 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: Benchmarking Vision-Language-Action Generalization via Real-World Dynamics, Spatial-Physical Intelligence, and Autonomous Evaluation
Feb 11, 2026VLA models have achieved remarkable progress in embodied intelligence; however, their evaluation remains largely confined to simulations or highly constrained real-world settings. This mismatch creates a substantial reality gap, where strong benchmark performance often masks poor generalization in diverse physical environments. We identify three systemic shortcomings in current benchmarking practices that hinder fair and reliable model comparison. (1) Existing benchmarks fail to model real-world dynamics, overlooking critical factors such as dynamic object configurations, robot initial states, lighting changes, and sensor noise. (2) Current protocols neglect spatial--physical intelligence, reducing evaluation to rote manipulation tasks that do not probe geometric reasoning. (3) The field lacks scalable fully autonomous evaluation, instead relying on simplistic 2D metrics that miss 3D spatial structure or on human-in-the-loop systems that are costly, biased, and unscalable. To address these limitations, we introduce RADAR (Real-world Autonomous Dynamics And Reasoning), a benchmark designed to systematically evaluate VLA generalization under realistic conditions. RADAR integrates three core components: (1) a principled suite of physical dynamics; (2) dedicated tasks that explicitly test spatial reasoning and physical understanding; and (3) a fully autonomous evaluation pipeline based on 3D metrics, eliminating the need for human supervision. We apply RADAR to audit multiple state-of-the-art VLA models and uncover severe fragility beneath their apparent competence. Performance drops precipitously under modest physical dynamics, with the expectation of 3D IoU declining from 0.261 to 0.068 under sensor noise. Moreover, models exhibit limited spatial reasoning capability. These findings position RADAR as a necessary bench toward reliable and generalizable real-world evaluation of VLA models.
Robust Egocentric Referring Video Object Segmentation via Dual-Modal Causal Intervention
Dec 30, 2025Egocentric Referring Video Object Segmentation (Ego-RVOS) aims to segment the specific object actively involved in a human action, as described by a language query, within first-person videos. This task is critical for understanding egocentric human behavior. However, achieving such segmentation robustly is challenging due to ambiguities inherent in egocentric videos and biases present in training data. Consequently, existing methods often struggle, learning spurious correlations from skewed object-action pairings in datasets and fundamental visual confounding factors of the egocentric perspective, such as rapid motion and frequent occlusions. To address these limitations, we introduce Causal Ego-REferring Segmentation (CERES), a plug-in causal framework that adapts strong, pre-trained RVOS backbones to the egocentric domain. CERES implements dual-modal causal intervention: applying backdoor adjustment principles to counteract language representation biases learned from dataset statistics, and leveraging front-door adjustment concepts to address visual confounding by intelligently integrating semantic visual features with geometric depth information guided by causal principles, creating representations more robust to egocentric distortions. Extensive experiments demonstrate that CERES achieves state-of-the-art performance on Ego-RVOS benchmarks, highlighting the potential of applying causal reasoning to build more reliable models for broader egocentric video understanding.
DART: Dual Adaptive Refinement Transfer for Open-Vocabulary Multi-Label Recognition
Aug 07, 2025Open-Vocabulary Multi-Label Recognition (OV-MLR) aims to identify multiple seen and unseen object categories within an image, requiring both precise intra-class localization to pinpoint objects and effective inter-class reasoning to model complex category dependencies. While Vision-Language Pre-training (VLP) models offer a strong open-vocabulary foundation, they often struggle with fine-grained localization under weak supervision and typically fail to explicitly leverage structured relational knowledge beyond basic semantics, limiting performance especially for unseen classes. To overcome these limitations, we propose the Dual Adaptive Refinement Transfer (DART) framework. DART enhances a frozen VLP backbone via two synergistic adaptive modules. For intra-class refinement, an Adaptive Refinement Module (ARM) refines patch features adaptively, coupled with a novel Weakly Supervised Patch Selecting (WPS) loss that enables discriminative localization using only image-level labels. Concurrently, for inter-class transfer, an Adaptive Transfer Module (ATM) leverages a Class Relationship Graph (CRG), constructed using structured knowledge mined from a Large Language Model (LLM), and employs graph attention network to adaptively transfer relational information between class representations. DART is the first framework, to our knowledge, to explicitly integrate external LLM-derived relational knowledge for adaptive inter-class transfer while simultaneously performing adaptive intra-class refinement under weak supervision for OV-MLR. Extensive experiments on challenging benchmarks demonstrate that our DART achieves new state-of-the-art performance, validating its effectiveness.
