 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Cross-Modal Emotional Correlation Learning for Speech-Preserving Facial Expression Manipulation
Apr 28, 2026Speech-preserving facial expression manipulation (SPFEM) aims to enhance human expressiveness without altering mouth movements tied to the original speech. A primary challenge in this domain is the scarcity of paired data, namely aligned frames of the same individual with identical speech but different expressions, which impedes direct supervision for emotional manipulation. While current Visual-Language Models (VLMs) can extract aligned visual and semantic features, making them a promising source of supervision, their direct application is limited. To this end, we propose a Personalized Cross-Modal Emotional Correlation Learning (PCMECL) algorithm that refines VLM-based supervision through two major improvements. First, standard VLMs rely on a single generic prompt for each emotion, failing to capture expressive variations among individuals. PCMECL addresses this limitation by conditioning on individual visual information to learn personalized prompts, thereby establishing more fine-grained visual-semantic correlations. Second, even with personalization, inherent discrepancies persist between the visual and semantic feature distributions. To bridge this modality gap, PCMECL employs feature differencing to correlate the modalities, providing more precisely aligned supervision by matching the change in visual features to the change in semantic features. As a plug-and-play module, PCMECL can be seamlessly integrated into existing SPFEM models. Extensive experiments across various datasets demonstrate the superior efficacy of our algorithm.
Learning Spatial-Temporal Coherent Correlations for Speech-Preserving Facial Expression Manipulation
Apr 22, 2026Speech-preserving facial expression manipulation (SPFEM) aims to modify facial emotions while meticulously maintaining the mouth animation associated with spoken content. Current works depend on inaccessible paired training samples for the person, where two aligned frames exhibit the same speech content yet differ in emotional expression, limiting the SPFEM applications in real-world scenarios. In this work, we discover that speakers who convey the same content with different emotions exhibit highly correlated local facial animations in both spatial and temporal spaces, providing valuable supervision for SPFEM. To capitalize on this insight, we propose a novel spatial-temporal coherent correlation learning (STCCL) algorithm, which models the aforementioned correlations as explicit metrics and integrates the metrics to supervise manipulating facial expression and meanwhile better preserving the facial animation of spoken content. To this end, it first learns a spatial coherent correlation metric, ensuring that the visual correlations of adjacent local regions within an image linked to a specific emotion closely resemble those of corresponding regions in an image linked to a different emotion. Simultaneously, it develops a temporal coherent correlation metric, ensuring that the visual correlations of specific regions across adjacent image frames associated with one emotion are similar to those in the corresponding regions of frames associated with another emotion. Recognizing that visual correlations are not uniform across all regions, we have also crafted a correlation-aware adaptive strategy that prioritizes regions that present greater challenges. During SPFEM model training, we construct the spatial-temporal coherent correlation metric between corresponding local regions of the input and output image frames as an additional loss to supervise the generation process.
Neural Clothing Tryer: Customized Virtual Try-On via Semantic Enhancement and Controlling Diffusion Model
Jan 30, 2026This work aims to address a novel Customized Virtual Try-ON (Cu-VTON) task, enabling the superimposition of a specified garment onto a model that can be customized in terms of appearance, posture, and additional attributes. Compared with traditional VTON task, it enables users to tailor digital avatars to their individual preferences, thereby enhancing the virtual fitting experience with greater flexibility and engagement. To address this task, we introduce a Neural Clothing Tryer (NCT) framework, which exploits the advanced diffusion models equipped with semantic enhancement and controlling modules to better preserve semantic characterization and textural details of the garment and meanwhile facilitating the flexible editing of the model's postures and appearances. Specifically, NCT introduces a semantic-enhanced module to take semantic descriptions of garments and utilizes a visual-language encoder to learn aligned features across modalities. The aligned features are served as condition input to the diffusion model to enhance the preservation of the garment's semantics. Then, a semantic controlling module is designed to take the garment image, tailored posture image, and semantic description as input to maintain garment details while simultaneously editing model postures, expressions, and various attributes. Extensive experiments on the open available benchmark demonstrate the superior performance of the proposed NCT framework.
