 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Quality Assessment Based on Swin TransformerV2 and Coarse to Fine Strategy
Paper and Code
Jan 16, 2024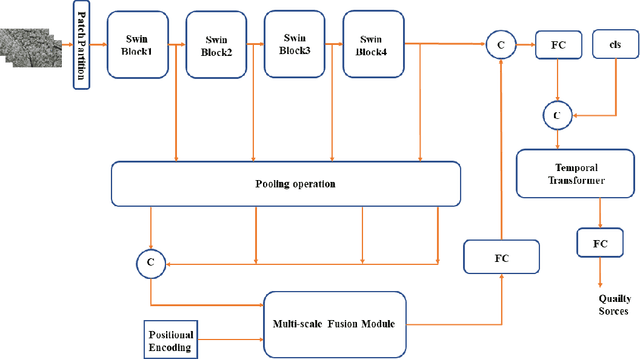
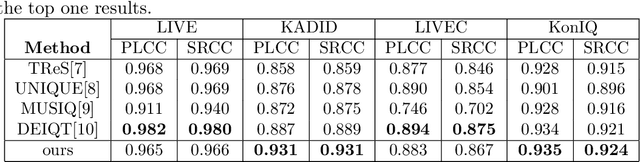
The objective of non-reference video quality assessment is to evaluate the quality of distorted video without access to reference high-definition references. In this study, we introduce an enhanced spatial perception module, pre-trained on multiple image quality assessment datasets, and a lightweight temporal fusion module to address the no-reference visual quality assessment (NR-VQA) task. This model implements Swin Transformer V2 as a local-level spatial feature extractor and fuses these multi-stage representations through a series of transformer layers. Furthermore, a temporal transformer is utilized for spatiotemporal feature fusion across the video. To accommodate compressed videos of varying bitrates, we incorporate a coarse-to-fine contrastive strategy to enrich the model's capability to discriminate features from videos of different bitrates. This is an expanded version of the one-page abstract.