Category-Adaptive Cross-Modal Semantic Refinement and Transfer for Open-Vocabulary Multi-Label Recognition
Dec 09, 2024



Benefiting from the generalization capability of CLIP, recent vision language pre-training (VLP) models have demonstrated an impressive ability to capture virtually any visual concept in daily images. However, due to the presence of unseen categories in open-vocabulary settings, existing algorithms struggle to effectively capture strong semantic correlations between categories, resulting in sub-optimal performance on the open-vocabulary multi-label recognition (OV-MLR). Furthermore, the substantial variation in the number of discriminative areas across diverse object categories is misaligned with the fixed-number patch matching used in current methods, introducing noisy visual cues that hinder the accurate capture of target semantics. To tackle these challenges, we propose a novel category-adaptive cross-modal semantic refinement and transfer (C$^2$SRT) framework to explore the semantic correlation both within each category and across different categories, in a category-adaptive manner. The proposed framework consists of two complementary modules, i.e., intra-category semantic refinement (ISR) module and inter-category semantic transfer (IST) module. Specifically, the ISR module leverages the cross-modal knowledge of the VLP model to adaptively find a set of local discriminative regions that best represent the semantics of the target category. The IST module adaptively discovers a set of most correlated categories for a target category by utilizing the commonsense capabilities of LLMs to construct a category-adaptive correlation graph and transfers semantic knowledge from the correlated seen categories to unseen ones. Extensive experiments on OV-MLR benchmarks clearly demonstrate that the proposed C$^2$SRT framework outperforms current state-of-the-art algorithms.
Dynamic Correlation Learning and Regularization for Multi-Label Confidence Calibration
Jul 09, 2024Modern visual recognition models often display overconfidence due to their reliance on complex deep neural networks and one-hot target supervision, resulting in unreliable confidence scores that necessitate calibration. While current confidence calibration techniques primarily address single-label scenarios, there is a lack of focus on more practical and generalizable multi-label contexts. This paper introduces the Multi-Label Confidence Calibration (MLCC) task, aiming to provide well-calibrated confidence scores in multi-label scenarios. Unlike single-label images, multi-label images contain multiple objects, leading to semantic confusion and further unreliability in confidence scores. Existing single-label calibration methods, based on label smoothing, fail to account for category correlations, which are crucial for addressing semantic confusion, thereby yielding sub-optimal performance. To overcome these limitations, we propose the Dynamic Correlation Learning and Regularization (DCLR) algorithm, which leverages multi-grained semantic correlations to better model semantic confusion for adaptive regularization. DCLR learns dynamic instance-level and prototype-level similarities specific to each category, using these to measure semantic correlations across different categories. With this understanding, we construct adaptive label vectors that assign higher values to categories with strong correlations, thereby facilitating more effective regularization. We establish an evaluation benchmark, re-implementing several advanced confidence calibration algorithms and applying them to leading multi-label recognition (MLR) models for fair comparison. Through extensive experiments, we demonstrate the superior performance of DCLR over existing methods in providing reliable confidence scores in multi-label scenarios.
