 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrTalk: Correlation Between Hierarchical Speech and Facial Activity Variances for 3D Animation
Oct 17, 2023



Speech-driven 3D facial animation is a challenging cross-modal task that has attracted growing research interest. During speaking activities, the mouth displays strong motions, while the other facial regions typically demonstrate comparatively weak activity levels. Existing approaches often simplify the process by directly mapping single-level speech features to the entire facial animation, which overlook the differences in facial activity intensity leading to overly smoothed facial movements. In this study, we propose a novel framework, CorrTalk, which effectively establishes the temporal correlation between hierarchical speech features and facial activities of different intensities across distinct regions. A novel facial activity intensity metric is defined to distinguish between strong and weak facial activity, obtained by computing the short-time Fourier transform of facial vertex displacements. Based on the variances in facial activity, we propose a dual-branch decoding framework to synchronously synthesize strong and weak facial activity, which guarantees wider intensity facial animation synthesis. Furthermore, a weighted hierarchical feature encoder is proposed to establish temporal correlation between hierarchical speech features and facial activity at different intensities, which ensures lip-sync and plausible facial expressions. Extensive qualitatively and quantitatively experiments as well as a user study indicate that our CorrTalk outperforms existing state-of-the-art methods. The source code and supplementary video are publicly available at: https://zjchu.github.io/projects/CorrTalk/
Center Contrastive Loss for Metric Learning
Aug 01, 2023Contrastive learning is a major studied topic in metric learning. However, sampling effective contrastive pairs remains a challenge due to factors such as limited batch size, imbalanced data distribution, and the risk of overfitting. In this paper, we propose a novel metric learning function called Center Contrastive Loss, which maintains a class-wise center bank and compares the category centers with the query data points using a contrastive loss. The center bank is updated in real-time to boost model convergence without the need for well-designed sample mining. The category centers are well-optimized classification proxies to re-balance the supervisory signal of each class. Furthermore, the proposed loss combines the advantages of both contrastive and classification methods by reducing intra-class variations and enhancing inter-class differences to improve the discriminative power of embeddings. Our experimental results, as shown in Figure 1, demonstrate that a standard network (ResNet50) trained with our loss achieves state-of-the-art performance and faster convergence.
