 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Graph Representation Learning with Dynamic Information Pathways
Mar 10, 2026Multimodal graphs, where nodes contain heterogeneous features such as images and text, are increasingly common in real-world applications. Effectively learning on such graphs requires both adaptive intra-modal message passing and efficient inter-modal aggregation. However, most existing approaches to multimodal graph learning are typically extended from conventional graph neural networks and rely on static structures or dense attention, which limit flexibility and expressive node embedding learning. In this paper, we propose a novel multimodal graph representation learning framework with Dynamic information Pathways (DiP). By introducing modality-specific pseudo nodes, DiP enables dynamic message routing within each modality via proximity-guided pseudo-node interactions and captures inter-modality dependence through efficient information pathways in a shared state space. This design achieves adaptive, expressive, and sparse message propagation across modalities with linear complexity. We conduct the link prediction and node classification tasks to evaluate performance and carry out full experimental analyses. Extensive experiments across multiple benchmarks demonstrate that DiP consistently outperforms baselines.
Pets: General Pattern Assisted Architecture For Time Series Analysis
Apr 19, 2025



Time series analysis has found widespread applications in areas such as weather forecasting, anomaly detection, and healthcare. However, real-world sequential data often exhibit a superimposed state of various fluctuation patterns, including hourly, daily, and monthly frequencies. Traditional decomposition techniques struggle to effectively disentangle these multiple fluctuation patterns from the seasonal components, making time series analysis challenging. Surpassing the existing multi-period decoupling paradigms, this paper introduces a novel perspective based on energy distribution within the temporal-spectrum space. By adaptively quantifying observed sequences into continuous frequency band intervals, the proposed approach reconstructs fluctuation patterns across diverse periods without relying on domain-specific prior knowledge. Building upon this innovative strategy, we propose Pets, an enhanced architecture that is adaptable to arbitrary model structures. Pets integrates a Fluctuation Pattern Assisted (FPA) module and a Context-Guided Mixture of Predictors (MoP). The FPA module facilitates information fusion among diverse fluctuation patterns by capturing their dependencies and progressively modeling these patterns as latent representations at each layer. Meanwhile, the MoP module leverages these compound pattern representations to guide and regulate the reconstruction of distinct fluctuations hierarchically. Pets achieves state-of-the-art performance across various tasks, including forecasting, imputation, anomaly detection, and classification, while demonstrating strong generalization and robustness.
Unlock the Power of Unlabeled Data in Language Driving Model
Mar 13, 2025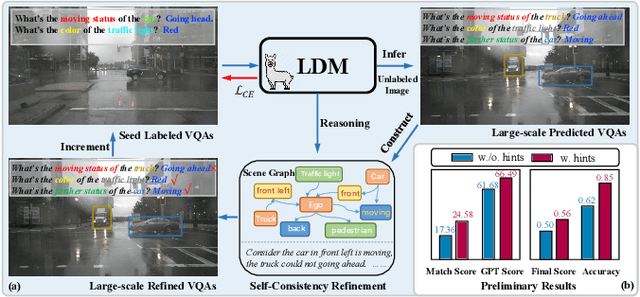

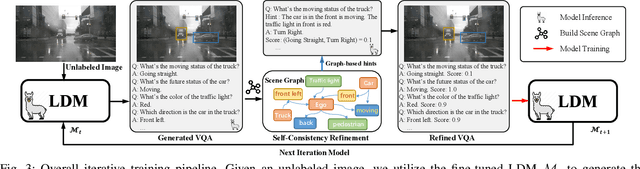

Recent Vision-based Large Language Models~(VisionLLMs) for autonomous driving have seen rapid advancements. However, such promotion is extremely dependent on large-scale high-quality annotated data, which is costly and labor-intensive. To address this issue, we propose unlocking the value of abundant yet unlabeled data to improve the language-driving model in a semi-supervised learning manner. Specifically, we first introduce a series of template-based prompts to extract scene information, generating questions that create pseudo-answers for the unlabeled data based on a model trained with limited labeled data. Next, we propose a Self-Consistency Refinement method to improve the quality of these pseudo-annotations, which are later used for further training. By utilizing a pre-trained VisionLLM (e.g., InternVL), we build a strong Language Driving Model (LDM) for driving scene question-answering, outperforming previous state-of-the-art methods. Extensive experiments on the DriveLM benchmark show that our approach performs well with just 5% labeled data, achieving competitive performance against models trained with full datasets. In particular, our LDM achieves 44.85% performance with limited labeled data, increasing to 54.27% when using unlabeled data, while models trained with full datasets reach 60.68% on the DriveLM benchmark.
Semantic-Supervised Spatial-Temporal Fusion for LiDAR-based 3D Object Detection
Mar 13, 2025



