 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
InternVQA: Advancing Compressed Video Quality Assessment with Distilling Large Foundation Model
Feb 26, 2025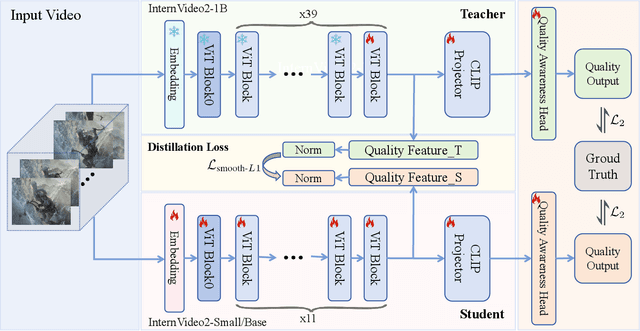
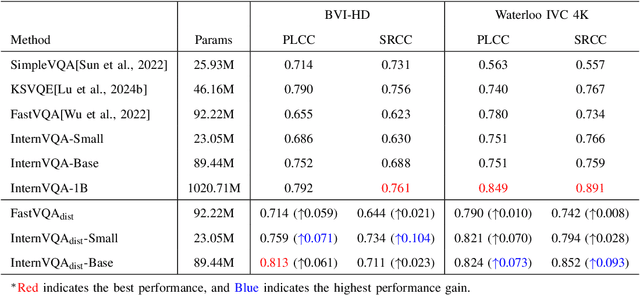
Video quality assessment tasks rely heavily on the rich features required for video understanding, such as semantic information, texture, and temporal motion. The existing video foundational model, InternVideo2, has demonstrated strong potential in video understanding tasks due to its large parameter size and large-scale multimodal data pertaining. Building on this, we explored the transferability of InternVideo2 to video quality assessment under compression scenarios. To design a lightweight model suitable for this task, we proposed a distillation method to equip the smaller model with rich compression quality priors. Additionally, we examined the performance of different backbones during the distillation process. The results showed that, compared to other methods, our lightweight model distilled from InternVideo2 achieved excellent performance in compression video quality assessment.
Q-Mamba: On First Exploration of Vision Mamba for Image Quality Assessment
Jun 13, 2024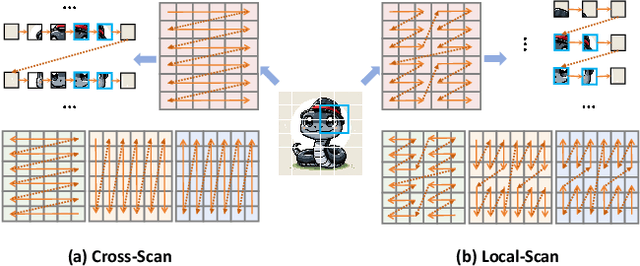
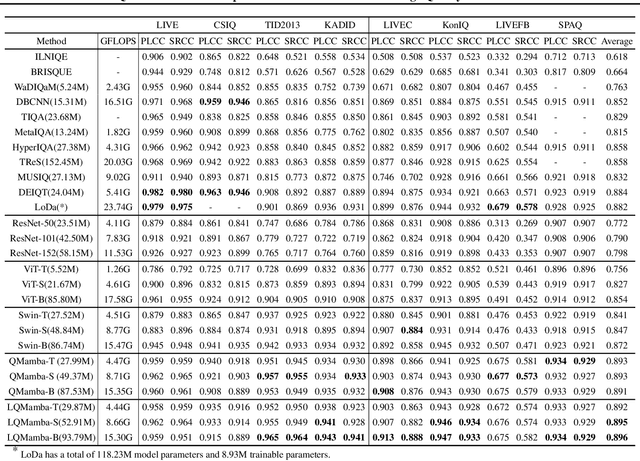
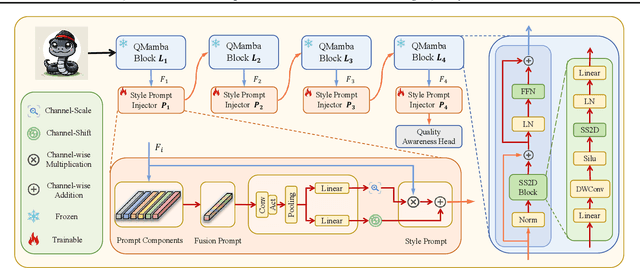
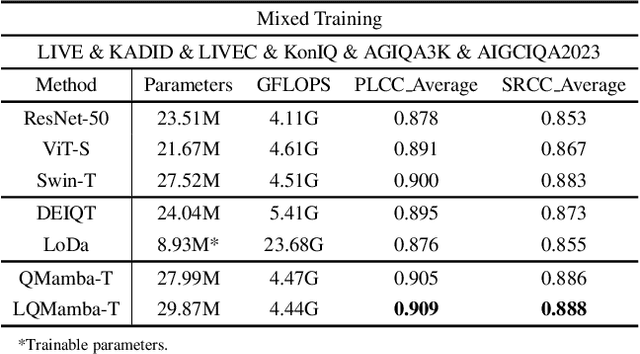
In this work, we take the first exploration of the recently popular foundation model, i.e., State Space Model/Mamba, in image quality assessment, aiming at observing and excavating the perception potential in vision Mamba. A series of works on Mamba has shown its significant potential in various fields, e.g., segmentation and classification. However, the perception capability of Mamba has been under-explored. Consequently, we propose Q-Mamba by revisiting and adapting the Mamba model for three crucial IQA