 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Accurate Integer Transformer Machine-Translation Models
Paper and Code
Jan 03, 2020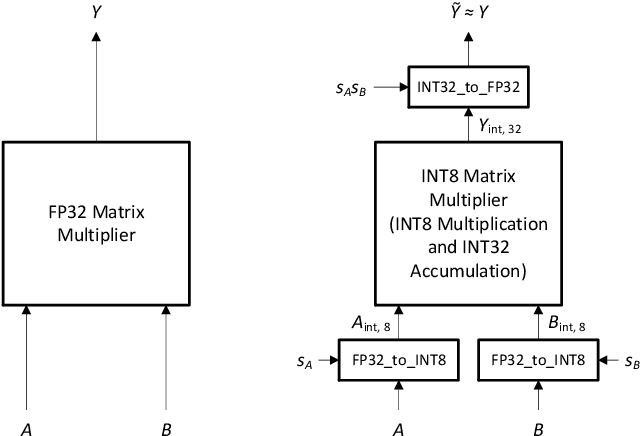
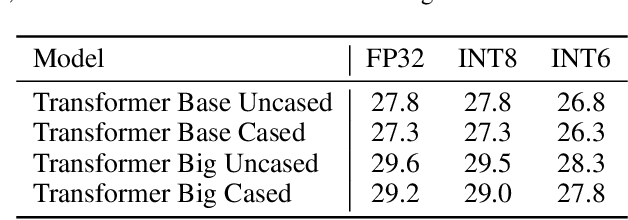
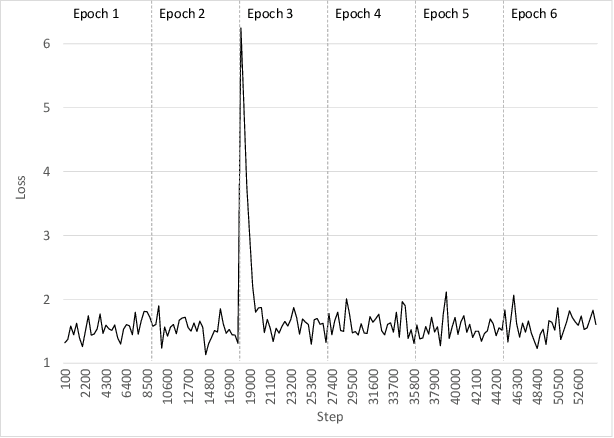

We describe a method for training accurate Transformer machine-translation models to run inference using 8-bit integer (INT8) hardware matrix multipliers, as opposed to the more costly single-precision floating-point (FP32) hardware. Unlike previous work, which converted only 85 Transformer matrix multiplications to INT8, leaving 48 out of 133 of them in FP32 because of unacceptable accuracy loss, we convert them all to INT8 without compromising accuracy. Tested on the newstest2014 English-to-German translation task, our INT8 Transformer Base and Transformer Big models yield BLEU scores that are 99.3% to 100% relative to those of the corresponding FP32 models. Our approach converts all matrix-multiplication tensors from an existing FP32 model into INT8 tensors by automatically making range-precision trade-offs during training. To demonstrate the robustness of this approach, we also include results from INT6 Transformer models.