LiDAR-based 3D object detection presents significant challenges due to the inherent sparsity of LiDAR points. A common solution involves long-term temporal LiDAR data to densify the inputs. However, efficiently leveraging spatial-temporal information remains an open problem. In this paper, we propose a novel Semantic-Supervised Spatial-Temporal Fusion (ST-Fusion) method, which introduces a novel fusion module to relieve the spatial misalignment caused by the object motion over time and a feature-level semantic supervision to sufficiently unlock the capacity of the proposed fusion module. Specifically, the ST-Fusion consists of a Spatial Aggregation (SA) module and a Temporal Merging (TM) module. The SA module employs a convolutional layer with progressively expanding receptive fields to aggregate the object features from the local regions to alleviate the spatial misalignment, the TM module dynamically extracts object features from the preceding frames based on the attention mechanism for a comprehensive sequential presentation. Besides, in the semantic supervision, we propose a Semantic Injection method to enrich the sparse LiDAR data via injecting the point-wise semantic labels, using it for training a teacher model and providing a reconstruction target at the feature level supervised by the proposed object-aware loss. Extensive experiments on various LiDAR-based detectors demonstrate the effectiveness and universality of our proposal, yielding an improvement of approximately +2.8% in NDS based on the nuScenes benchmark.
Unify and Anchor: A Context-Aware Transformer for Cross-Domain Time Series Forecasting
Mar 03, 2025The rise of foundation models has revolutionized natural language processing and computer vision, yet their best practices to time series forecasting remains underexplored. Existing time series foundation models often adopt methodologies from these fields without addressing the unique characteristics of time series data. In this paper, we identify two key challenges in cross-domain time series forecasting: the complexity of temporal patterns and semantic misalignment. To tackle these issues, we propose the ``Unify and Anchor" transfer paradigm, which disentangles frequency components for a unified perspective and incorporates external context as domain anchors for guided adaptation. Based on this framework, we introduce ContexTST, a Transformer-based model that employs a time series coordinator for structured representation and the Transformer blocks with a context-informed mixture-of-experts mechanism for effective cross-domain generalization. Extensive experiments demonstrate that ContexTST advances state-of-the-art forecasting performance while achieving strong zero-shot transferability across diverse domains.
UTSD: Unified Time Series Diffusion Model
Dec 04, 2024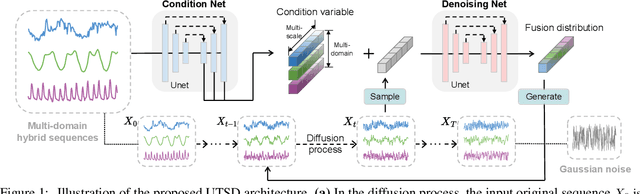

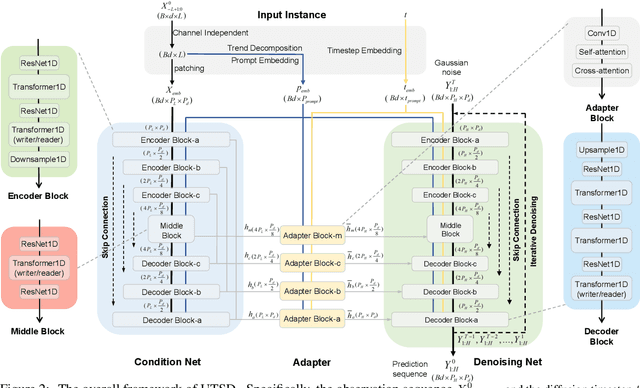

Transformer-based architectures have achieved unprecedented success in time series analysis. However, facing the challenge of across-domain modeling, existing studies utilize statistical prior as prompt engineering fails under the huge distribution shift among various domains. In this paper, a Unified Time Series Diffusion (UTSD) model is established for the first time to model the multi-domain probability distribution, utilizing the powerful probability distribution modeling ability of Diffusion. Unlike the autoregressive models that capture the conditional probabilities of the prediction horizon to the historical sequence, we use a diffusion denoising process to model the mixture distribution of the cross-domain data and generate the prediction sequence for the target domain directly utilizing conditional sampling. The proposed UTSD contains three pivotal designs: (1) The condition network captures the multi-scale fluctuation patterns from the observation sequence, which are utilized as context representations to guide the denoising network to generate the prediction sequence; (2) Adapter-based fine-tuning strategy, the multi-domain universal representation learned in the pretraining stage is utilized for downstream tasks in target domains; (3) The diffusion and denoising process on the actual sequence space, combined with the improved classifier free guidance as the conditional generation strategy, greatly improves the stability and accuracy of the downstream task. We conduct extensive experiments on mainstream benchmarks, and the pre-trained UTSD outperforms existing foundation models on all data domains, exhibiting superior zero-shot generalization ability. After training from scratch, UTSD achieves comparable performance against domain-specific proprietary models. The empirical results validate the potential of UTSD as a time series foundational model.
A Wave is Worth 100 Words: Investigating Cross-Domain Transferability in Time Series
Dec 01, 2024



