 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Clothing Tryer: Customized Virtual Try-On via Semantic Enhancement and Controlling Diffusion Model
Jan 30, 2026This work aims to address a novel Customized Virtual Try-ON (Cu-VTON) task, enabling the superimposition of a specified garment onto a model that can be customized in terms of appearance, posture, and additional attributes. Compared with traditional VTON task, it enables users to tailor digital avatars to their individual preferences, thereby enhancing the virtual fitting experience with greater flexibility and engagement. To address this task, we introduce a Neural Clothing Tryer (NCT) framework, which exploits the advanced diffusion models equipped with semantic enhancement and controlling modules to better preserve semantic characterization and textural details of the garment and meanwhile facilitating the flexible editing of the model's postures and appearances. Specifically, NCT introduces a semantic-enhanced module to take semantic descriptions of garments and utilizes a visual-language encoder to learn aligned features across modalities. The aligned features are served as condition input to the diffusion model to enhance the preservation of the garment's semantics. Then, a semantic controlling module is designed to take the garment image, tailored posture image, and semantic description as input to maintain garment details while simultaneously editing model postures, expressions, and various attributes. Extensive experiments on the open available benchmark demonstrate the superior performance of the proposed NCT framework.
Online Multi-level Contrastive Representation Distillation for Cross-Subject fNIRS Emotion Recognition
Sep 24, 2024Utilizing functional near-infrared spectroscopy (fNIRS) signals for emotion recognition is a significant advancement in understanding human emotions. However, due to the lack of artificial intelligence data and algorithms in this field, current research faces the following challenges: 1) The portable wearable devices have higher requirements for lightweight models; 2) The objective differences of physiology and psychology among different subjects aggravate the difficulty of emotion recognition. To address these challenges, we propose a novel cross-subject fNIRS emotion recognition method, called the Online Multi-level Contrastive Representation Distillation framework (OMCRD). Specifically, OMCRD is a framework designed for mutual learning among multiple lightweight student networks. It utilizes multi-level fNIRS feature extractor for each sub-network and conducts multi-view sentimental mining using physiological signals. The proposed Inter-Subject Interaction Contrastive Representation (IS-ICR) facilitates knowledge transfer for interactions between student models, enhancing cross-subject emotion recognition performance. The optimal student network can be selected and deployed on a wearable device. Some experimental results demonstrate that OMCRD achieves state-of-the-art results in emotional perception and affective imagery tasks.
Active Mining Sample Pair Semantics for Image-text Matching
Nov 09, 2023



Recently, commonsense learning has been a hot topic in image-text matching. Although it can describe more graphic correlations, commonsense learning still has some shortcomings: 1) The existing methods are based on triplet semantic similarity measurement loss, which cannot effectively match the intractable negative in image-text sample pairs. 2) The weak generalization ability of the model leads to the poor effect of image and text matching on large-scale datasets. According to these shortcomings. This paper proposes a novel image-text matching model, called Active Mining Sample Pair Semantics image-text matching model (AMSPS). Compared with the single semantic learning mode of the commonsense learning model with triplet loss function, AMSPS is an active learning idea. Firstly, the proposed Adaptive Hierarchical Reinforcement Loss (AHRL) has diversified learning modes. Its active learning mode enables the model to more focus on the intractable negative samples to enhance the discriminating ability. In addition, AMSPS can also adaptively mine more hidden relevant semantic representations from uncommented items, which greatly improves the performance and generalization ability of the model. Experimental results on Flickr30K and MSCOCO universal datasets show that our proposed method is superior to advanced comparison methods.
