 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Accurate Integer Transformer Machine-Translation Models
Jan 03, 2020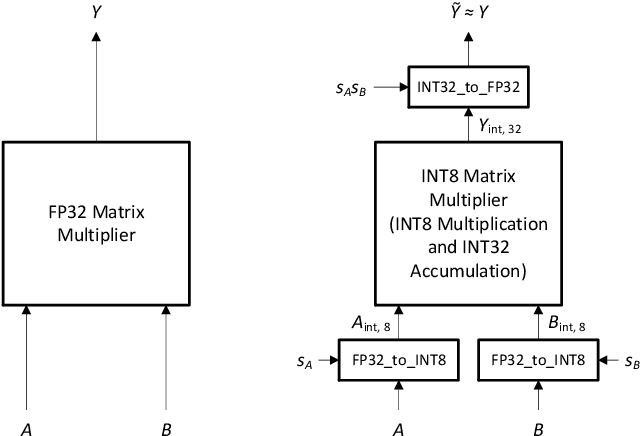
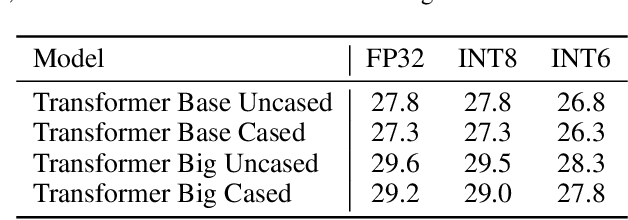

We describe a method for training accurate Transformer machine-translation models to run inference using 8-bit integer (INT8) hardware matrix multipliers, as opposed to the more costly single-precision floating-point (FP32) hardware. Unlike previous work, which converted only 85 Transformer matrix multiplications to INT8, leaving 48 out of 133 of them in FP32 because of unacceptable accuracy loss, we convert them all to INT8 without compromising accuracy. Tested on the newstest2014 English-to-German translation task, our INT8 Transformer Base and Transformer Big models yield BLEU scores that are 99.3% to 100% relative to those of the corresponding FP32 models. Our approach converts all matrix-multiplication tensors from an existing FP32 model into INT8 tensors by automatically making range-precision trade-offs during training. To demonstrate the robustness of this approach, we also include results from INT6 Transformer models.
MLPerf Inference Benchmark
Nov 06, 2019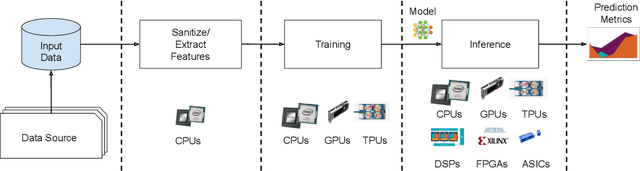
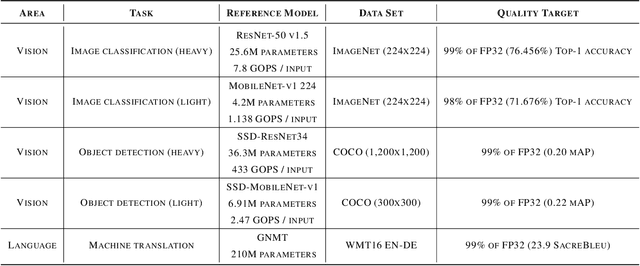
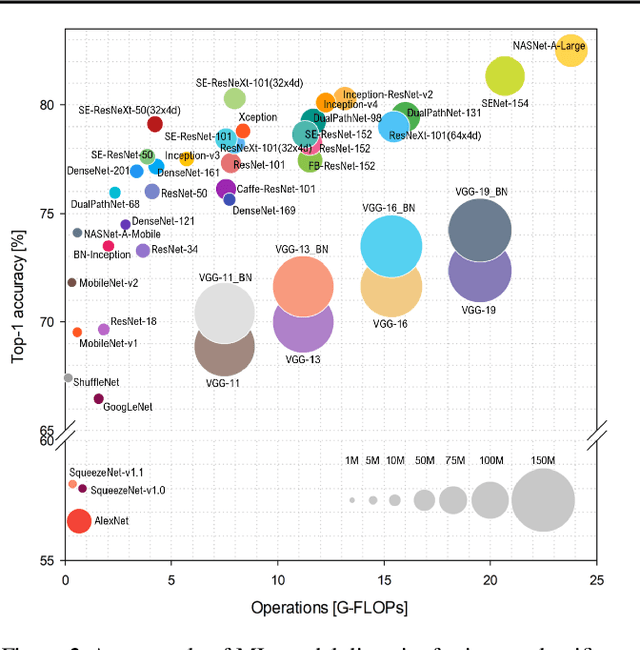
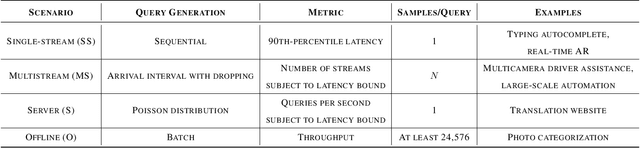
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.