Time series analysis is a fundamental data mining task that supervised training methods based on empirical risk minimization have proven their effectiveness on specific tasks and datasets. However, the acquisition of well-annotated data is costly and a large amount of unlabeled series data is under-utilized. Due to distributional shifts across various domains and different patterns of interest across multiple tasks. The problem of cross-domain multi-task migration of time series remains a significant challenge. To address these problems, this paper proposes a novel cross-domain pretraining method based on Wave Quantization (termed as WQ4TS), which can be combined with any advanced time series model and applied to multiple downstream tasks. Specifically, we transfer the time series data from different domains into a common spectral latent space, and enable the model to learn the temporal pattern knowledge of different domains directly from the common space and utilize it for the inference of downstream tasks, thereby mitigating the challenge of heterogeneous cross-domains migration. The establishment of spectral latent space brings at least three benefits, cross-domain migration capability thus adapting to zero- and few-shot scenarios without relying on priori knowledge of the dataset, general compatible cross-domain migration framework without changing the existing model structure, and robust modeling capability thus achieving SOTA results in multiple downstream tasks. To demonstrate the effectiveness of the proposed approach, we conduct extensive experiments including three important tasks: forecasting, imputation, and classification. And three common real-world data scenarios are simulated: full-data, few-shot, and zero-shot. The proposed WQ4TS achieves the best performance on 87.5% of all tasks, and the average improvement of the metrics on all the tasks is up to 34.7%.
GCoder: Improving Large Language Model for Generalized Graph Problem Solving
Oct 24, 2024
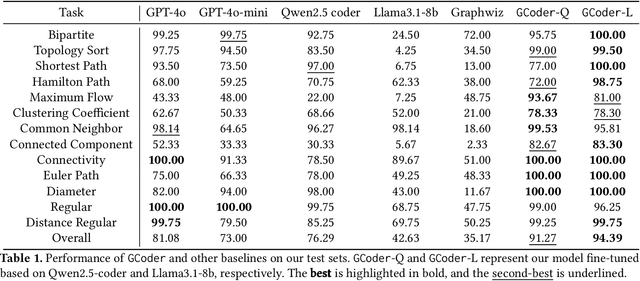


Large Language Models (LLMs) have demonstrated strong reasoning abilities, making them suitable for complex tasks such as graph computation. Traditional reasoning steps paradigm for graph problems is hindered by unverifiable steps, limited long-term reasoning, and poor generalization to graph variations. To overcome these limitations, we introduce GCoder, a code-based LLM designed to enhance problem-solving in generalized graph computation problems. Our method involves constructing an extensive training dataset, GraphWild, featuring diverse graph formats and algorithms. We employ a multi-stage training process, including Supervised Fine-Tuning (SFT) and Reinforcement Learning from Compiler Feedback (RLCF), to refine model capabilities. For unseen tasks, a hybrid retrieval technique is used to augment performance. Experiments demonstrate that GCoder outperforms GPT-4o, with an average accuracy improvement of 16.42% across various graph computational problems. Furthermore, GCoder efficiently manages large-scale graphs with millions of nodes and diverse input formats, overcoming the limitations of previous models focused on the reasoning steps paradigm. This advancement paves the way for more intuitive and effective graph problem-solving using LLMs. Code and data are available at here: https://github.com/Bklight999/WWW25-GCoder/tree/master.
Tran-GCN: A Transformer-Enhanced Graph Convolutional Network for Person Re-Identification in Monitoring Videos
Sep 14, 2024



