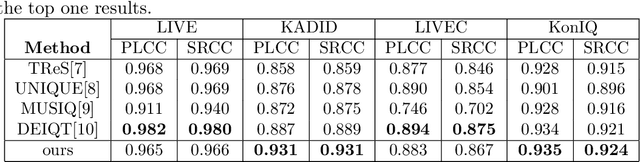
The objective of non-reference video quality assessment is to evaluate the quality of distorted video without access to reference high-definition references. In this study, we introduce an enhanced spatial perception module, pre-trained on multiple image quality assessment datasets, and a lightweight temporal fusion module to address the no-reference visual quality assessment (NR-VQA) task. This model implements Swin Transformer V2 as a local-level spatial feature extractor and fuses these multi-stage representations through a series of transformer layers. Furthermore, a temporal transformer is utilized for spatiotemporal feature fusion across the video. To accommodate compressed videos of varying bitrates, we incorporate a coarse-to-fine contrastive strategy to enrich the model's capability to discriminate features from videos of different bitrates. This is an expanded version of the one-page abstract.
FISEdit: Accelerating Text-to-image Editing via Cache-enabled Sparse Diffusion Inference
May 27, 2023



Due to the recent success of diffusion models, text-to-image generation is becoming increasingly popular and achieves a wide range of applications. Among them, text-to-image editing, or continuous text-to-image generation, attracts lots of attention and can potentially improve the quality of generated images. It's common to see that users may want to slightly edit the generated image by making minor modifications to their input textual descriptions for several rounds of diffusion inference. However, such an image editing process suffers from the low inference efficiency of many existing diffusion models even using GPU accelerators. To solve this problem, we introduce Fast Image Semantically Edit (FISEdit), a cached-enabled sparse diffusion model inference engine for efficient text-to-image editing. The key intuition behind our approach is to utilize the semantic mapping between the minor modifications on the input text and the affected regions on the output image. For each text editing step, FISEdit can automatically identify the affected image regions and utilize the cached unchanged regions' feature map to accelerate the inference process. Extensive empirical results show that FISEdit can be $3.4\times$ and $4.4\times$ faster than existing methods on NVIDIA TITAN RTX and A100 GPUs respectively, and even generates more satisfactory images.
AdaSfM: From Coarse Global to Fine Incremental Adaptive Structure from Motion
Jan 28, 2023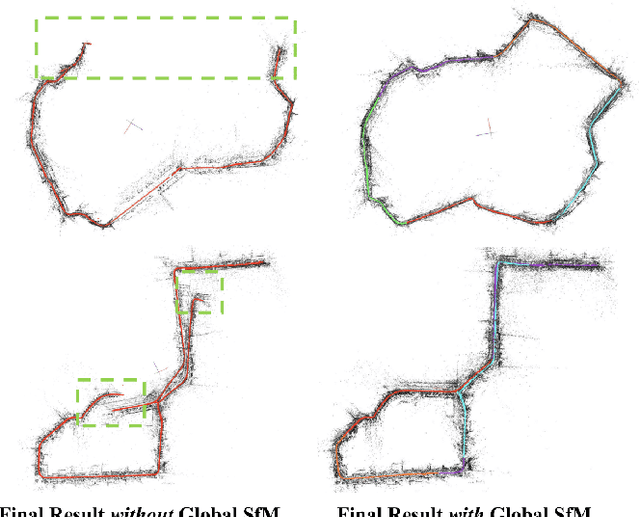
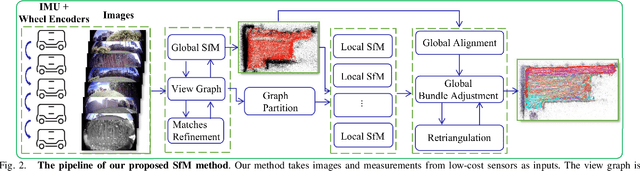

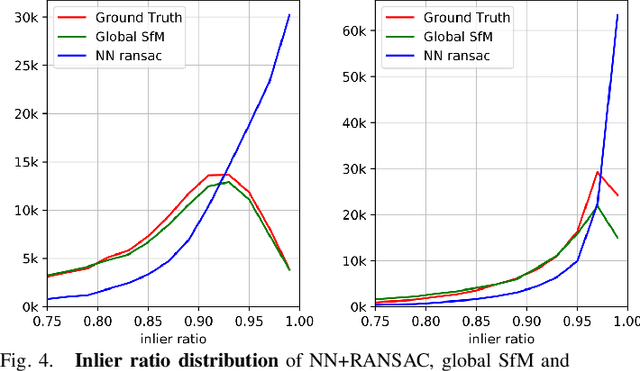
Despite the impressive results achieved by many existing Structure from Motion (SfM) approaches, there is still a need to improve the robustness, accuracy, and efficiency on large-scale scenes with many outlier matches and sparse view graphs. In this paper, we propose AdaSfM: a coarse-to-fine adaptive SfM approach that is scalable to large-scale and challenging datasets. Our approach first does a coarse global SfM which improves the reliability of the view graph by leveraging measurements from low-cost sensors such as Inertial Measurement Units (IMUs) and wheel encoders. Subsequently, the view graph is divided into sub-scenes that are refined in parallel by a fine local incremental SfM regularised by the result from the coarse global SfM to improve the camera registration accuracy and alleviate scene drifts. Finally, our approach uses a threshold-adaptive strategy to align all local reconstructions to the coordinate frame of global SfM. Extensive experiments on large-scale benchmark datasets show that our approach achieves state-of-the-art accuracy and efficiency.