 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Inference for Augmented Large Language Models
Oct 25, 2024



Augmented Large Language Models (LLMs) enhance the capabilities of standalone LLMs by integrating external data sources through API calls. In interactive LLM applications, efficient scheduling is crucial for maintaining low request completion times, directly impacting user engagement. However, these augmentations introduce scheduling challenges due to the need to manage limited memory for cached information (KV caches). As a result, traditional size-based scheduling algorithms, such as Shortest Job First (SJF), become less effective at minimizing completion times. Existing work focuses only on handling requests during API calls by preserving, discarding, or swapping memory without considering how to schedule requests with API calls. In this paper, we propose LAMPS, a novel LLM inference framework for augmented LLMs. LAMPS minimizes request completion time through a unified scheduling approach that considers the total length of requests and their handling strategies during API calls. Recognizing that LLM inference is memory-bound, our approach ranks requests based on their consumption of memory over time, which depends on both the output sizes and how a request is managed during its API calls. To implement our scheduling, LAMPS predicts the strategy that minimizes memory waste of a request during its API calls, aligning with but improving upon existing approaches. We also propose starvation prevention techniques and optimizations to mitigate the overhead of our scheduling. We implement LAMPS on top of vLLM and evaluate its performance against baseline LLM inference systems, demonstrating improvements in end-to-end latency by 27%-85% and reductions in TTFT by 4%-96% compared to the existing augmented-LLM system, with even greater gains over vLLM.
Efficient Inference for Augmented Large Language Models
Oct 23, 2024Augmented Large Language Models (LLMs) enhance the capabilities of standalone LLMs by integrating external data sources through API calls. In interactive LLM applications, efficient scheduling is crucial for maintaining low request completion times, directly impacting user engagement. However, these augmentations introduce scheduling challenges due to the need to manage limited memory for cached information (KV caches). As a result, traditional size-based scheduling algorithms, such as Shortest Job First (SJF), become less effective at minimizing completion times. Existing work focuses only on handling requests during API calls by preserving, discarding, or swapping memory without considering how to schedule requests with API calls. In this paper, we propose LAMPS, a novel LLM inference framework for augmented LLMs. LAMPS minimizes request completion time through a unified scheduling approach that considers the total length of requests and their handling strategies during API calls. Recognizing that LLM inference is memory-bound, our approach ranks requests based on their consumption of memory over time, which depends on both the output sizes and how a request is managed during its API calls. To implement our scheduling, LAMPS predicts the strategy that minimizes memory waste of a request during its API calls, aligning with but improving upon existing approaches. We also propose starvation prevention techniques and optimizations to mitigate the overhead of our scheduling. We implement LAMPS on top of vLLM and evaluate its performance against baseline LLM inference systems, demonstrating improvements in end-to-end latency by 27%-85% and reductions in TTFT by 4%-96% compared to the existing augmented-LLM system, with even greater gains over vLLM.
Zero-shot Referring Expression Comprehension via Structural Similarity Between Images and Captions
Nov 28, 2023

