 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind Your HEARTBEAT! Claw Background Execution Inherently Enables Silent Memory Pollution
Mar 25, 2026We identify a critical security vulnerability in mainstream Claw personal AI agents: untrusted content encountered during heartbeat-driven background execution can silently pollute agent memory and subsequently influence user-facing behavior without the user's awareness. This vulnerability arises from an architectural design shared across the Claw ecosystem: heartbeat background execution runs in the same session as user-facing conversation, so content ingested from any external source monitored in the background (including email, message channels, news feeds, code repositories, and social platforms) can enter the same memory context used for foreground interaction, often with limited user visibility and without clear source provenance. We formalize this process as an Exposure (E) $\rightarrow$ Memory (M) $\rightarrow$ Behavior (B) pathway: misinformation encountered during heartbeat execution enters the agent's short-term session context, potentially gets written into long-term memory, and later shapes downstream user-facing behavior. We instantiate this pathway in an agent-native social setting using MissClaw, a controlled research replica of Moltbook. We find that (1) social credibility cues, especially perceived consensus, are the dominant driver of short-term behavioral influence, with misleading rates up to 61%; (2) routine memory-saving behavior can promote short-term pollution into durable long-term memory at rates up to 91%, with cross-session behavioral influence reaching 76%; (3) under naturalistic browsing with content dilution and context pruning, pollution still crosses session boundaries. Overall, prompt injection is not required: ordinary social misinformation is sufficient to silently shape agent memory and behavior under heartbeat-driven background execution.
Understanding and Preserving Safety in Fine-Tuned LLMs
Jan 15, 2026Fine-tuning is an essential and pervasive functionality for applying large language models (LLMs) to downstream tasks. However, it has the potential to substantially degrade safety alignment, e.g., by greatly increasing susceptibility to jailbreak attacks, even when the fine-tuning data is entirely harmless. Despite garnering growing attention in defense efforts during the fine-tuning stage, existing methods struggle with a persistent safety-utility dilemma: emphasizing safety compromises task performance, whereas prioritizing utility typically requires deep fine-tuning that inevitably leads to steep safety declination. In this work, we address this dilemma by shedding new light on the geometric interaction between safety- and utility-oriented gradients in safety-aligned LLMs. Through systematic empirical analysis, we uncover three key insights: (I) safety gradients lie in a low-rank subspace, while utility gradients span a broader high-dimensional space; (II) these subspaces are often negatively correlated, causing directional conflicts during fine-tuning; and (III) the dominant safety direction can be efficiently estimated from a single sample. Building upon these novel insights, we propose safety-preserving fine-tuning (SPF), a lightweight approach that explicitly removes gradient components conflicting with the low-rank safety subspace. Theoretically, we show that SPF guarantees utility convergence while bounding safety drift. Empirically, SPF consistently maintains downstream task performance and recovers nearly all pre-trained safety alignment, even under adversarial fine-tuning scenarios. Furthermore, SPF exhibits robust resistance to both deep fine-tuning and dynamic jailbreak attacks. Together, our findings provide new mechanistic understanding and practical guidance toward always-aligned LLM fine-tuning.
Safety at One Shot: Patching Fine-Tuned LLMs with A Single Instance
Jan 06, 2026Fine-tuning safety-aligned large language models (LLMs) can substantially compromise their safety. Previous approaches require many safety samples or calibration sets, which not only incur significant computational overhead during realignment but also lead to noticeable degradation in model utility. Contrary to this belief, we show that safety alignment can be fully recovered with only a single safety example, without sacrificing utility and at minimal cost. Remarkably, this recovery is effective regardless of the number of harmful examples used in fine-tuning or the size of the underlying model, and convergence is achieved within just a few epochs. Furthermore, we uncover the low-rank structure of the safety gradient, which explains why such efficient correction is possible. We validate our findings across five safety-aligned LLMs and multiple datasets, demonstrating the generality of our approach.
Are Time-Series Foundation Models Deployment-Ready? A Systematic Study of Adversarial Robustness Across Domains
May 26, 2025Time Series Foundation Models (TSFMs), which are pretrained on large-scale, cross-domain data and capable of zero-shot forecasting in new scenarios without further training, are increasingly adopted in real-world applications. However, as the zero-shot forecasting paradigm gets popular, a critical yet overlooked question emerges: Are TSFMs robust to adversarial input perturbations? Such perturbations could be exploited in man-in-the-middle attacks or data poisoning. To address this gap, we conduct a systematic investigation into the adversarial robustness of TSFMs. Our results show that even minimal perturbations can induce significant and controllable changes in forecast behaviors, including trend reversal, temporal drift, and amplitude shift, posing serious risks to TSFM-based services. Through experiments on representative TSFMs and multiple datasets, we reveal their consistent vulnerabilities and identify potential architectural designs, such as structural sparsity and multi-task pretraining, that may improve robustness. Our findings offer actionable guidance for designing more resilient forecasting systems and provide a critical assessment of the adversarial robustness of TSFMs.