Exploring Talking Head Models With Adjacent Frame Prior for Speech-Preserving Facial Expression Manipulation
Jan 19, 2026Speech-Preserving Facial Expression Manipulation (SPFEM) is an innovative technique aimed at altering facial expressions in images and videos while retaining the original mouth movements. Despite advancements, SPFEM still struggles with accurate lip synchronization due to the complex interplay between facial expressions and mouth shapes. Capitalizing on the advanced capabilities of audio-driven talking head generation (AD-THG) models in synthesizing precise lip movements, our research introduces a novel integration of these models with SPFEM. We present a new framework, Talking Head Facial Expression Manipulation (THFEM), which utilizes AD-THG models to generate frames with accurately synchronized lip movements from audio inputs and SPFEM-altered images. However, increasing the number of frames generated by AD-THG models tends to compromise the realism and expression fidelity of the images. To counter this, we develop an adjacent frame learning strategy that finetunes AD-THG models to predict sequences of consecutive frames. This strategy enables the models to incorporate information from neighboring frames, significantly improving image quality during testing. Our extensive experimental evaluations demonstrate that this framework effectively preserves mouth shapes during expression manipulations, highlighting the substantial benefits of integrating AD-THG with SPFEM.
Geometry-Editable and Appearance-Preserving Object Compositon
May 27, 2025General object composition (GOC) aims to seamlessly integrate a target object into a background scene with desired geometric properties, while simultaneously preserving its fine-grained appearance details. Recent approaches derive semantic embeddings and integrate them into advanced diffusion models to enable geometry-editable generation. However, these highly compact embeddings encode only high-level semantic cues and inevitably discard fine-grained appearance details. We introduce a Disentangled Geometry-editable and Appearance-preserving Diffusion (DGAD) model that first leverages semantic embeddings to implicitly capture the desired geometric transformations and then employs a cross-attention retrieval mechanism to align fine-grained appearance features with the geometry-edited representation, facilitating both precise geometry editing and faithful appearance preservation in object composition. Specifically, DGAD builds on CLIP/DINO-derived and reference networks to extract semantic embeddings and appearance-preserving representations, which are then seamlessly integrated into the encoding and decoding pipelines in a disentangled manner. We first integrate the semantic embeddings into pre-trained diffusion models that exhibit strong spatial reasoning capabilities to implicitly capture object geometry, thereby facilitating flexible object manipulation and ensuring effective editability. Then, we design a dense cross-attention mechanism that leverages the implicitly learned object geometry to retrieve and spatially align appearance features with their corresponding regions, ensuring faithful appearance consistency. Extensive experiments on public benchmarks demonstrate the effectiveness of the proposed DGAD framework.
Contrastive Decoupled Representation Learning and Regularization for Speech-Preserving Facial Expression Manipulation
Apr 08, 2025Speech-preserving facial expression manipulation (SPFEM) aims to modify a talking head to display a specific reference emotion while preserving the mouth animation of source spoken contents. Thus, emotion and content information existing in reference and source inputs can provide direct and accurate supervision signals for SPFEM models. However, the intrinsic intertwining of these elements during the talking process poses challenges to their effectiveness as supervisory signals. In this work, we propose to learn content and emotion priors as guidance augmented with contrastive learning to learn decoupled content and emotion representation via an innovative Contrastive Decoupled Representation Learning (CDRL) algorithm. Specifically, a Contrastive Content Representation Learning (CCRL) module is designed to learn audio feature, which primarily contains content information, as content priors to guide learning content representation from the source input. Meanwhile, a Contrastive Emotion Representation Learning (CERL) module is proposed to make use of a pre-trained visual-language model to learn emotion prior, which is then used to guide learning emotion representation from the reference input. We further introduce emotion-aware and emotion-augmented contrastive learning to train CCRL and CERL modules, respectively, ensuring learning emotion-independent content representation and content-independent emotion representation. During SPFEM model training, the decoupled content and emotion representations are used to supervise the generation process, ensuring more accurate emotion manipulation together with audio-lip synchronization. Extensive experiments and evaluations on various benchmarks show the effectiveness of the proposed algorithm.