Spatial-Temporal Knowledge-Embedded Transformer for Video Scene Graph Generation
Sep 23, 2023



Video scene graph generation (VidSGG) aims to identify objects in visual scenes and infer their relationships for a given video. It requires not only a comprehensive understanding of each object scattered on the whole scene but also a deep dive into their temporal motions and interactions. Inherently, object pairs and their relationships enjoy spatial co-occurrence correlations within each image and temporal consistency/transition correlations across different images, which can serve as prior knowledge to facilitate VidSGG model learning and inference. In this work, we propose a spatial-temporal knowledge-embedded transformer (STKET) that incorporates the prior spatial-temporal knowledge into the multi-head cross-attention mechanism to learn more representative relationship representations. Specifically, we first learn spatial co-occurrence and temporal transition correlations in a statistical manner. Then, we design spatial and temporal knowledge-embedded layers that introduce the multi-head cross-attention mechanism to fully explore the interaction between visual representation and the knowledge to generate spatial- and temporal-embedded representations, respectively. Finally, we aggregate these representations for each subject-object pair to predict the final semantic labels and their relationships. Extensive experiments show that STKET outperforms current competing algorithms by a large margin, e.g., improving the mR@50 by 8.1%, 4.7%, and 2.1% on different settings over current algorithms.
Category-Adaptive Label Discovery and Noise Rejection for Multi-label Image Recognition with Partial Positive Labels
Nov 15, 2022
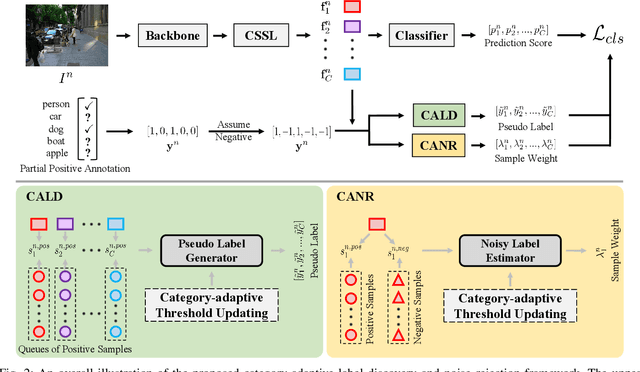
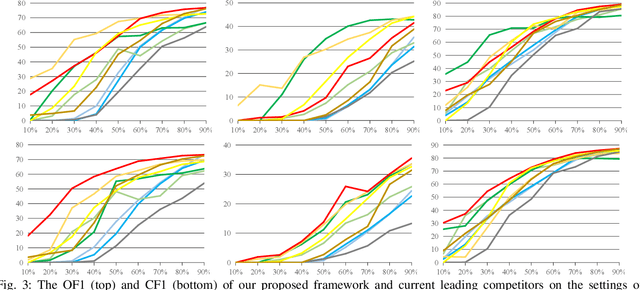
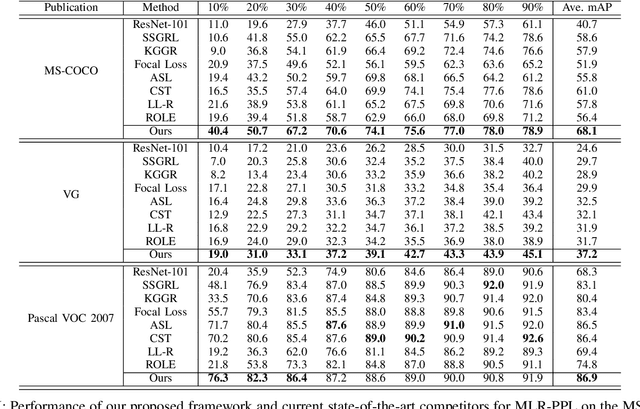
As a promising solution of reducing annotation cost, training multi-label models with partial positive labels (MLR-PPL), in which merely few positive labels are known while other are missing, attracts increasing attention. Due to the absence of any negative labels, previous works regard unknown labels as negative and adopt traditional MLR algorithms. To reject noisy labels, recent works regard large loss samples as noise but ignore the semantic correlation different multi-label images. In this work, we propose to explore semantic correlation among different images to facilitate the MLR-PPL task. Specifically, we design a unified framework, Category-Adaptive Label Discovery and Noise Rejection, that discovers unknown labels and rejects noisy labels for each category in an adaptive manner. The framework consists of two complementary modules: (1) Category-Adaptive Label Discovery module first measures the semantic similarity between positive samples and then complement unknown labels with high similarities; (2) Category-Adaptive Noise Rejection module first computes the sample weights based on semantic similarities from different samples and then discards noisy labels with low weights. Besides, we propose a novel category-adaptive threshold updating that adaptively adjusts the threshold, to avoid the time-consuming manual tuning process. Extensive experiments demonstrate that our proposed method consistently outperforms current leading algorithms.