UniMoCo: Unsupervised, Semi-Supervised and Full-Supervised Visual Representation Learning
Mar 19, 2021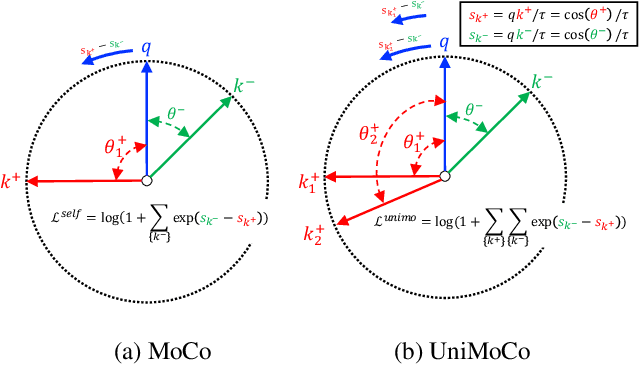
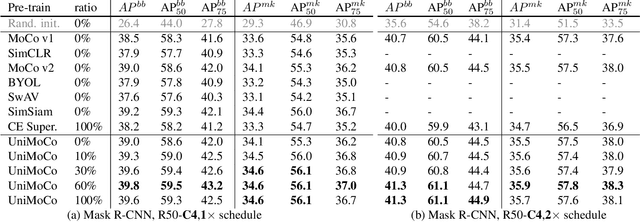
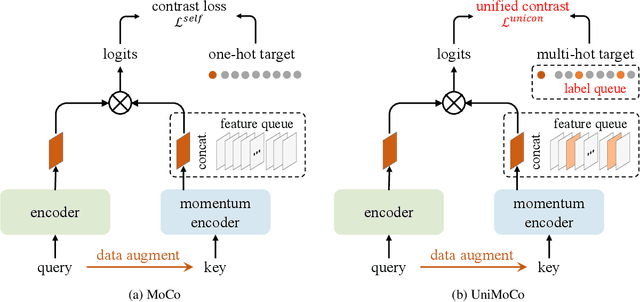
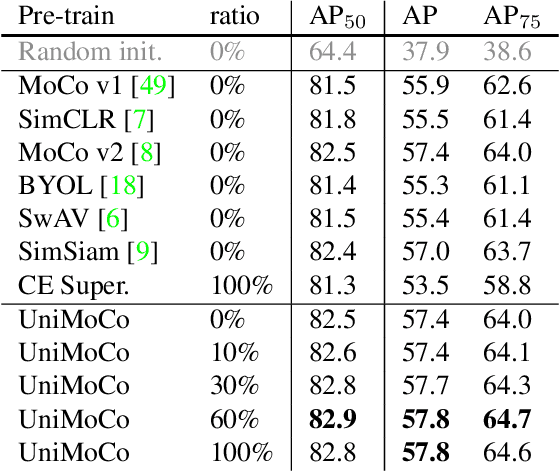
Momentum Contrast (MoCo) achieves great success for unsupervised visual representation. However, there are a lot of supervised and semi-supervised datasets, which are already labeled. To fully utilize the label annotations, we propose Unified Momentum Contrast (UniMoCo), which extends MoCo to support arbitrary ratios of labeled data and unlabeled data training. Compared with MoCo, UniMoCo has two modifications as follows: (1) Different from a single positive pair in MoCo, we maintain multiple positive pairs on-the-fly by comparing the query label to a label queue. (2) We propose a Unified Contrastive(UniCon) loss to support an arbitrary number of positives and negatives in a unified pair-wise optimization perspective. Our UniCon is more reasonable and powerful than the supervised contrastive loss in theory and practice. In our experiments, we pre-train multiple UniMoCo models with different ratios of ImageNet labels and evaluate the performance on various downstream tasks. Experiment results show that UniMoCo generalizes well for unsupervised, semi-supervised and supervised visual representation learning.
UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
Nov 18, 2020
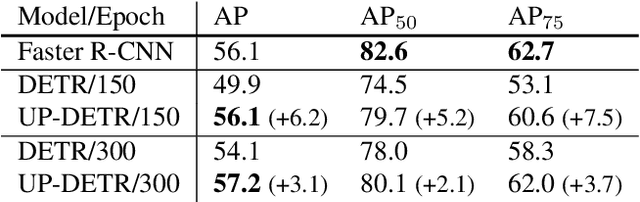
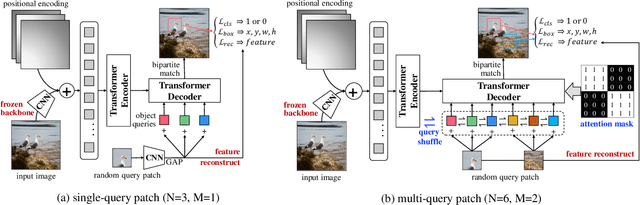
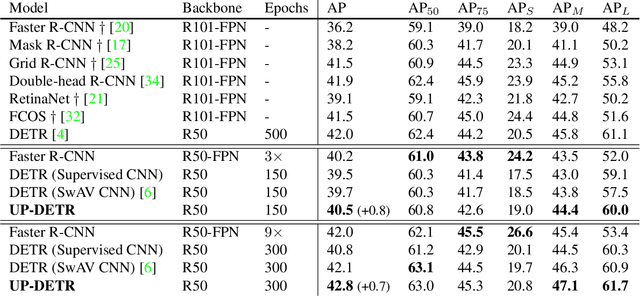
Object detection with transformers (DETR) reaches competitive performance with Faster R-CNN via a transformer encoder-decoder architecture. Inspired by the great success of pre-training transformers in natural language processing, we propose a pretext task named random query patch detection to unsupervisedly pre-train DETR (UP-DETR) for object detection. Specifically, we randomly crop patches from the given image and then feed them as queries to the decoder. The model is pre-trained to detect these query patches from the original image. During the pre-training, we address two critical issues: multi-task learning and multi-query localization. (1) To trade-off multi-task learning of classification and localization in the pretext task, we freeze the CNN backbone and propose a patch feature reconstruction branch which is jointly optimized with patch detection. (2) To perform multi-query localization, we introduce UP-DETR from single-query patch and extend it to multi-query patches with object query shuffle and attention mask. In our experiments, UP-DETR significantly boosts the performance of DETR with faster convergence and higher precision on PASCAL VOC and COCO datasets. The code will be available soon.
