 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Cross-Modal Emotional Correlation Learning for Speech-Preserving Facial Expression Manipulation
Apr 28, 2026Speech-preserving facial expression manipulation (SPFEM) aims to enhance human expressiveness without altering mouth movements tied to the original speech. A primary challenge in this domain is the scarcity of paired data, namely aligned frames of the same individual with identical speech but different expressions, which impedes direct supervision for emotional manipulation. While current Visual-Language Models (VLMs) can extract aligned visual and semantic features, making them a promising source of supervision, their direct application is limited. To this end, we propose a Personalized Cross-Modal Emotional Correlation Learning (PCMECL) algorithm that refines VLM-based supervision through two major improvements. First, standard VLMs rely on a single generic prompt for each emotion, failing to capture expressive variations among individuals. PCMECL addresses this limitation by conditioning on individual visual information to learn personalized prompts, thereby establishing more fine-grained visual-semantic correlations. Second, even with personalization, inherent discrepancies persist between the visual and semantic feature distributions. To bridge this modality gap, PCMECL employs feature differencing to correlate the modalities, providing more precisely aligned supervision by matching the change in visual features to the change in semantic features. As a plug-and-play module, PCMECL can be seamlessly integrated into existing SPFEM models. Extensive experiments across various datasets demonstrate the superior efficacy of our algorithm.
Learning Spatial-Temporal Coherent Correlations for Speech-Preserving Facial Expression Manipulation
Apr 22, 2026Speech-preserving facial expression manipulation (SPFEM) aims to modify facial emotions while meticulously maintaining the mouth animation associated with spoken content. Current works depend on inaccessible paired training samples for the person, where two aligned frames exhibit the same speech content yet differ in emotional expression, limiting the SPFEM applications in real-world scenarios. In this work, we discover that speakers who convey the same content with different emotions exhibit highly correlated local facial animations in both spatial and temporal spaces, providing valuable supervision for SPFEM. To capitalize on this insight, we propose a novel spatial-temporal coherent correlation learning (STCCL) algorithm, which models the aforementioned correlations as explicit metrics and integrates the metrics to supervise manipulating facial expression and meanwhile better preserving the facial animation of spoken content. To this end, it first learns a spatial coherent correlation metric, ensuring that the visual correlations of adjacent local regions within an image linked to a specific emotion closely resemble those of corresponding regions in an image linked to a different emotion. Simultaneously, it develops a temporal coherent correlation metric, ensuring that the visual correlations of specific regions across adjacent image frames associated with one emotion are similar to those in the corresponding regions of frames associated with another emotion. Recognizing that visual correlations are not uniform across all regions, we have also crafted a correlation-aware adaptive strategy that prioritizes regions that present greater challenges. During SPFEM model training, we construct the spatial-temporal coherent correlation metric between corresponding local regions of the input and output image frames as an additional loss to supervise the generation process.