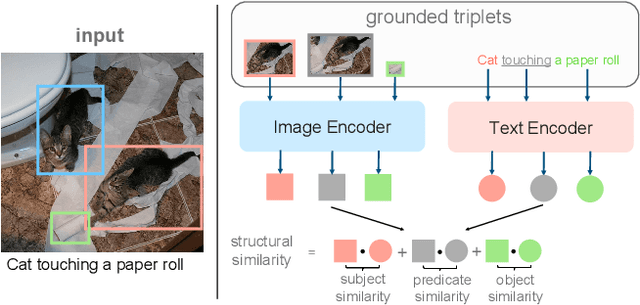

Zero-shot referring expression comprehension aims at localizing bounding boxes in an image corresponding to the provided textual prompts, which requires: (i) a fine-grained disentanglement of complex visual scene and textual context, and (ii) a capacity to understand relationships among disentangled entities. Unfortunately, existing large vision-language alignment (VLA) models, e.g., CLIP, struggle with both aspects so cannot be directly used for this task. To mitigate this gap, we leverage large foundation models to disentangle both images and texts into triplets in the format of (subject, predicate, object). After that, grounding is accomplished by calculating the structural similarity matrix between visual and textual triplets with a VLA model, and subsequently propagate it to an instance-level similarity matrix. Furthermore, to equip VLA models with the ability of relationship understanding, we design a triplet-matching objective to fine-tune the VLA models on a collection of curated dataset containing abundant entity relationships. Experiments demonstrate that our visual grounding performance increase of up to 19.5% over the SOTA zero-shot model on RefCOCO/+/g. On the more challenging Who's Waldo dataset, our zero-shot approach achieves comparable accuracy to the fully supervised model.
Category-Adaptive Label Discovery and Noise Rejection for Multi-label Image Recognition with Partial Positive Labels
Nov 15, 2022
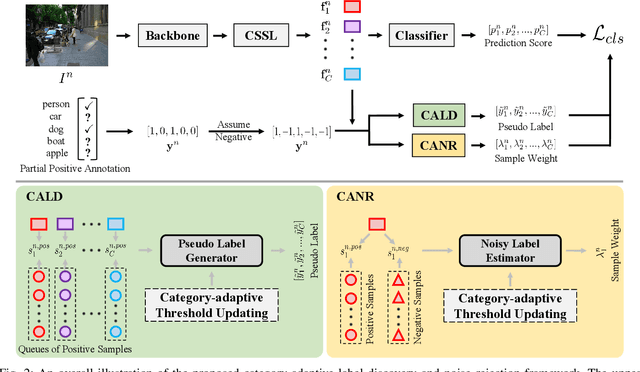
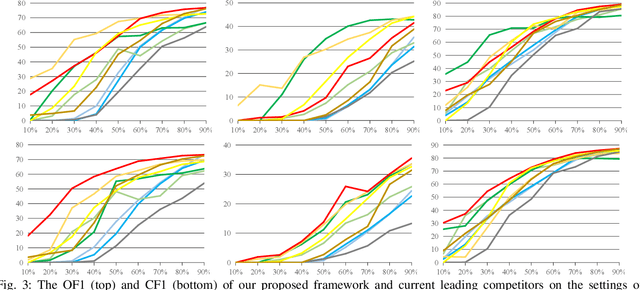
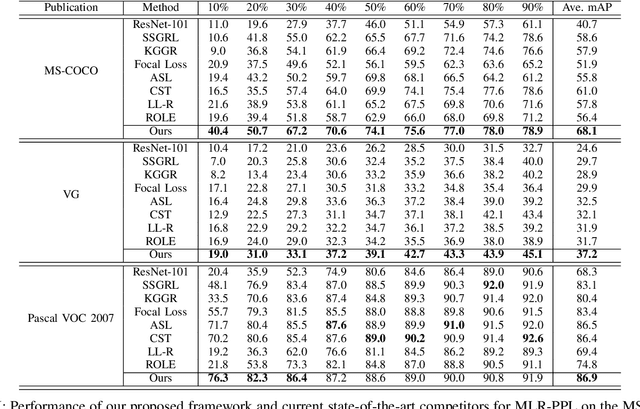
As a promising solution of reducing annotation cost, training multi-label models with partial positive labels (MLR-PPL), in which merely few positive labels are known while other are missing, attracts increasing attention. Due to the absence of any negative labels, previous works regard unknown labels as negative and adopt traditional MLR algorithms. To reject noisy labels, recent works regard large loss samples as noise but ignore the semantic correlation different multi-label images. In this work, we propose to explore semantic correlation among different images to facilitate the MLR-PPL task. Specifically, we design a unified framework, Category-Adaptive Label Discovery and Noise Rejection, that discovers unknown labels and rejects noisy labels for each category in an adaptive manner. The framework consists of two complementary modules: (1) Category-Adaptive Label Discovery module first measures the semantic similarity between positive samples and then complement unknown labels with high similarities; (2) Category-Adaptive Noise Rejection module first computes the sample weights based on semantic similarities from different samples and then discards noisy labels with low weights. Besides, we propose a novel category-adaptive threshold updating that adaptively adjusts the threshold, to avoid the time-consuming manual tuning process. Extensive experiments demonstrate that our proposed method consistently outperforms current leading algorithms.