Listwise View Ranking for Image Cropping
May 14, 2019

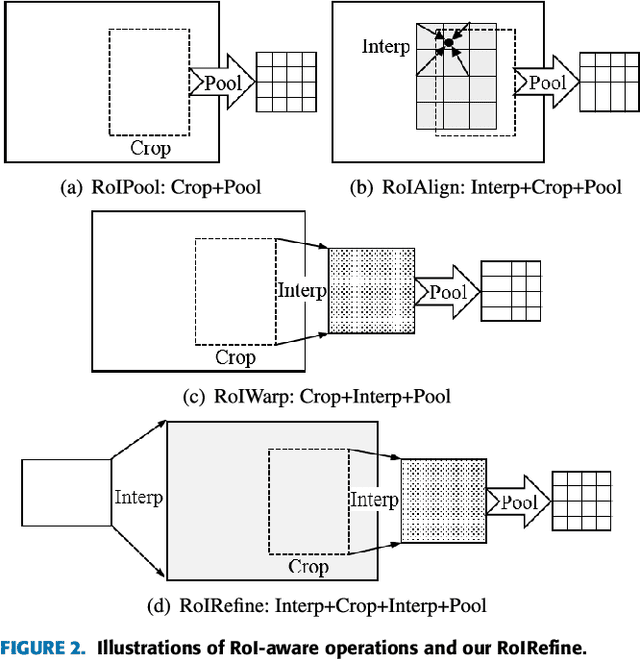
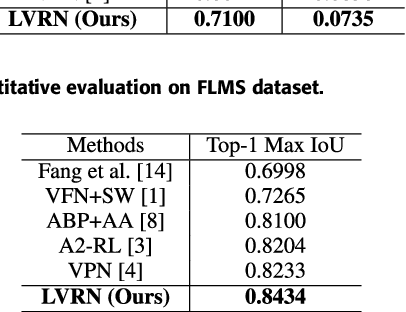
Rank-based Learning with deep neural network has been widely used for image cropping. However, the performance of ranking-based methods is often poor and this is mainly due to two reasons: 1) image cropping is a listwise ranking task rather than pairwise comparison; 2) the rescaling caused by pooling layer and the deformation in view generation damage the performance of composition learning. In this paper, we develop a novel model to overcome these problems. To address the first problem, we formulate the image cropping as a listwise ranking problem to find the best view composition. For the second problem, a refined view sampling (called RoIRefine) is proposed to extract refined feature maps for candidate view generation. Given a series of candidate views, the proposed model learns the Top-1 probability distribution of views and picks up the best one. By integrating refined sampling and listwise ranking, the proposed network called LVRN achieves the state-of-the-art performance both in accuracy and speed.
BIT: Biologically Inspired Tracker
Apr 23, 2019

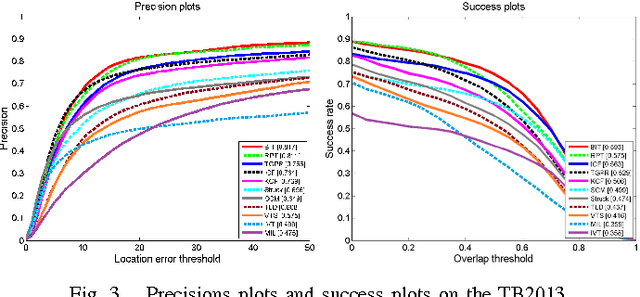

Visual tracking is challenging due to image variations caused by various factors, such as object deformation, scale change, illumination change and occlusion. Given the superior tracking performance of human visual system (HVS), an ideal design of biologically inspired model is expected to improve computer visual tracking. This is however a difficult task due to the incomplete understanding of neurons' working mechanism in HVS. This paper aims to address this challenge based on the analysis of visual cognitive mechanism of the ventral stream in the visual cortex, which simulates shallow neurons (S1 units and C1 units) to extract low-level biologically inspired features for the target appearance and imitates an advanced learning mechanism (S2 units and C2 units) to combine generative and discriminative models for target location. In addition, fast Gabor approximation (FGA) and fast Fourier transform (FFT) are adopted for real-time learning and detection in this framework. Extensive experiments on large-scale benchmark datasets show that the proposed biologically inspired tracker performs favorably against state-of-the-art methods in terms of efficiency, accuracy, and robustness. The acceleration technique in particular ensures that BIT maintains a speed of approximately 45 frames per second.