CoCo: Code as CoT for Text-to-Image Preview and Rare Concept Generation
Mar 09, 2026Recent advancements in Unified Multimodal Models (UMMs) have significantly advanced text-to-image (T2I) generation, particularly through the integration of Chain-of-Thought (CoT) reasoning. However, existing CoT-based T2I methods largely rely on abstract natural-language planning, which lacks the precision required for complex spatial layouts, structured visual elements, and dense textual content. In this work, we propose CoCo (Code-as-CoT), a code-driven reasoning framework that represents the reasoning process as executable code, enabling explicit and verifiable intermediate planning for image generation. Given a text prompt, CoCo first generates executable code that specifies the structural layout of the scene, which is then executed in a sandboxed environment to render a deterministic draft image. The model subsequently refines this draft through fine-grained image editing to produce the final high-fidelity result. To support this training paradigm, we construct CoCo-10K, a curated dataset containing structured draft-final image pairs designed to teach both structured draft construction and corrective visual refinement. Empirical evaluations on StructT2IBench, OneIG-Bench, and LongText-Bench show that CoCo achieves improvements of +68.83%, +54.8%, and +41.23% over direct generation, while also outperforming other generation methods empowered by CoT. These results demonstrate that executable code is an effective and reliable reasoning paradigm for precise, controllable, and structured text-to-image generation. The code is available at: https://github.com/micky-li-hd/CoCo
GEBench: Benchmarking Image Generation Models as GUI Environments
Feb 09, 2026Recent advancements in image generation models have enabled the prediction of future Graphical User Interface (GUI) states based on user instructions. However, existing benchmarks primarily focus on general domain visual fidelity, leaving the evaluation of state transitions and temporal coherence in GUI-specific contexts underexplored. To address this gap, we introduce GEBench, a comprehensive benchmark for evaluating dynamic interaction and temporal coherence in GUI generation. GEBench comprises 700 carefully curated samples spanning five task categories, covering both single-step interactions and multi-step trajectories across real-world and fictional scenarios, as well as grounding point localization. To support systematic evaluation, we propose GE-Score, a novel five-dimensional metric that assesses Goal Achievement, Interaction Logic, Content Consistency, UI Plausibility, and Visual Quality. Extensive evaluations on current models indicate that while they perform well on single-step transitions, they struggle significantly with maintaining temporal coherence and spatial grounding over longer interaction sequences. Our findings identify icon interpretation, text rendering, and localization precision as critical bottlenecks. This work provides a foundation for systematic assessment and suggests promising directions for future research toward building high-fidelity generative GUI environments. The code is available at: https://github.com/stepfun-ai/GEBench.
Geometry-Editable and Appearance-Preserving Object Compositon
May 27, 2025General object composition (GOC) aims to seamlessly integrate a target object into a background scene with desired geometric properties, while simultaneously preserving its fine-grained appearance details. Recent approaches derive semantic embeddings and integrate them into advanced diffusion models to enable geometry-editable generation. However, these highly compact embeddings encode only high-level semantic cues and inevitably discard fine-grained appearance details. We introduce a Disentangled Geometry-editable and Appearance-preserving Diffusion (DGAD) model that first leverages semantic embeddings to implicitly capture the desired geometric transformations and then employs a cross-attention retrieval mechanism to align fine-grained appearance features with the geometry-edited representation, facilitating both precise geometry editing and faithful appearance preservation in object composition. Specifically, DGAD builds on CLIP/DINO-derived and reference networks to extract semantic embeddings and appearance-preserving representations, which are then seamlessly integrated into the encoding and decoding pipelines in a disentangled manner. We first integrate the semantic embeddings into pre-trained diffusion models that exhibit strong spatial reasoning capabilities to implicitly capture object geometry, thereby facilitating flexible object manipulation and ensuring effective editability. Then, we design a dense cross-attention mechanism that leverages the implicitly learned object geometry to retrieve and spatially align appearance features with their corresponding regions, ensuring faithful appearance consistency. Extensive experiments on public benchmarks demonstrate the effectiveness of the proposed DGAD framework.
Online Multi-level Contrastive Representation Distillation for Cross-Subject fNIRS Emotion Recognition
Sep 24, 2024Utilizing functional near-infrared spectroscopy (fNIRS) signals for emotion recognition is a significant advancement in understanding human emotions. However, due to the lack of artificial intelligence data and algorithms in this field, current research faces the following challenges: 1) The portable wearable devices have higher requirements for lightweight models; 2) The objective differences of physiology and psychology among different subjects aggravate the difficulty of emotion recognition. To address these challenges, we propose a novel cross-subject fNIRS emotion recognition method, called the Online Multi-level Contrastive Representation Distillation framework (OMCRD). Specifically, OMCRD is a framework designed for mutual learning among multiple lightweight student networks. It utilizes multi-level fNIRS feature extractor for each sub-network and conducts multi-view sentimental mining using physiological signals. The proposed Inter-Subject Interaction Contrastive Representation (IS-ICR) facilitates knowledge transfer for interactions between student models, enhancing cross-subject emotion recognition performance. The optimal student network can be selected and deployed on a wearable device. Some experimental results demonstrate that OMCRD achieves state-of-the-art results in emotional perception and affective imagery tasks.