Robust Depth Linear Error Decomposition with Double Total Variation and Nuclear Norm for Dynamic MRI Reconstruction
Oct 23, 2023



Compressed Sensing (CS) significantly speeds up Magnetic Resonance Image (MRI) processing and achieves accurate MRI reconstruction from under-sampled k-space data. According to the current research, there are still several problems with dynamic MRI k-space reconstruction based on CS. 1) There are differences between the Fourier domain and the Image domain, and the differences between MRI processing of different domains need to be considered. 2) As three-dimensional data, dynamic MRI has its spatial-temporal characteristics, which need to calculate the difference and consistency of surface textures while preserving structural integrity and uniqueness. 3) Dynamic MRI reconstruction is time-consuming and computationally resource-dependent. In this paper, we propose a novel robust low-rank dynamic MRI reconstruction optimization model via highly under-sampled and Discrete Fourier Transform (DFT) called the Robust Depth Linear Error Decomposition Model (RDLEDM). Our method mainly includes linear decomposition, double Total Variation (TV), and double Nuclear Norm (NN) regularizations. By adding linear image domain error analysis, the noise is reduced after under-sampled and DFT processing, and the anti-interference ability of the algorithm is enhanced. Double TV and NN regularizations can utilize both spatial-temporal characteristics and explore the complementary relationship between different dimensions in dynamic MRI sequences. In addition, Due to the non-smoothness and non-convexity of TV and NN terms, it is difficult to optimize the unified objective model. To address this issue, we utilize a fast algorithm by solving a primal-dual form of the original problem. Compared with five state-of-the-art methods, extensive experiments on dynamic MRI data demonstrate the superior performance of the proposed method in terms of both reconstruction accuracy and time complexity.
Self-supervised Fetal MRI 3D Reconstruction Based on Radiation Diffusion Generation Model
Oct 16, 2023