Exploiting Temporal Audio-Visual Correlation Embedding for Audio-Driven One-Shot Talking Head Animation
Apr 08, 2025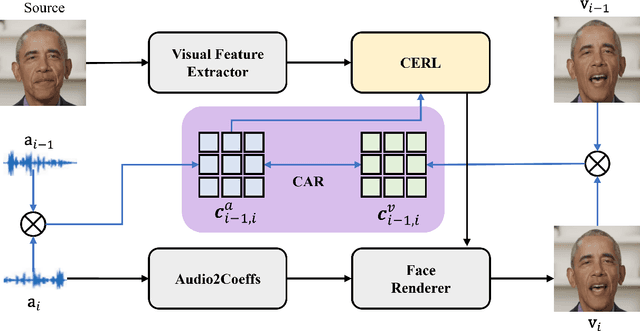
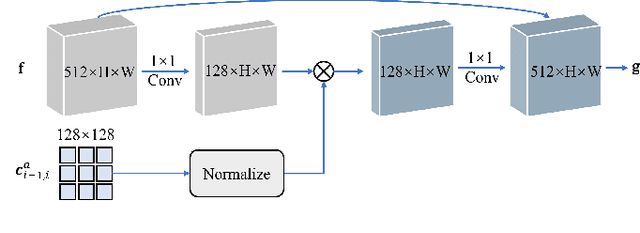
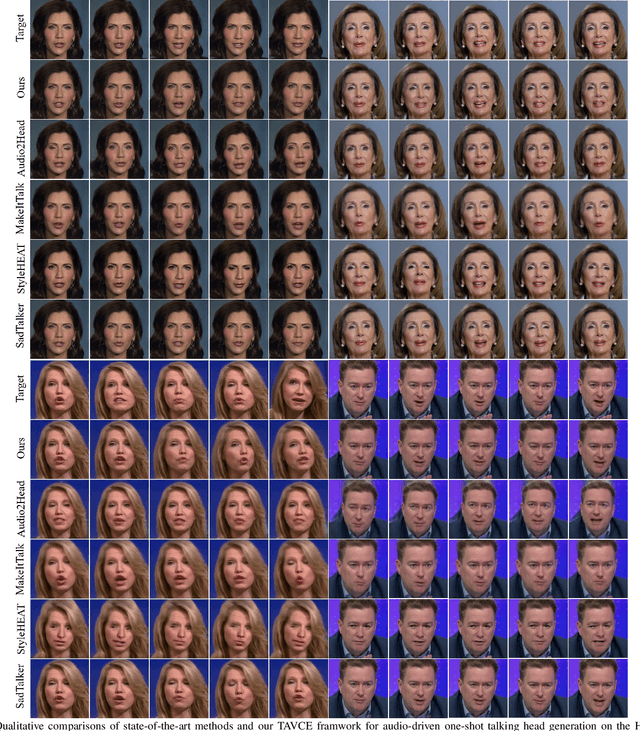

The paramount challenge in audio-driven One-shot Talking Head Animation (ADOS-THA) lies in capturing subtle imperceptible changes between adjacent video frames. Inherently, the temporal relationship of adjacent audio clips is highly correlated with that of the corresponding adjacent video frames, offering supplementary information that can be pivotal for guiding and supervising talking head animations. In this work, we propose to learn audio-visual correlations and integrate the correlations to help enhance feature representation and regularize final generation by a novel Temporal Audio-Visual Correlation Embedding (TAVCE) framework. Specifically, it first learns an audio-visual temporal correlation metric, ensuring the temporal audio relationships of adjacent clips are aligned with the temporal visual relationships of corresponding adjacent video frames. Since the temporal audio relationship contains aligned information about the visual frame, we first integrate it to guide learning more representative features via a simple yet effective channel attention mechanism. During training, we also use the alignment correlations as an additional objective to supervise generating visual frames. We conduct extensive experiments on several publicly available benchmarks (i.e., HDTF, LRW, VoxCeleb1, and VoxCeleb2) to demonstrate its superiority over existing leading algorithms.
