 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Mamba: On First Exploration of Vision Mamba for Image Quality Assessment
Paper and Code
Jun 13, 2024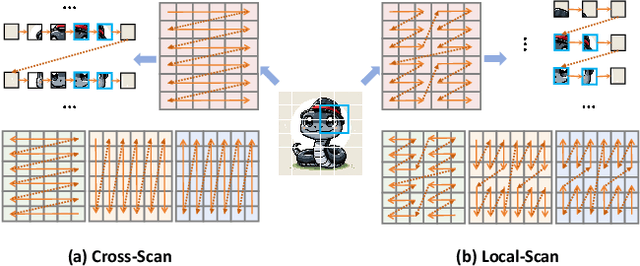
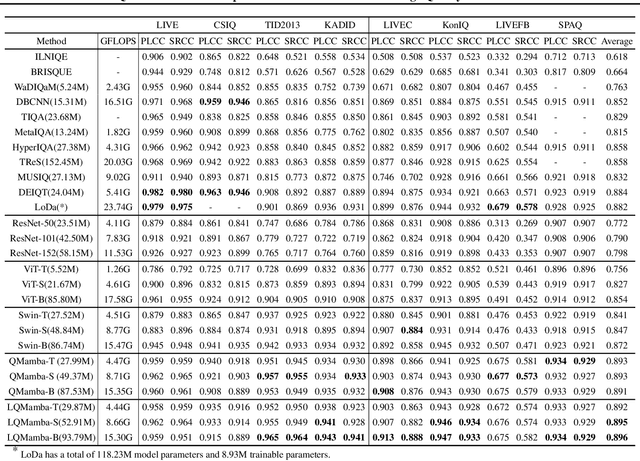
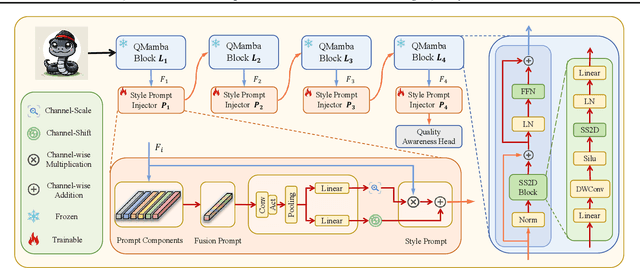
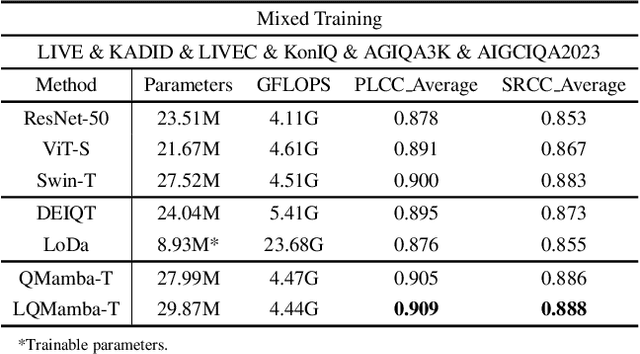
In this work, we take the first exploration of the recently popular foundation model, i.e., State Space Model/Mamba, in image quality assessment, aiming at observing and excavating the perception potential in vision Mamba. A series of works on Mamba has shown its significant potential in various fields, e.g., segmentation and classification. However, the perception capability of Mamba has been under-explored. Consequently, we propose Q-Mamba by revisiting and adapting the Mamba model for three crucial IQA tasks, i.e., task-specific, universal, and transferable IQA, which reveals that the Mamba model has obvious advantages compared with existing foundational models, e.g., Swin Transformer, ViT, and CNNs, in terms of perception and computational cost for IQA. To increase the transferability of Q-Mamba, we propose the StylePrompt tuning paradigm, where the basic lightweight mean and variance prompts are injected to assist the task-adaptive transfer learning of pre-trained Q-Mamba for different downstream IQA tasks. Compared with existing prompt tuning strategies, our proposed StylePrompt enables better perception transfer capability with less computational cost. Extensive experiments on multiple synthetic, authentic IQA datasets, and cross IQA datasets have demonstrated the effectiveness of our proposed Q-Mamba.