A Data-Center FPGA Acceleration Platform for Convolutional Neural Networks
Sep 17, 2019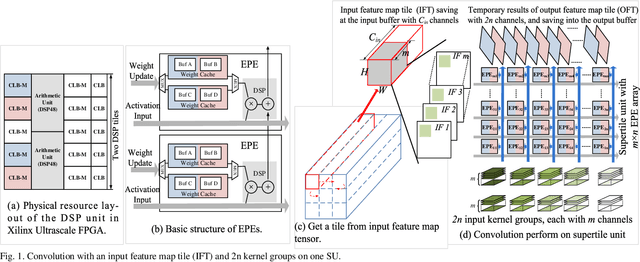
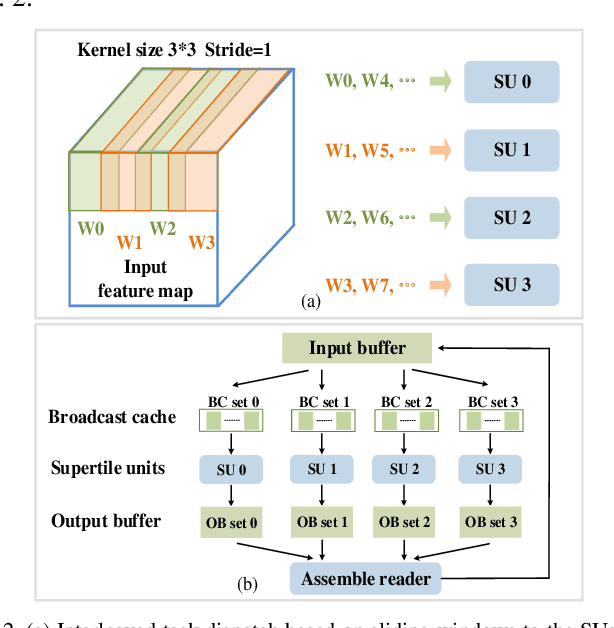
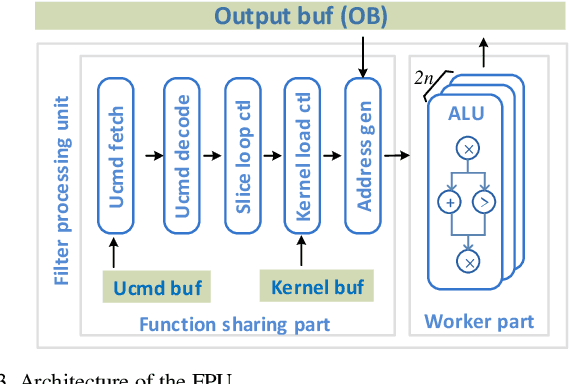
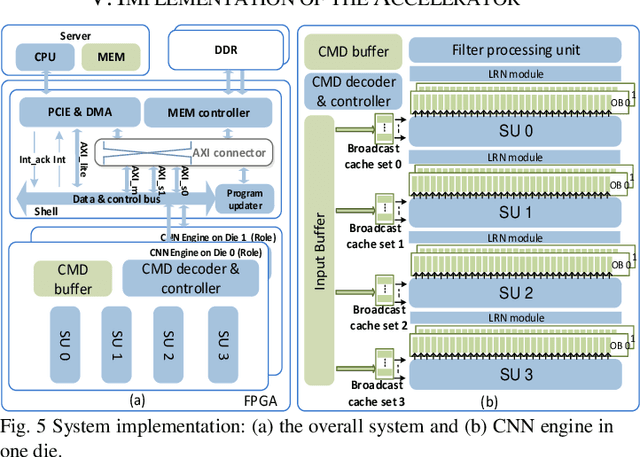
Intensive computation is entering data centers with multiple workloads of deep learning. To balance the compute efficiency, performance, and total cost of ownership (TCO), the use of a field-programmable gate array (FPGA) with reconfigurable logic provides an acceptable acceleration capacity and is compatible with diverse computation-sensitive tasks in the cloud. In this paper, we develop an FPGA acceleration platform that leverages a unified framework architecture for general-purpose convolutional neural network (CNN) inference acceleration at a data center. To overcome the computation bound, 4,096 DSPs are assembled and shaped as supertile units (SUs) for different types of convolution, which provide up to 4.2 TOP/s 16-bit fixed-point performance at 500 MHz. The interleaved-task-dispatching method is proposed to map the computation across the SUs, and the memory bound is solved by a dispatching-assembling buffering model and broadcast caches. For various non-convolution operators, a filter processing unit is designed for general-purpose filter-like/pointwise operators. In the experiment, the performances of CNN models running on server-class CPUs, a GPU, and an FPGA are compared. The results show that our design achieves the best FPGA peak performance and a throughput at the same level as that of the state-of-the-art GPU in data centers, with more than 50 times lower latency.