Deep Sampling Networks
Mar 26, 2018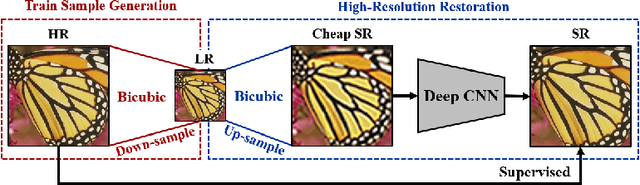
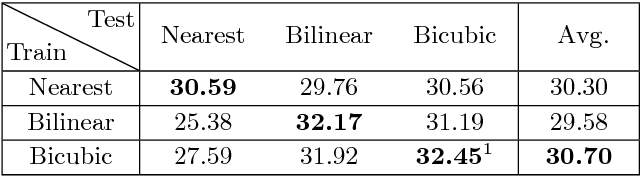
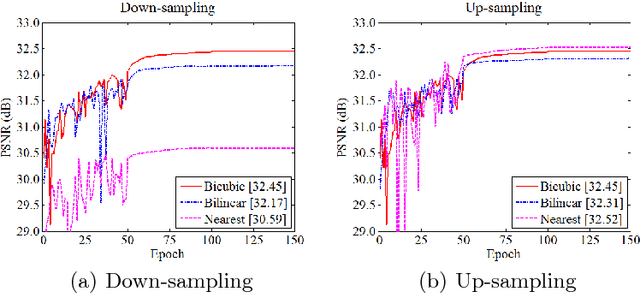
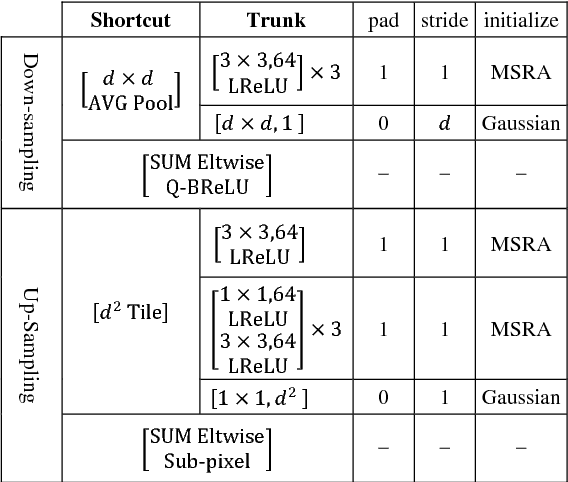
Deep convolutional neural networks achieve excellent image up-sampling performance. However, CNN-based methods tend to restore high-resolution results highly depending on traditional interpolations (e.g. bicubic). In this paper, we present a deep sampling network (DSN) for down-sampling and up-sampling without any cheap interpolation. First, the down-sampling subnetwork is trained without supervision, thereby preserving more information and producing better visual effects in the low-resolution image. Second, the up-sampling subnetwork learns a sub-pixel residual with dense connections to accelerate convergence and improve performance. DSN's down-sampling subnetwork can be used to generate photo-realistic low-resolution images and replace traditional down-sampling method in image processing. With the powerful down-sampling process, the co-training DSN set a new state-of-the-art performance for image super-resolution. Moreover, DSN is compatible with existing image codecs to improve image compression.
FReLU: Flexible Rectified Linear Units for Improving Convolutional Neural Networks
Jan 29, 2018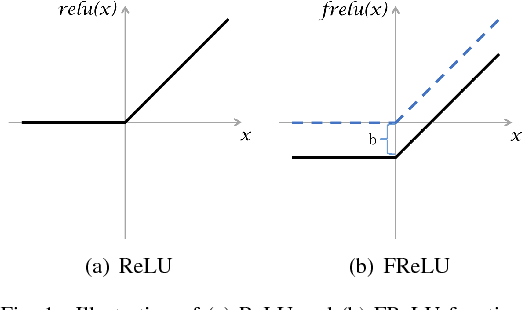
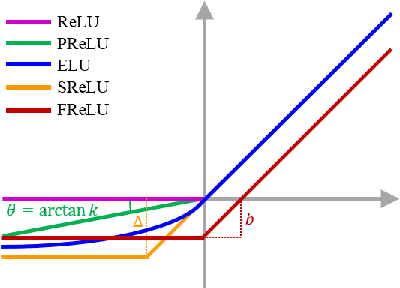

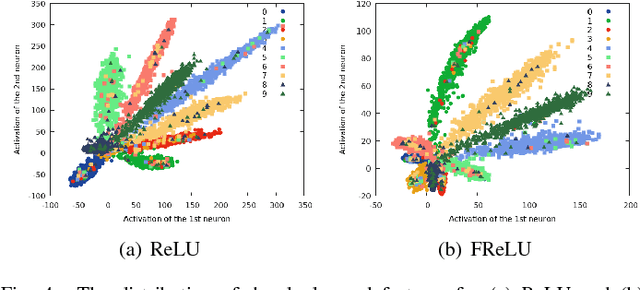
Rectified linear unit (ReLU) is a widely used activation function for deep convolutional neural networks. However, because of the zero-hard rectification, ReLU networks miss the benefits from negative values. In this paper, we propose a novel activation function called \emph{flexible rectified linear unit (FReLU)} to further explore the effects of negative values. By redesigning the rectified point of ReLU as a learnable parameter, FReLU expands the states of the activation output. When the network is successfully trained, FReLU tends to converge to a negative value, which improves the expressiveness and thus the performance. Furthermore, FReLU is designed to be simple and effective without exponential functions to maintain low cost computation. For being able to easily used in various network architectures, FReLU does not rely on strict assumptions by self-adaption. We evaluate FReLU on three standard image classification datasets, including CIFAR-10, CIFAR-100, and ImageNet. Experimental results show that the proposed method achieves fast convergence and higher performances on both plain and residual networks.