An Empirical Study of Training State-of-the-Art LiDAR Segmentation Models
May 23, 2024In the rapidly evolving field of autonomous driving, precise segmentation of LiDAR data is crucial for understanding complex 3D environments. Traditional approaches often rely on disparate, standalone codebases, hindering unified advancements and fair benchmarking across models. To address these challenges, we introduce MMDetection3D-lidarseg, a comprehensive toolbox designed for the efficient training and evaluation of state-of-the-art LiDAR segmentation models. We support a wide range of segmentation models and integrate advanced data augmentation techniques to enhance robustness and generalization. Additionally, the toolbox provides support for multiple leading sparse convolution backends, optimizing computational efficiency and performance. By fostering a unified framework, MMDetection3D-lidarseg streamlines development and benchmarking, setting new standards for research and application. Our extensive benchmark experiments on widely-used datasets demonstrate the effectiveness of the toolbox. The codebase and trained models have been publicly available, promoting further research and innovation in the field of LiDAR segmentation for autonomous driving.
Robust Depth Linear Error Decomposition with Double Total Variation and Nuclear Norm for Dynamic MRI Reconstruction
Oct 23, 2023



Compressed Sensing (CS) significantly speeds up Magnetic Resonance Image (MRI) processing and achieves accurate MRI reconstruction from under-sampled k-space data. According to the current research, there are still several problems with dynamic MRI k-space reconstruction based on CS. 1) There are differences between the Fourier domain and the Image domain, and the differences between MRI processing of different domains need to be considered. 2) As three-dimensional data, dynamic MRI has its spatial-temporal characteristics, which need to calculate the difference and consistency of surface textures while preserving structural integrity and uniqueness. 3) Dynamic MRI reconstruction is time-consuming and computationally resource-dependent. In this paper, we propose a novel robust low-rank dynamic MRI reconstruction optimization model via highly under-sampled and Discrete Fourier Transform (DFT) called the Robust Depth Linear Error Decomposition Model (RDLEDM). Our method mainly includes linear decomposition, double Total Variation (TV), and double Nuclear Norm (NN) regularizations. By adding linear image domain error analysis, the noise is reduced after under-sampled and DFT processing, and the anti-interference ability of the algorithm is enhanced. Double TV and NN regularizations can utilize both spatial-temporal characteristics and explore the complementary relationship between different dimensions in dynamic MRI sequences. In addition, Due to the non-smoothness and non-convexity of TV and NN terms, it is difficult to optimize the unified objective model. To address this issue, we utilize a fast algorithm by solving a primal-dual form of the original problem. Compared with five state-of-the-art methods, extensive experiments on dynamic MRI data demonstrate the superior performance of the proposed method in terms of both reconstruction accuracy and time complexity.
