 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniMoCo: Unsupervised, Semi-Supervised and Full-Supervised Visual Representation Learning
Mar 19, 2021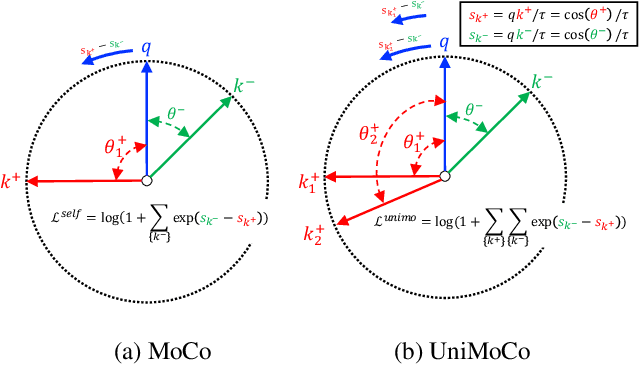
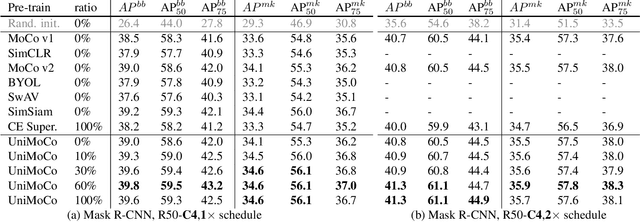
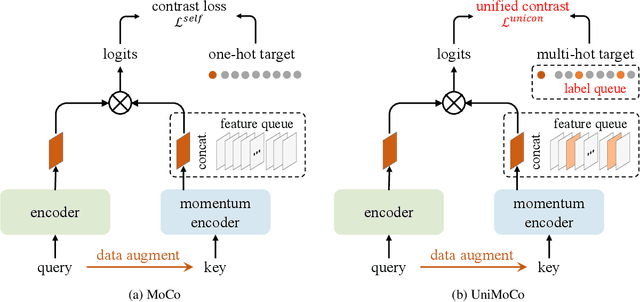
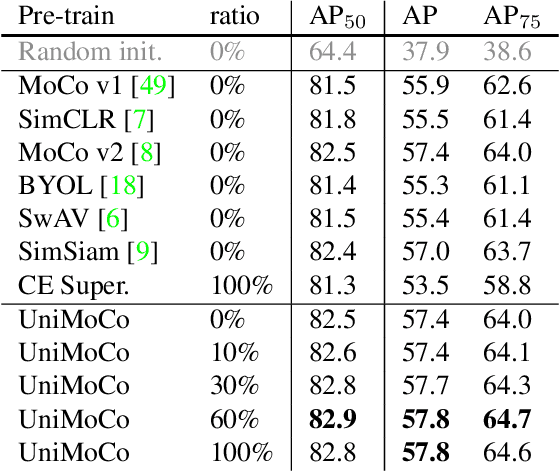
Momentum Contrast (MoCo) achieves great success for unsupervised visual representation. However, there are a lot of supervised and semi-supervised datasets, which are already labeled. To fully utilize the label annotations, we propose Unified Momentum Contrast (UniMoCo), which extends MoCo to support arbitrary ratios of labeled data and unlabeled data training. Compared with MoCo, UniMoCo has two modifications as follows: (1) Different from a single positive pair in MoCo, we maintain multiple positive pairs on-the-fly by comparing the query label to a label queue. (2) We propose a Unified Contrastive(UniCon) loss to support an arbitrary number of positives and negatives in a unified pair-wise optimization perspective. Our UniCon is more reasonable and powerful than the supervised contrastive loss in theory and practice. In our experiments, we pre-train multiple UniMoCo models with different ratios of ImageNet labels and evaluate the performance on various downstream tasks. Experiment results show that UniMoCo generalizes well for unsupervised, semi-supervised and supervised visual representation learning.
UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
Nov 18, 2020
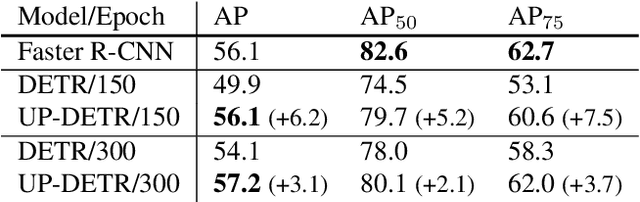
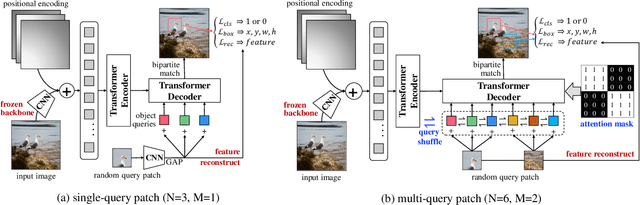
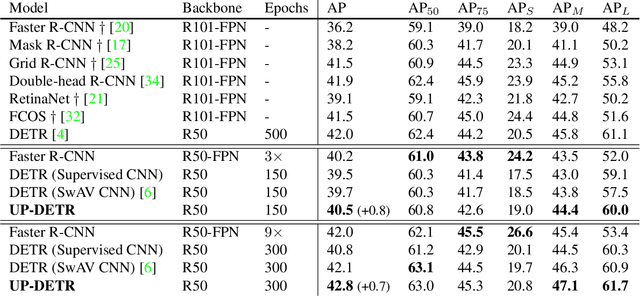
Object detection with transformers (DETR) reaches competitive performance with Faster R-CNN via a transformer encoder-decoder architecture. Inspired by the great success of pre-training transformers in natural language processing, we propose a pretext task named random query patch detection to unsupervisedly pre-train DETR (UP-DETR) for object detection. Specifically, we randomly crop patches from the given image and then feed them as queries to the decoder. The model is pre-trained to detect these query patches from the original image. During the pre-training, we address two critical issues: multi-task learning and multi-query localization. (1) To trade-off multi-task learning of classification and localization in the pretext task, we freeze the CNN backbone and propose a patch feature reconstruction branch which is jointly optimized with patch detection. (2) To perform multi-query localization, we introduce UP-DETR from single-query patch and extend it to multi-query patches with object query shuffle and attention mask. In our experiments, UP-DETR significantly boosts the performance of DETR with faster convergence and higher precision on PASCAL VOC and COCO datasets. The code will be available soon.
3rd Place Solution to "Google Landmark Retrieval 2020"
Aug 25, 2020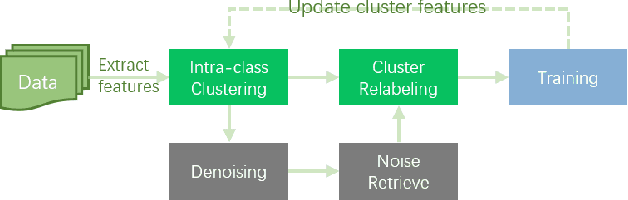
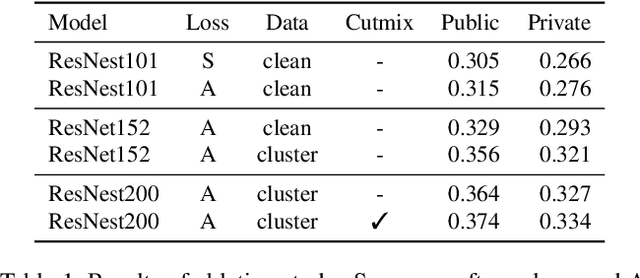

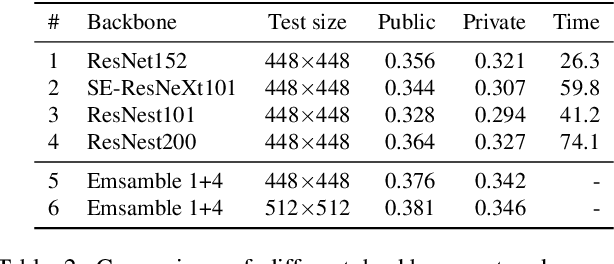
Image retrieval is a fundamental problem in computer vision. This paper presents our 3rd place detailed solution to the Google Landmark Retrieval 2020 challenge. We focus on the exploration of data cleaning and models with metric learning. We use a data cleaning strategy based on embedding clustering. Besides, we employ a data augmentation method called Corner-Cutmix, which improves the model's ability to recognize multi-scale and occluded landmark images. We show in detail the ablation experiments and results of our method.