Person Re-Identification (Re-ID) has gained popularity in computer vision, enabling cross-camera pedestrian recognition. Although the development of deep learning has provided a robust technical foundation for person Re-ID research, most existing person Re-ID methods overlook the potential relationships among local person features, failing to adequately address the impact of pedestrian pose variations and local body parts occlusion. Therefore, we propose a Transformer-enhanced Graph Convolutional Network (Tran-GCN) model to improve Person Re-Identification performance in monitoring videos. The model comprises four key components: (1) A Pose Estimation Learning branch is utilized to estimate pedestrian pose information and inherent skeletal structure data, extracting pedestrian key point information; (2) A Transformer learning branch learns the global dependencies between fine-grained and semantically meaningful local person features; (3) A Convolution learning branch uses the basic ResNet architecture to extract the person's fine-grained local features; (4) A Graph Convolutional Module (GCM) integrates local feature information, global feature information, and body information for more effective person identification after fusion. Quantitative and qualitative analysis experiments conducted on three different datasets (Market-1501, DukeMTMC-ReID, and MSMT17) demonstrate that the Tran-GCN model can more accurately capture discriminative person features in monitoring videos, significantly improving identification accuracy.
DnSwin: Toward Real-World Denoising via Continuous Wavelet Sliding-Transformer
Jul 28, 2022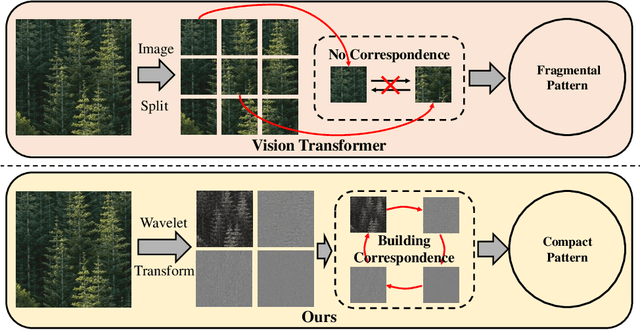
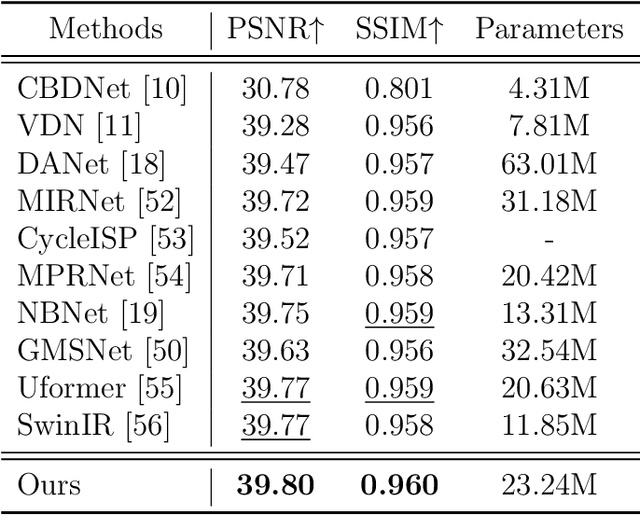
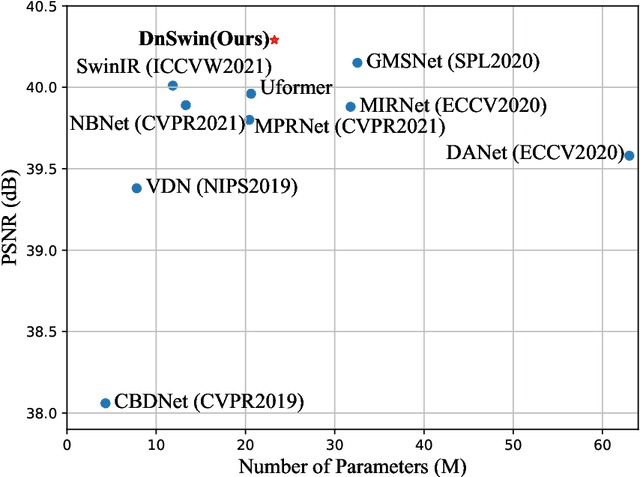
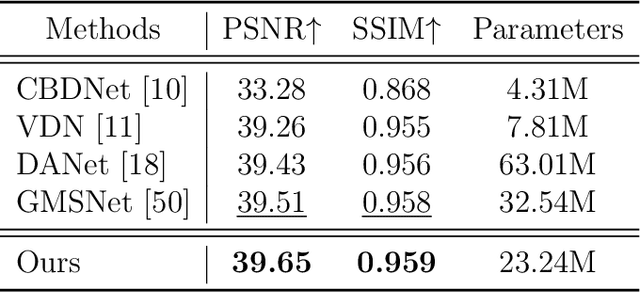
Real-world image denoising is a practical image restoration problem that aims to obtain clean images from in-the-wild noisy input. Recently, Vision Transformer (ViT) exhibits a strong ability to capture long-range dependencies and many researchers attempt to apply ViT to image denoising tasks. However, real-world image is an isolated frame that makes the ViT build the long-range dependencies on the internal patches, which divides images into patches and disarranges the noise pattern and gradient continuity. In this article, we propose to resolve this issue by using a continuous Wavelet Sliding-Transformer that builds frequency correspondence under real-world scenes, called DnSwin. Specifically, we first extract the bottom features from noisy input images by using a CNN encoder. The key to DnSwin is to separate high-frequency and low-frequency information from the features and build frequency dependencies. To this end, we propose Wavelet Sliding-Window Transformer that utilizes discrete wavelet transform, self-attention and inverse discrete wavelet transform to extract deep features. Finally, we reconstruct the deep features into denoised images using a CNN decoder. Both quantitative and qualitative evaluations on real-world denoising benchmarks demonstrate that the proposed DnSwin performs favorably against the state-of-the-art methods.