 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Events Like Code: A Multi-Agent Programming Framework for Zero-Shot Event Extraction
Nov 17, 2025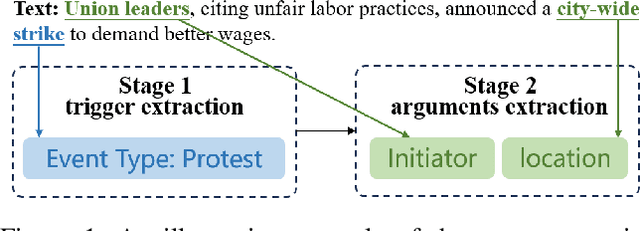
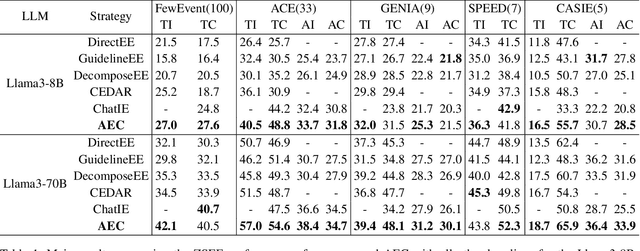
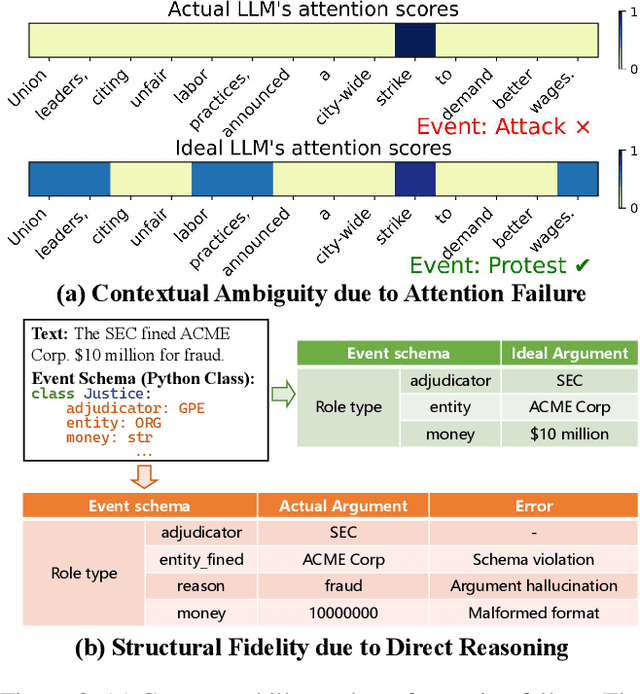
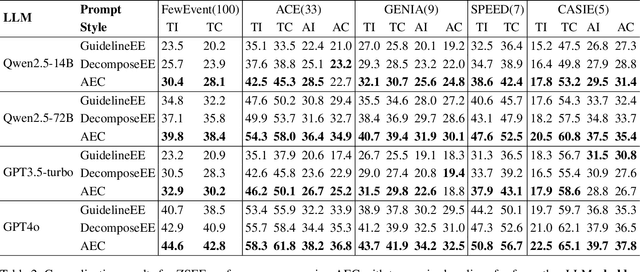
Zero-shot event extraction (ZSEE) remains a significant challenge for large language models (LLMs) due to the need for complex reasoning and domain-specific understanding. Direct prompting often yields incomplete or structurally invalid outputs--such as misclassified triggers, missing arguments, and schema violations. To address these limitations, we present Agent-Event-Coder (AEC), a novel multi-agent framework that treats event extraction like software engineering: as a structured, iterative code-generation process. AEC decomposes ZSEE into specialized subtasks--retrieval, planning, coding, and verification--each handled by a dedicated LLM agent. Event schemas are represented as executable class definitions, enabling deterministic validation and precise feedback via a verification agent. This programming-inspired approach allows for systematic disambiguation and schema enforcement through iterative refinement. By leveraging collaborative agent workflows, AEC enables LLMs to produce precise, complete, and schema-consistent extractions in zero-shot settings. Experiments across five diverse domains and six LLMs demonstrate that AEC consistently outperforms prior zero-shot baselines, showcasing the power of treating event extraction like code generation. The code and data are released on https://github.com/UESTC-GQJ/Agent-Event-Coder.