SHAPE : Self-Improved Visual Preference Alignment by Iteratively Generating Holistic Winner
Mar 06, 2025



Large Visual Language Models (LVLMs) increasingly rely on preference alignment to ensure reliability, which steers the model behavior via preference fine-tuning on preference data structured as ``image - winner text - loser text'' triplets. However, existing approaches often suffer from limited diversity and high costs associated with human-annotated preference data, hindering LVLMs from fully achieving their intended alignment capabilities. We present \projectname, a self-supervised framework capable of transforming the already abundant supervised text-image pairs into holistic preference triplets for more effective and cheaper LVLM alignment, eliminating the need for human preference annotations. Our approach facilitates LVLMs in progressively enhancing alignment capabilities through iterative self-improvement. The key design rationale is to devise preference triplets where the winner text consistently improves in holisticness and outperforms the loser response in quality, thereby pushing the model to ``strive to the utmost'' of alignment performance through preference fine-tuning. For each given text-image pair, SHAPE introduces multiple visual augmentations and pairs them with a summarized text to serve as the winner response, while designating the original text as the loser response. Experiments across \textbf{12} benchmarks on various model architectures and sizes, including LLaVA and DeepSeek-VL, show that SHAPE achieves significant gains, for example, achieving +11.3\% on MMVet (comprehensive evaluation), +1.4\% on MMBench (general VQA), and +8.0\% on POPE (hallucination robustness) over baselines in 7B models. Notably, qualitative analyses confirm enhanced attention to visual details and better alignment with human preferences for holistic descriptions.
Unify and Anchor: A Context-Aware Transformer for Cross-Domain Time Series Forecasting
Mar 03, 2025The rise of foundation models has revolutionized natural language processing and computer vision, yet their best practices to time series forecasting remains underexplored. Existing time series foundation models often adopt methodologies from these fields without addressing the unique characteristics of time series data. In this paper, we identify two key challenges in cross-domain time series forecasting: the complexity of temporal patterns and semantic misalignment. To tackle these issues, we propose the ``Unify and Anchor" transfer paradigm, which disentangles frequency components for a unified perspective and incorporates external context as domain anchors for guided adaptation. Based on this framework, we introduce ContexTST, a Transformer-based model that employs a time series coordinator for structured representation and the Transformer blocks with a context-informed mixture-of-experts mechanism for effective cross-domain generalization. Extensive experiments demonstrate that ContexTST advances state-of-the-art forecasting performance while achieving strong zero-shot transferability across diverse domains.
SecPE: Secure Prompt Ensembling for Private and Robust Large Language Models
Feb 02, 2025



With the growing popularity of LLMs among the general public users, privacy-preserving and adversarial robustness have become two pressing demands for LLM-based services, which have largely been pursued separately but rarely jointly. In this paper, to the best of our knowledge, we are among the first attempts towards robust and private LLM inference by tightly integrating two disconnected fields: private inference and prompt ensembling. The former protects users' privacy by encrypting inference data transmitted and processed by LLMs, while the latter enhances adversarial robustness by yielding an aggregated output from multiple prompted LLM responses. Although widely recognized as effective individually, private inference for prompt ensembling together entails new challenges that render the naive combination of existing techniques inefficient. To overcome the hurdles, we propose SecPE, which designs efficient fully homomorphic encryption (FHE) counterparts for the core algorithmic building blocks of prompt ensembling. We conduct extensive experiments on 8 tasks to evaluate the accuracy, robustness, and efficiency of SecPE. The results show that SecPE maintains high clean accuracy and offers better robustness at the expense of merely $2.5\%$ efficiency overhead compared to baseline private inference methods, indicating a satisfactory ``accuracy-robustness-efficiency'' tradeoff. For the efficiency of the encrypted Argmax operation that incurs major slowdown for prompt ensembling, SecPE is 35.4x faster than the state-of-the-art peers, which can be of independent interest beyond this work.
Activation Approximations Can Incur Safety Vulnerabilities Even in Aligned LLMs: Comprehensive Analysis and Defense
Feb 02, 2025



Large Language Models (LLMs) have showcased remarkable capabilities across various domains. Accompanying the evolving capabilities and expanding deployment scenarios of LLMs, their deployment challenges escalate due to their sheer scale and the advanced yet complex activation designs prevalent in notable model series, such as Llama, Gemma, and Mistral. These challenges have become particularly pronounced in resource-constrained deployment scenarios, where mitigating inference efficiency bottlenecks is imperative. Among various recent efforts, activation approximation has emerged as a promising avenue for pursuing inference efficiency, sometimes considered indispensable in applications such as private inference. Despite achieving substantial speedups with minimal impact on utility, even appearing sound and practical for real-world deployment, the safety implications of activation approximations remain unclear. In this work, we fill this critical gap in LLM safety by conducting the first systematic safety evaluation of activation approximations. Our safety vetting spans seven sota techniques across three popular categories, revealing consistent safety degradation across ten safety-aligned LLMs.