Although the use of multiple stacks can handle slice-to-volume motion correction and artifact removal problems, there are still several problems: 1) The slice-to-volume method usually uses slices as input, which cannot solve the problem of uniform intensity distribution and complementarity in regions of different fetal MRI stacks; 2) The integrity of 3D space is not considered, which adversely affects the discrimination and generation of globally consistent information in fetal MRI; 3) Fetal MRI with severe motion artifacts in the real-world cannot achieve high-quality super-resolution reconstruction. To address these issues, we propose a novel fetal brain MRI high-quality volume reconstruction method, called the Radiation Diffusion Generation Model (RDGM). It is a self-supervised generation method, which incorporates the idea of Neural Radiation Field (NeRF) based on the coordinate generation and diffusion model based on super-resolution generation. To solve regional intensity heterogeneity in different directions, we use a pre-trained transformer model for slice registration, and then, a new regionally Consistent Implicit Neural Representation (CINR) network sub-module is proposed. CINR can generate the initial volume by combining a coordinate association map of two different coordinate mapping spaces. To enhance volume global consistency and discrimination, we introduce the Volume Diffusion Super-resolution Generation (VDSG) mechanism. The global intensity discriminant generation from volume-to-volume is carried out using the idea of diffusion generation, and CINR becomes the deviation intensity generation network of the volume-to-volume diffusion model. Finally, the experimental results on real-world fetal brain MRI stacks demonstrate the state-of-the-art performance of our method.
Superpoint Transformer for 3D Scene Instance Segmentation
Nov 28, 2022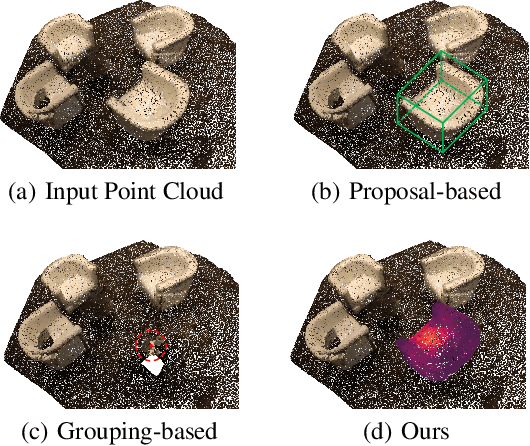
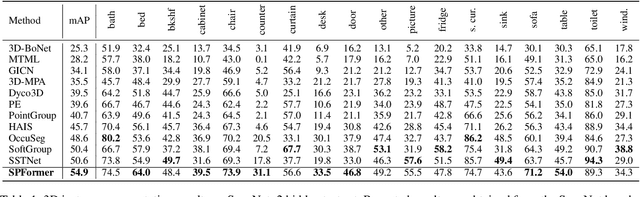
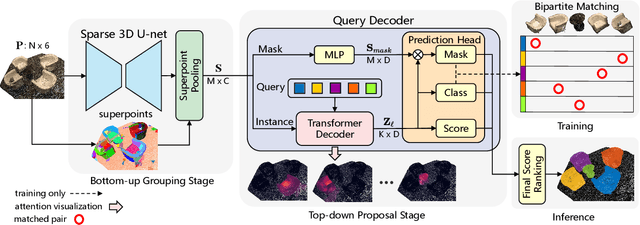
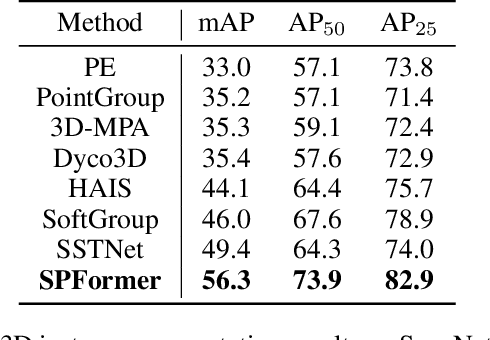
Most existing methods realize 3D instance segmentation by extending those models used for 3D object detection or 3D semantic segmentation. However, these non-straightforward methods suffer from two drawbacks: 1) Imprecise bounding boxes or unsatisfactory semantic predictions limit the performance of the overall 3D instance segmentation framework. 