 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Center FPGA Acceleration Platform for Convolutional Neural Networks
Sep 17, 2019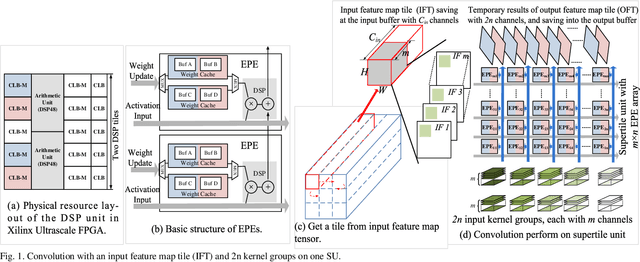
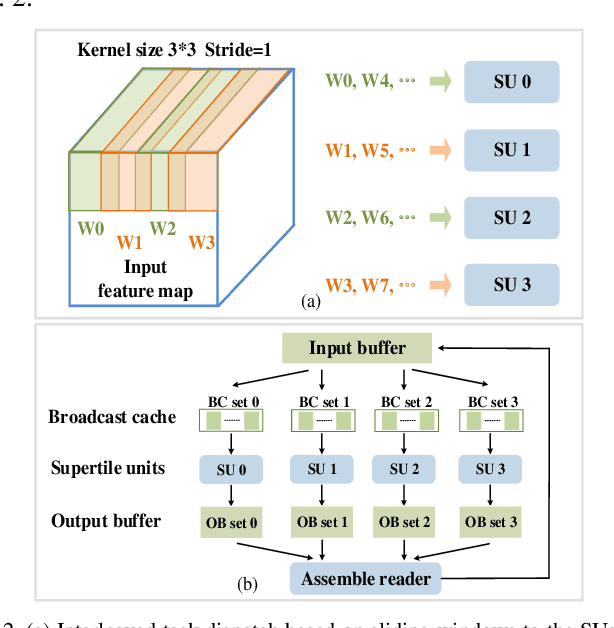
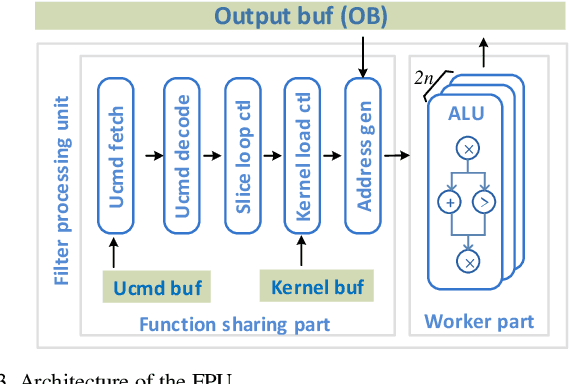
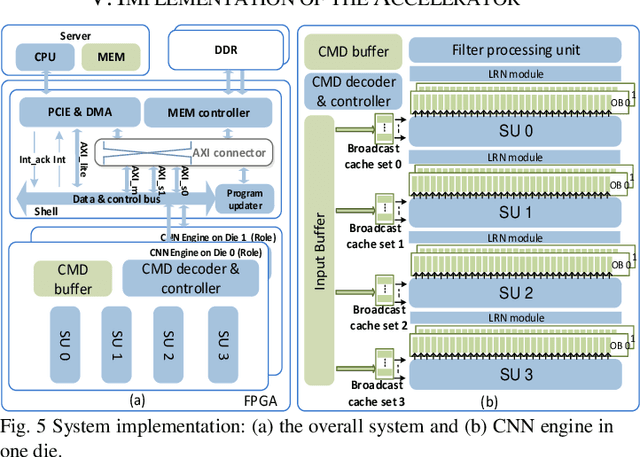
Intensive computation is entering data centers with multiple workloads of deep learning. To balance the compute efficiency, performance, and total cost of ownership (TCO), the use of a field-programmable gate array (FPGA) with reconfigurable logic provides an acceptable acceleration capacity and is compatible with diverse computation-sensitive tasks in the cloud. In this paper, we develop an FPGA acceleration platform that leverages a unified framework architecture for general-purpose convolutional neural network (CNN) inference acceleration at a data center. To overcome the computation bound, 4,096 DSPs are assembled and shaped as supertile units (SUs) for different types of convolution, which provide up to 4.2 TOP/s 16-bit fixed-point performance at 500 MHz. The interleaved-task-dispatching method is proposed to map the computation across the SUs, and the memory bound is solved by a dispatching-assembling buffering model and broadcast caches. For various non-convolution operators, a filter processing unit is designed for general-purpose filter-like/pointwise operators. In the experiment, the performances of CNN models running on server-class CPUs, a GPU, and an FPGA are compared. The results show that our design achieves the best FPGA peak performance and a throughput at the same level as that of the state-of-the-art GPU in data centers, with more than 50 times lower latency.
BIT: Biologically Inspired Tracker
Apr 23, 2019