tasks, i.e., task-specific, universal, and transferable IQA, which reveals that the Mamba model has obvious advantages compared with existing foundational models, e.g., Swin Transformer, ViT, and CNNs, in terms of perception and computational cost for IQA. To increase the transferability of Q-Mamba, we propose the StylePrompt tuning paradigm, where the basic lightweight mean and variance prompts are injected to assist the task-adaptive transfer learning of pre-trained Q-Mamba for different downstream IQA tasks. Compared with existing prompt tuning strategies, our proposed StylePrompt enables better perception transfer capability with less computational cost. Extensive experiments on multiple synthetic, authentic IQA datasets, and cross IQA datasets have demonstrated the effectiveness of our proposed Q-Mamba.
Video Quality Assessment Based on Swin TransformerV2 and Coarse to Fine Strategy
Jan 16, 2024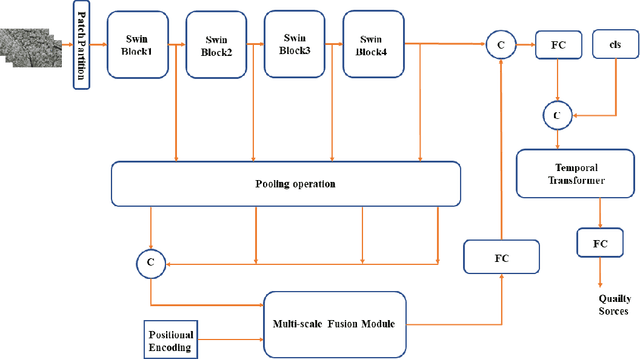
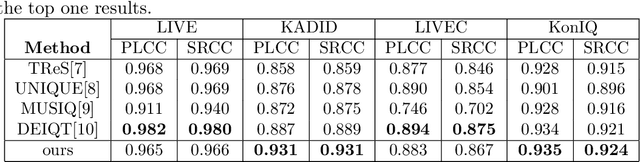
The objective of non-reference video quality assessment is to evaluate the quality of distorted video without access to reference high-definition references. In this study, we introduce an enhanced spatial perception module, pre-trained on multiple image quality assessment datasets, and a lightweight temporal fusion module to address the no-reference visual quality assessment (NR-VQA) task. This model implements Swin Transformer V2 as a local-level spatial feature extractor and fuses these multi-stage representations through a series of transformer layers. Furthermore, a temporal transformer is utilized for spatiotemporal feature fusion across the video. To accommodate compressed videos of varying bitrates, we incorporate a coarse-to-fine contrastive strategy to enrich the model's capability to discriminate features from videos of different bitrates. This is an expanded version of the one-page abstract.