Superpoint Transformer for 3D Scene Instance Segmentation
Nov 28, 2022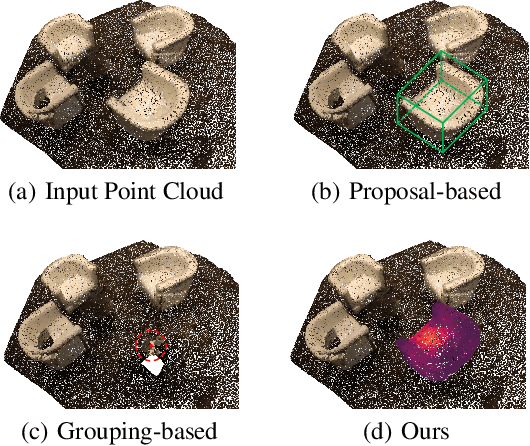
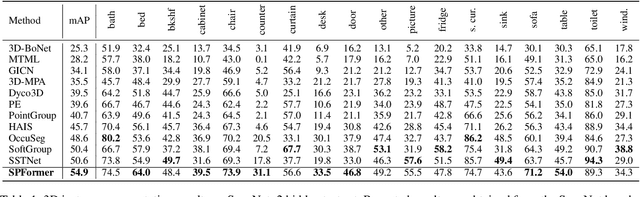
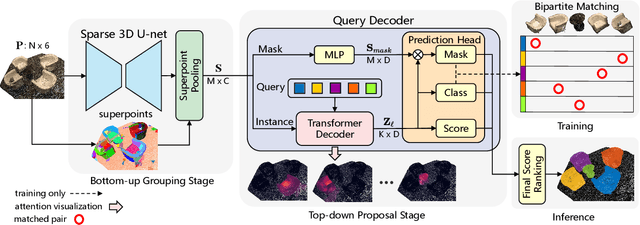
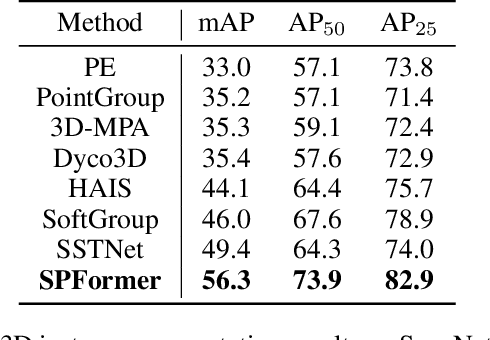
Most existing methods realize 3D instance segmentation by extending those models used for 3D object detection or 3D semantic segmentation. However, these non-straightforward methods suffer from two drawbacks: 1) Imprecise bounding boxes or unsatisfactory semantic predictions limit the performance of the overall 3D instance segmentation framework. 2) Existing method requires a time-consuming intermediate step of aggregation. To address these issues, this paper proposes a novel end-to-end 3D instance segmentation method based on Superpoint Transformer, named as SPFormer. It groups potential features from point clouds into superpoints, and directly predicts instances through query vectors without relying on the results of object detection or semantic segmentation. The key step in this framework is a novel query decoder with transformers that can capture the instance information through the superpoint cross-attention mechanism and generate the superpoint masks of the instances. Through bipartite matching based on superpoint masks, SPFormer can implement the network training without the intermediate aggregation step, which accelerates the network. Extensive experiments on ScanNetv2 and S3DIS benchmarks verify that our method is concise yet efficient. Notably, SPFormer exceeds compared state-of-the-art methods by 4.3% on ScanNetv2 hidden test set in terms of mAP and keeps fast inference speed (247ms per frame) simultaneously. Code is available at https://github.com/sunjiahao1999/SPFormer.
DehazeNet: An End-to-End System for Single Image Haze Removal
May 17, 2016Single image haze removal is a challenging ill-posed problem. Existing methods use various constraints/priors to get plausible dehazing solutions. The key to achieve haze removal is to estimate a medium transmission map for an input hazy image. In this paper, we propose a trainable end-to-end system called DehazeNet, for medium transmission estimation. DehazeNet takes a hazy image as input, and outputs its medium transmission map that is subsequently used to recover a haze-free image via atmospheric scattering model. DehazeNet adopts Convolutional Neural Networks (CNN) based deep architecture, whose layers are specially designed to embody the established assumptions/priors in image dehazing. Specifically, layers of Maxout units are used for feature extraction, which can generate almost all haze-relevant features. We also propose a novel nonlinear activation function in DehazeNet, called Bilateral Rectified Linear Unit (BReLU), which is able to improve the quality of recovered haze-free image. We establish connections between components of the proposed DehazeNet and those used in existing methods. Experiments on benchmark images show that DehazeNet achieves superior performance over existing methods, yet keeps efficient and easy to use.