 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFReLU: Flexible Rectified Linear Units for Improving Convolutional Neural Networks
Paper and Code
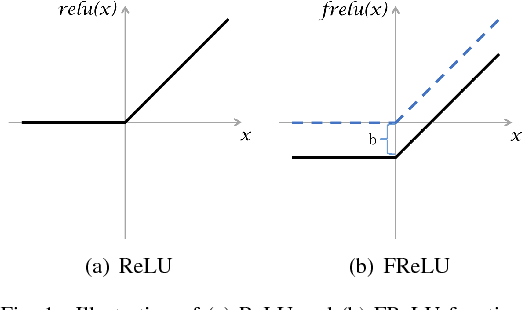
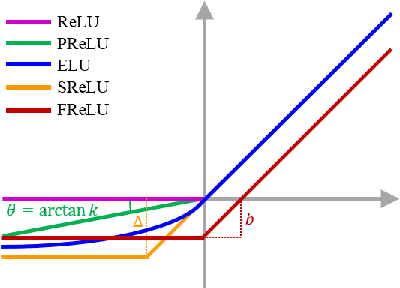

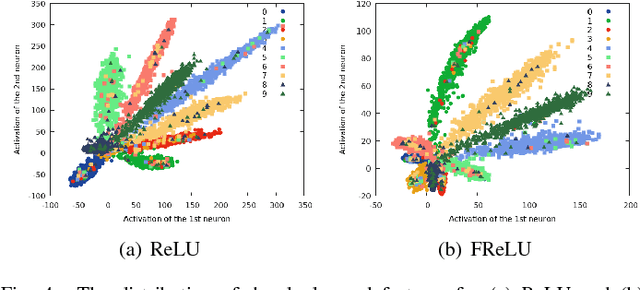
Rectified linear unit (ReLU) is a widely used activation function for deep convolutional neural networks. However, because of the zero-hard rectification, ReLU networks miss the benefits from negative values. In this paper, we propose a novel activation function called \emph{flexible rectified linear unit (FReLU)} to further explore the effects of negative values. By redesigning the rectified point of ReLU as a learnable parameter, FReLU expands the states of the activation output. When the network is successfully trained, FReLU tends to converge to a negative value, which improves the expressiveness and thus the performance. Furthermore, FReLU is designed to be simple and effective without exponential functions to maintain low cost computation. For being able to easily used in various network architectures, FReLU does not rely on strict assumptions by self-adaption. We evaluate FReLU on three standard image classification datasets, including CIFAR-10, CIFAR-100, and ImageNet. Experimental results show that the proposed method achieves fast convergence and higher performances on both plain and residual networks.