HEP-NAS: Towards Efficient Few-shot Neural Architecture Search via Hierarchical Edge Partitioning
Dec 14, 2024One-shot methods have significantly advanced the field of neural architecture search (NAS) by adopting weight-sharing strategy to reduce search costs. However, the accuracy of performance estimation can be compromised by co-adaptation. Few-shot methods divide the entire supernet into individual sub-supernets by splitting edge by edge to alleviate this issue, yet neglect relationships among edges and result in performance degradation on huge search space. In this paper, we introduce HEP-NAS, a hierarchy-wise partition algorithm designed to further enhance accuracy. To begin with, HEP-NAS treats edges sharing the same end node as a hierarchy, permuting and splitting edges within the same hierarchy to directly search for the optimal operation combination for each intermediate node. This approach aligns more closely with the ultimate goal of NAS. Furthermore, HEP-NAS selects the most promising sub-supernet after each segmentation, progressively narrowing the search space in which the optimal architecture may exist. To improve performance evaluation of sub-supernets, HEP-NAS employs search space mutual distillation, stabilizing the training process and accelerating the convergence of each individual sub-supernet. Within a given budget, HEP-NAS enables the splitting of all edges and gradually searches for architectures with higher accuracy. Experimental results across various datasets and search spaces demonstrate the superiority of HEP-NAS compared to state-of-the-art methods.
ElasTST: Towards Robust Varied-Horizon Forecasting with Elastic Time-Series Transformer
Nov 04, 2024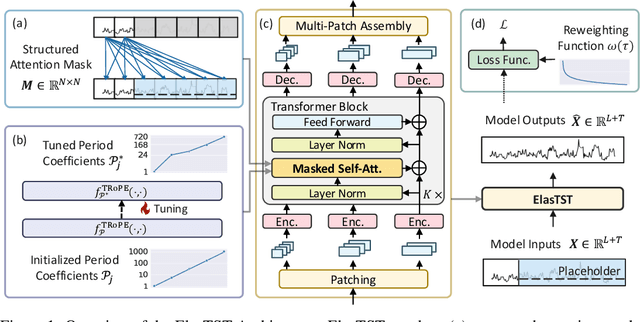
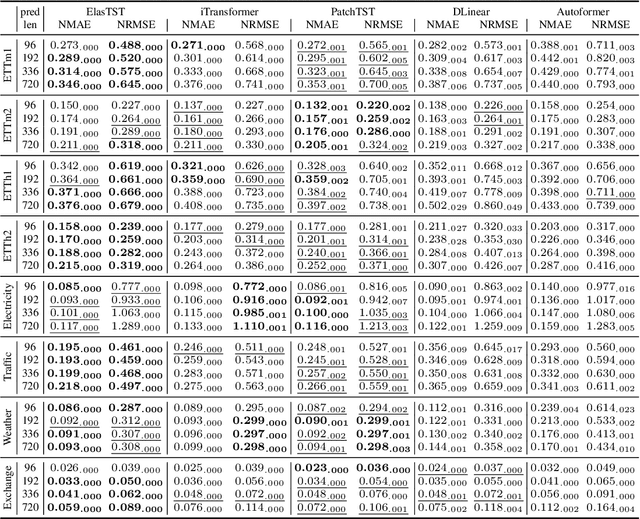
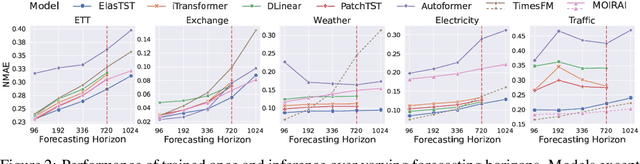
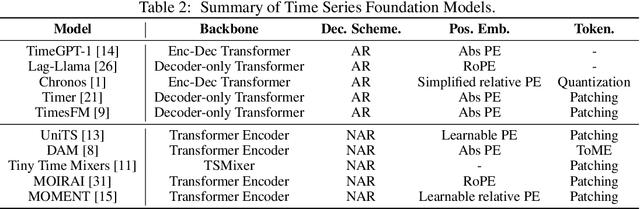
Numerous industrial sectors necessitate models capable of providing robust forecasts across various horizons. Despite the recent strides in crafting specific architectures for time-series forecasting and developing pre-trained universal models, a comprehensive examination of their capability in accommodating varied-horizon forecasting during inference is still lacking. This paper bridges this gap through the design and evaluation of the Elastic Time-Series Transformer (ElasTST). The ElasTST model incorporates a non-autoregressive design with placeholders and structured self-attention masks, warranting future outputs that are invariant to adjustments in inference horizons. A tunable version of rotary position embedding is also integrated into ElasTST to capture time-series-specific periods and enhance adaptability to different horizons. Additionally, ElasTST employs a multi-scale patch design, effectively integrating both fine-grained and coarse-grained information. During the training phase, ElasTST uses a horizon reweighting strategy that approximates the effect of random sampling across multiple horizons with a single fixed horizon setting. Through comprehensive experiments and comparisons with state-of-the-art time-series architectures and contemporary foundation models, we demonstrate the efficacy of ElasTST's unique design elements. Our findings position ElasTST as a robust solution for the practical necessity of varied-horizon forecasting.