GVTNet: Graph Vision Transformer For Face Super-Resolution
Feb 18, 2025



Recent advances in face super-resolution research have utilized the Transformer architecture. This method processes the input image into a series of small patches. However, because of the strong correlation between different facial components in facial images. When it comes to super-resolution of low-resolution images, existing algorithms cannot handle the relationships between patches well, resulting in distorted facial components in the super-resolution results. To solve the problem, we propose a transformer architecture based on graph neural networks called graph vision transformer network. We treat each patch as a graph node and establish an adjacency matrix based on the information between patches. In this way, the patch only interacts between neighboring patches, further processing the relationship of facial components. Quantitative and visualization experiments have underscored the superiority of our algorithm over state-of-the-art techniques. Through detailed comparisons, we have demonstrated that our algorithm possesses more advanced super-resolution capabilities, particularly in enhancing facial components. The PyTorch code is available at https://github.com/continueyang/GVTNet
DeltaDiff: A Residual-Guided Diffusion Model for Enhanced Image Super-Resolution
Feb 18, 2025



Recently, the application of diffusion models in super-resolution tasks has become a popular research direction. Existing work is focused on fully migrating diffusion models to SR tasks. The diffusion model is proposed in the field of image generation, so in order to make the generated results diverse, the diffusion model combines random Gaussian noise and distributed sampling to increase the randomness of the model. However, the essence of super-resolution tasks requires the model to generate high-resolution images with fidelity. Excessive addition of random factors can result in the model generating detailed information that does not belong to the HR image. To address this issue, we propose a new diffusion model called Deltadiff, which uses only residuals between images for diffusion, making the entire diffusion process more stable. The experimental results show that our method surpasses state-of-the-art models and generates results with better fidelity. Our code and model are publicly available at https://github.com/continueyang/DeltaDiff
Adaptive Few-shot Prompting for Machine Translation with Pre-trained Language Models
Jan 03, 2025Recently, Large language models (LLMs) with in-context learning have demonstrated remarkable potential in handling neural machine translation. However, existing evidence shows that LLMs are prompt-sensitive and it is sub-optimal to apply the fixed prompt to any input for downstream machine translation tasks. To address this issue, we propose an adaptive few-shot prompting (AFSP) framework to automatically select suitable translation demonstrations for various source input sentences to further elicit the translation capability of an LLM for better machine translation. First, we build a translation demonstration retrieval module based on LLM's embedding to retrieve top-k semantic-similar translation demonstrations from aligned parallel translation corpus. Rather than using other embedding models for semantic demonstration retrieval, we build a hybrid demonstration retrieval module based on the embedding layer of the deployed LLM to build better input representation for retrieving more semantic-related translation demonstrations. Then, to ensure better semantic consistency between source inputs and target outputs, we force the deployed LLM itself to generate multiple output candidates in the target language with the help of translation demonstrations and rerank these candidates. Besides, to better evaluate the effectiveness of our AFSP framework on the latest language and extend the research boundary of neural machine translation, we construct a high-quality diplomatic Chinese-English parallel dataset that consists of 5,528 parallel Chinese-English sentences. Finally, extensive experiments on the proposed diplomatic Chinese-English parallel dataset and the United Nations Parallel Corpus (Chinese-English part) show the effectiveness and superiority of our proposed AFSP.