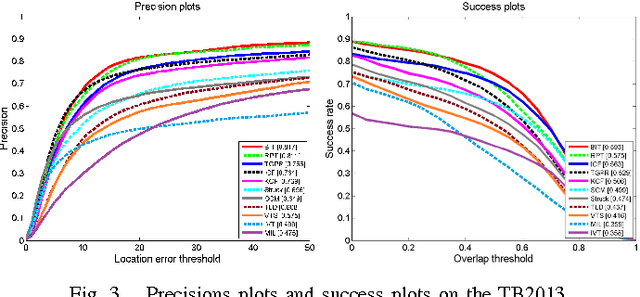

Visual tracking is challenging due to image variations caused by various factors, such as object deformation, scale change, illumination change and occlusion. Given the superior tracking performance of human visual system (HVS), an ideal design of biologically inspired model is expected to improve computer visual tracking. This is however a difficult task due to the incomplete understanding of neurons' working mechanism in HVS. This paper aims to address this challenge based on the analysis of visual cognitive mechanism of the ventral stream in the visual cortex, which simulates shallow neurons (S1 units and C1 units) to extract low-level biologically inspired features for the target appearance and imitates an advanced learning mechanism (S2 units and C2 units) to combine generative and discriminative models for target location. In addition, fast Gabor approximation (FGA) and fast Fourier transform (FFT) are adopted for real-time learning and detection in this framework. Extensive experiments on large-scale benchmark datasets show that the proposed biologically inspired tracker performs favorably against state-of-the-art methods in terms of efficiency, accuracy, and robustness. The acceleration technique in particular ensures that BIT maintains a speed of approximately 45 frames per second.
Manifold Regularized Slow Feature Analysis for Dynamic Texture Recognition
Jun 09, 2017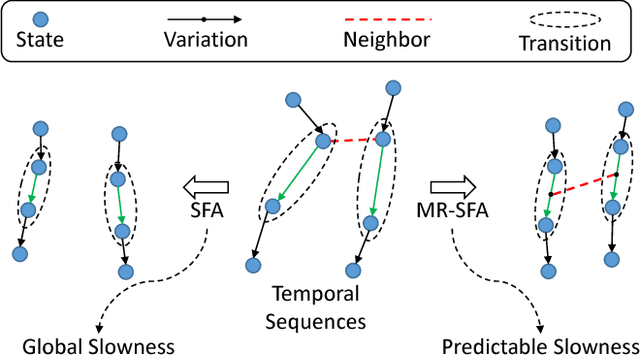
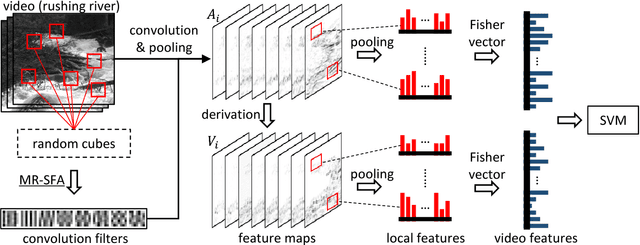


Dynamic textures exist in various forms, e.g., fire, smoke, and traffic jams, but recognizing dynamic texture is challenging due to the complex temporal variations. In this paper, we present a novel approach stemmed from slow feature analysis (SFA) for dynamic texture recognition. SFA extracts slowly varying features from fast varying signals. Fortunately, SFA is capable to leach invariant representations from dynamic textures. However, complex temporal variations require high-level semantic representations to fully achieve temporal slowness, and thus it is impractical to learn a high-level representation from dynamic textures directly by SFA. In order to learn a robust low-level feature to resolve the complexity of dynamic textures, we propose manifold regularized SFA (MR-SFA) by exploring the neighbor relationship of the initial state of each temporal transition and retaining the locality of their variations. Therefore, the learned features are not only slowly varying, but also partly predictable. MR-SFA for dynamic texture recognition is proposed in the following steps: 1) learning feature extraction functions as convolution filters by MR-SFA, 2) extracting local features by convolution and pooling, and 3) employing Fisher vectors to form a video-level representation for classification. Experimental results on dynamic texture and dynamic scene recognition datasets validate the effectiveness of the proposed approach.