Single Image Super-Resolution Using Multi-Scale Convolutional Neural Network
May 15, 2017


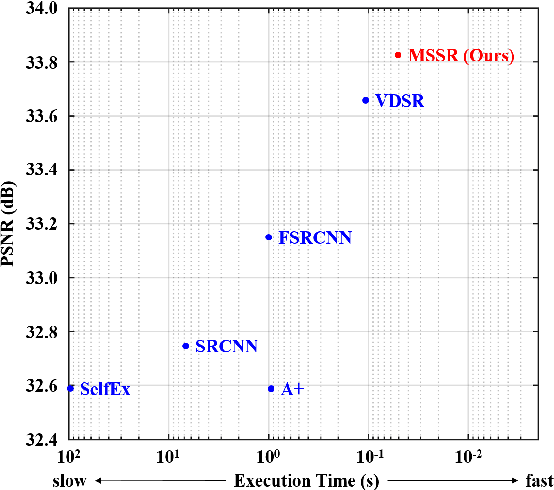
Methods based on convolutional neural network (CNN) have demonstrated tremendous improvements on single image super-resolution. However, the previous methods mainly restore images from one single area in the low resolution (LR) input, which limits the flexibility of models to infer various scales of details for high resolution (HR) output. Moreover, most of them train a specific model for each up-scale factor. In this paper, we propose a multi-scale super resolution (MSSR) network. Our network consists of multi-scale paths to make the HR inference, which can learn to synthesize features from different scales. This property helps reconstruct various kinds of regions in HR images. In addition, only one single model is needed for multiple up-scale factors, which is more efficient without loss of restoration quality. Experiments on four public datasets demonstrate that the proposed method achieved state-of-the-art performance with fast speed.
Multi-scale Convolutional Neural Networks for Crowd Counting
Feb 08, 2017
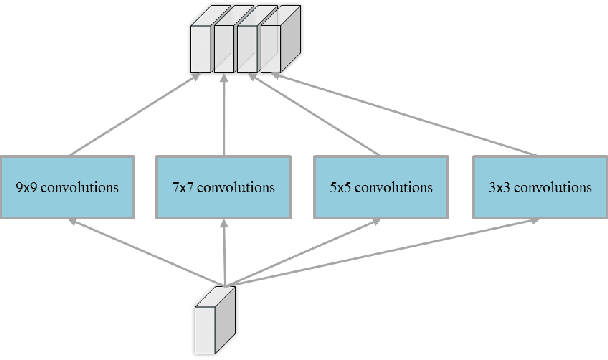

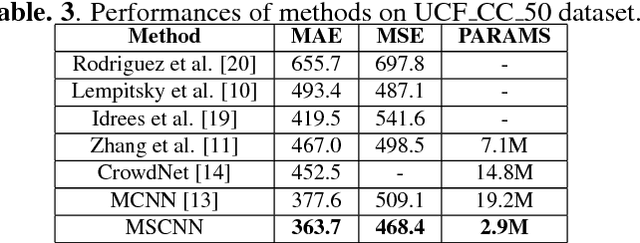
Crowd counting on static images is a challenging problem due to scale variations. Recently deep neural networks have been shown to be effective in this task. However, existing neural-networks-based methods often use the multi-column or multi-network model to extract the scale-relevant features, which is more complicated for optimization and computation wasting. To this end, we propose a novel multi-scale convolutional neural network (MSCNN) for single image crowd counting. Based on the multi-scale blobs, the network is able to generate scale-relevant features for higher crowd counting performances in a single-column architecture, which is both accuracy and cost effective for practical applications. Complemental results show that our method outperforms the state-of-the-art methods on both accuracy and robustness with far less number of parameters.