Semantic-Aware Representation Blending for Multi-Label Image Recognition with Partial Labels
May 26, 2022
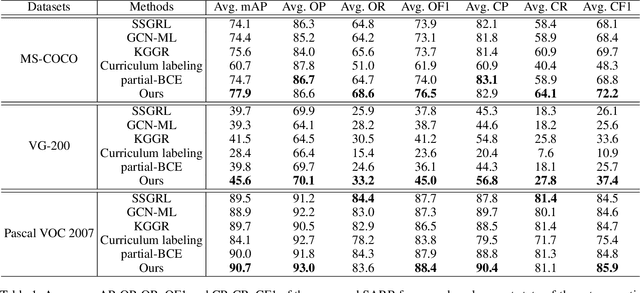
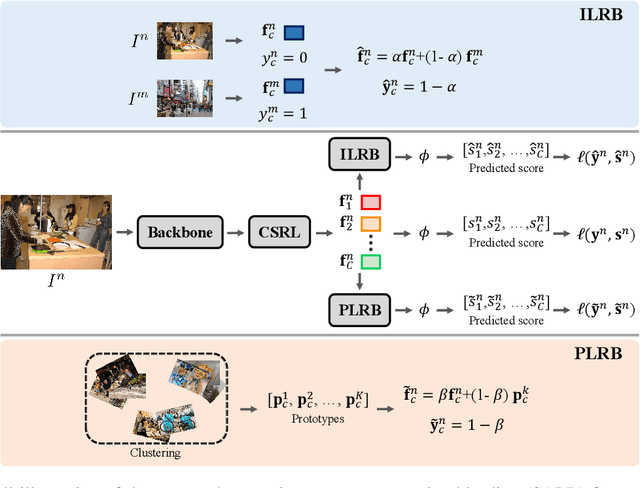
Despite achieving impressive progress, current multi-label image recognition (MLR) algorithms heavily depend on large-scale datasets with complete labels, making collecting large-scale datasets extremely time-consuming and labor-intensive. Training the multi-label image recognition models with partial labels (MLR-PL) is an alternative way to address this issue, in which merely some labels are known while others are unknown for each image (see Figure 1). However, current MLP-PL algorithms mainly rely on the pre-trained image classification or similarity models to generate pseudo labels for the unknown labels. Thus, they depend on a certain amount of data annotations and inevitably suffer from obvious performance drops, especially when the known label proportion is low. To address this dilemma, we propose a unified semantic-aware representation blending (SARB) that consists of two crucial modules to blend multi-granularity category-specific semantic representation across different images to transfer information of known labels to complement unknown labels. Extensive experiments on the MS-COCO, Visual Genome, and Pascal VOC 2007 datasets show that the proposed SARB consistently outperforms current state-of-the-art algorithms on all known label proportion settings. Concretely, it obtain the average mAP improvement of 1.9%, 4.5%, 1.0% on the three benchmark datasets compared with the second-best algorithm.