2) Existing method requires a time-consuming intermediate step of aggregation. To address these issues, this paper proposes a novel end-to-end 3D instance segmentation method based on Superpoint Transformer, named as SPFormer. It groups potential features from point clouds into superpoints, and directly predicts instances through query vectors without relying on the results of object detection or semantic segmentation. The key step in this framework is a novel query decoder with transformers that can capture the instance information through the superpoint cross-attention mechanism and generate the superpoint masks of the instances. Through bipartite matching based on superpoint masks, SPFormer can implement the network training without the intermediate aggregation step, which accelerates the network. Extensive experiments on ScanNetv2 and S3DIS benchmarks verify that our method is concise yet efficient. Notably, SPFormer exceeds compared state-of-the-art methods by 4.3% on ScanNetv2 hidden test set in terms of mAP and keeps fast inference speed (247ms per frame) simultaneously. Code is available at https://github.com/sunjiahao1999/SPFormer.
Unsupervised Multi-view Clustering by Squeezing Hybrid Knowledge from Cross View and Each View
Aug 23, 2020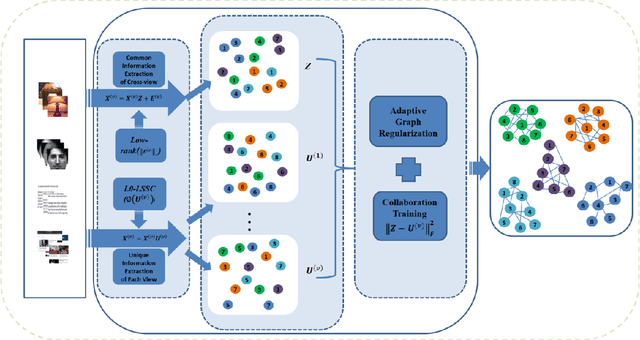
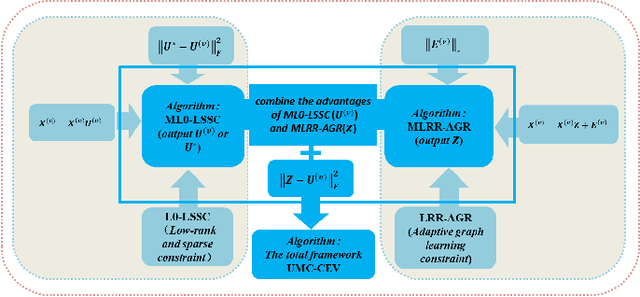
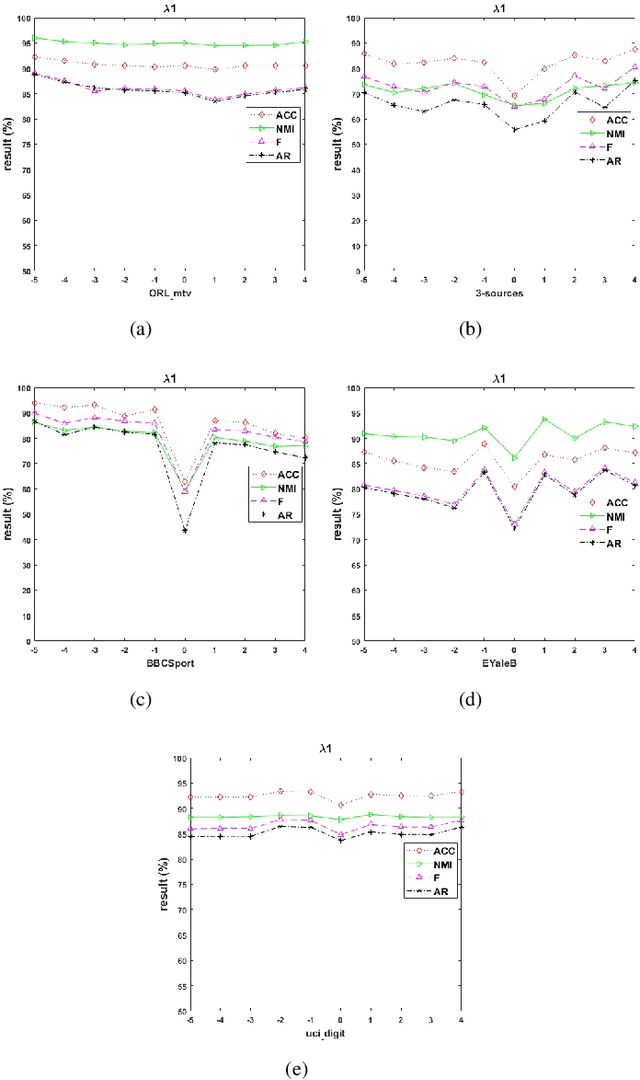
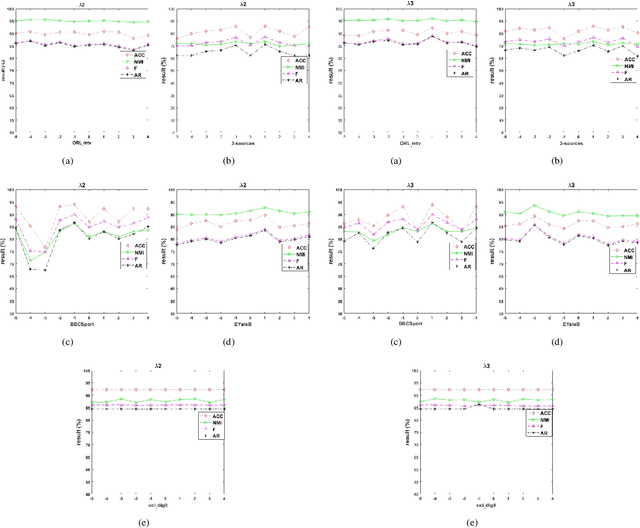
Multi-view clustering methods have been a focus in recent years because of their superiority in clustering performance. However, typical traditional multi-view clustering algorithms still have shortcomings in some aspects, such as removal of redundant information, utilization of various views and fusion of multi-view features. In view of these problems, this paper proposes a new multi-view clustering method, low-rank subspace multi-view clustering based on adaptive graph regularization. We construct two new data matrix decomposition models into a unified optimization model. In this framework, we address the significance of the common knowledge shared by the cross view and the unique knowledge of each view by presenting new low-rank and sparse constraints on the sparse subspace matrix. To ensure that we achieve effective sparse representation and clustering performance on the original data matrix, adaptive graph regularization and unsupervised clustering constraints are also incorporated in the proposed model to preserve the internal structural features of the data. Finally, the proposed method is compared with several state-of-the-art algorithms. Experimental results for five widely used multi-view benchmarks show that our proposed algorithm surpasses other state-of-the-art methods by a clear margin.