Heterogeneous Semantic Transfer for Multi-label Recognition with Partial Labels
May 23, 2022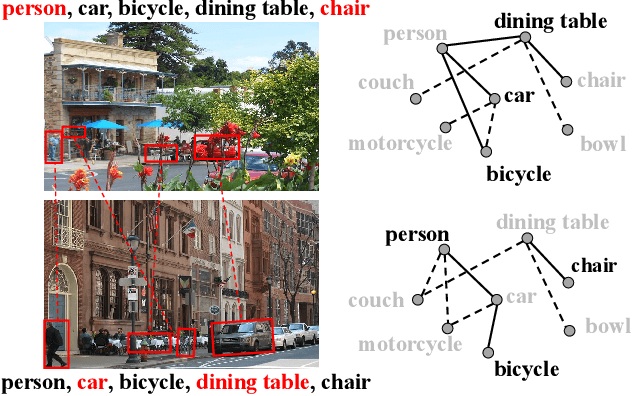
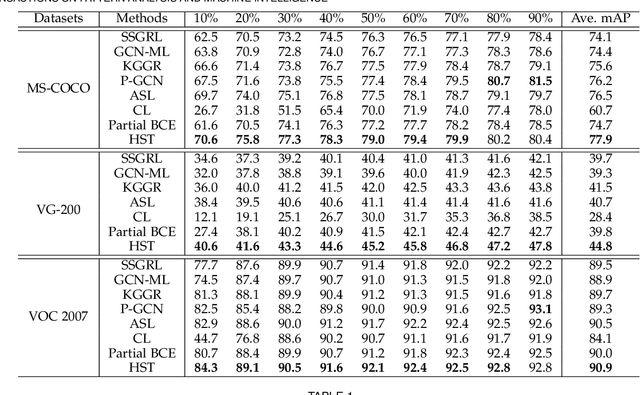

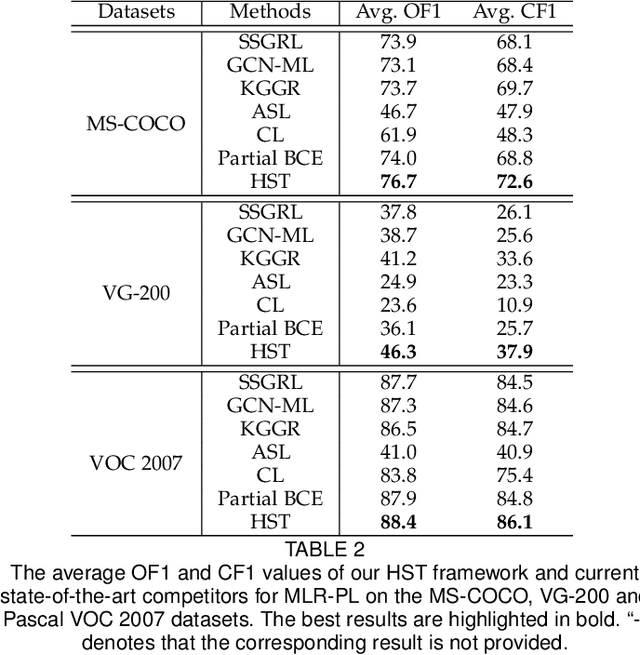
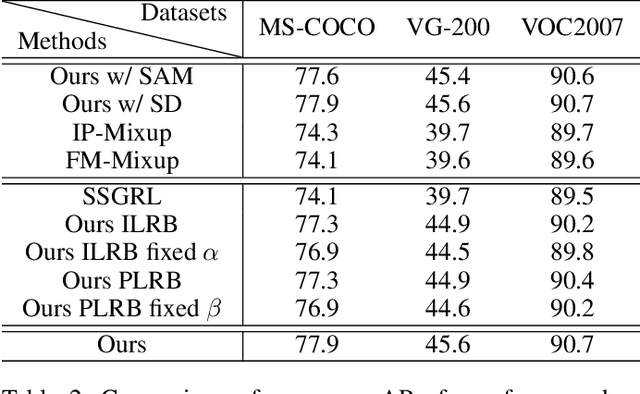
Multi-label image recognition with partial labels (MLR-PL), in which some labels are known while others are unknown for each image, may greatly reduce the cost of annotation and thus facilitate large-scale MLR. We find that strong semantic correlations exist within each image and across different images, and these correlations can help transfer the knowledge possessed by the known labels to retrieve the unknown labels and thus improve the performance of the MLR-PL task (see Figure 1). In this work, we propose a novel heterogeneous semantic transfer (HST) framework that consists of two complementary transfer modules that explore both within-image and cross-image semantic correlations to transfer the knowledge possessed by known labels to generate pseudo labels for the unknown labels. Specifically, an intra-image semantic transfer (IST) module learns an image-specific label co-occurrence matrix for each image and maps the known labels to complement the unknown labels based on these matrices. Additionally, a cross-image transfer (CST) module learns category-specific feature-prototype similarities and then helps complement the unknown labels that have high degrees of similarity with the corresponding prototypes. Finally, both the known and generated pseudo labels are used to train MLR models. Extensive experiments conducted on the Microsoft COCO, Visual Genome, and Pascal VOC 2007 datasets show that the proposed HST framework achieves superior performance to that of current state-of-the-art algorithms. Specifically, it obtains mean average precision (mAP) improvements of 1.4%, 3.3%, and 0.4% on the three datasets over the results of the best-performing previously developed algorithm.
Semantic Representation and Dependency Learning for Multi-Label Image Recognition
Apr 08, 2022
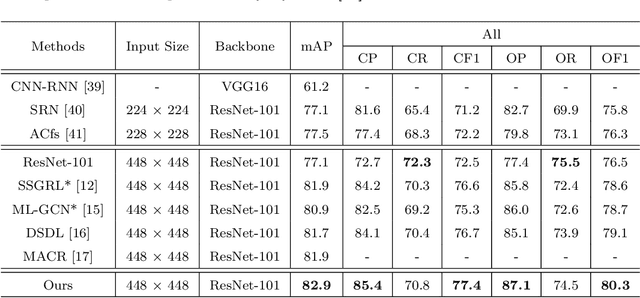
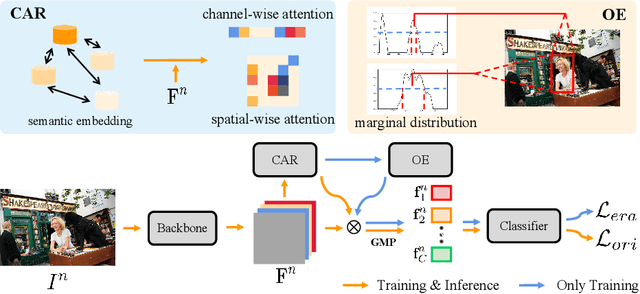
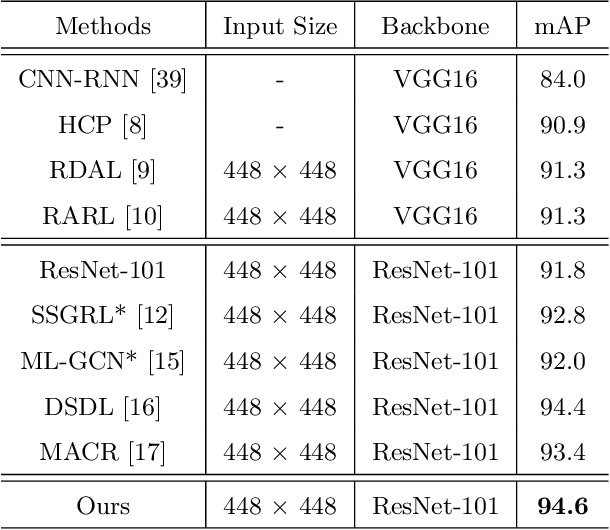
Recently many multi-label image recognition (MLR) works have made significant progress by introducing pre-trained object detection models to generate lots of proposals or utilizing statistical label co-occurrence enhance the correlation among different categories. However, these works have some limitations: (1) the effectiveness of the network significantly depends on pre-trained object detection models that bring expensive and unaffordable computation; (2) the network performance degrades when there exist occasional co-occurrence objects in images, especially for the rare categories. To address these problems, we propose a novel and effective semantic representation and dependency learning (SRDL) framework to learn category-specific semantic representation for each category and capture semantic dependency among all categories. Specifically, we design a category-specific attentional regions (CAR) module to generate channel/spatial-wise attention matrices to guide model to focus on semantic-aware regions. We also design an object erasing (OE) module to implicitly learn semantic dependency among categories by erasing semantic-aware regions to regularize the network training. Extensive experiments and comparisons on two popular MLR benchmark datasets (i.e., MS-COCO and Pascal VOC 2007) demonstrate the effectiveness of the proposed framework over current state-of-the-art algorithms.