ITPP: Learning Disentangled Event Dynamics in Marked Temporal Point Processes
Nov 08, 2025Marked Temporal Point Processes (MTPPs) provide a principled framework for modeling asynchronous event sequences by conditioning on the history of past events. However, most existing MTPP models rely on channel-mixing strategies that encode information from different event types into a single, fixed-size latent representation. This entanglement can obscure type-specific dynamics, leading to performance degradation and increased risk of overfitting. In this work, we introduce ITPP, a novel channel-independent architecture for MTPP modeling that decouples event type information using an encoder-decoder framework with an ODE-based backbone. Central to ITPP is a type-aware inverted self-attention mechanism, designed to explicitly model inter-channel correlations among heterogeneous event types. This architecture enhances effectiveness and robustness while reducing overfitting. Comprehensive experiments on multiple real-world and synthetic datasets demonstrate that ITPP consistently outperforms state-of-the-art MTPP models in both predictive accuracy and generalization.
Bridging Generative and Discriminative Learning: Few-Shot Relation Extraction via Two-Stage Knowledge-Guided Pre-training
May 18, 2025



Few-Shot Relation Extraction (FSRE) remains a challenging task due to the scarcity of annotated data and the limited generalization capabilities of existing models. Although large language models (LLMs) have demonstrated potential in FSRE through in-context learning (ICL), their general-purpose training objectives often result in suboptimal performance for task-specific relation extraction. To overcome these challenges, we propose TKRE (Two-Stage Knowledge-Guided Pre-training for Relation Extraction), a novel framework that synergistically integrates LLMs with traditional relation extraction models, bridging generative and discriminative learning paradigms. TKRE introduces two key innovations: (1) leveraging LLMs to generate explanation-driven knowledge and schema-constrained synthetic data, addressing the issue of data scarcity; and (2) a two-stage pre-training strategy combining Masked Span Language Modeling (MSLM) and Span-Level Contrastive Learning (SCL) to enhance relational reasoning and generalization. Together, these components enable TKRE to effectively tackle FSRE tasks. Comprehensive experiments on benchmark datasets demonstrate the efficacy of TKRE, achieving new state-of-the-art performance in FSRE and underscoring its potential for broader application in low-resource scenarios. \footnote{The code and data are released on https://github.com/UESTC-GQJ/TKRE.
UrbanMind: Urban Dynamics Prediction with Multifaceted Spatial-Temporal Large Language Models
May 16, 2025Understanding and predicting urban dynamics is crucial for managing transportation systems, optimizing urban planning, and enhancing public services. While neural network-based approaches have achieved success, they often rely on task-specific architectures and large volumes of data, limiting their ability to generalize across diverse urban scenarios. Meanwhile, Large Language Models (LLMs) offer strong reasoning and generalization capabilities, yet their application to spatial-temporal urban dynamics remains underexplored. Existing LLM-based methods struggle to effectively integrate multifaceted spatial-temporal data and fail to address distributional shifts between training and testing data, limiting their predictive reliability in real-world applications. To bridge this gap, we propose UrbanMind, a novel spatial-temporal LLM framework for multifaceted urban dynamics prediction that ensures both accurate forecasting and robust generalization. At its core, UrbanMind introduces Muffin-MAE, a multifaceted fusion masked autoencoder with specialized masking strategies that capture intricate spatial-temporal dependencies and intercorrelations among multifaceted urban dynamics. Additionally, we design a semantic-aware prompting and fine-tuning strategy that encodes spatial-temporal contextual details into prompts, enhancing LLMs' ability to reason over spatial-temporal patterns. To further improve generalization, we introduce a test time adaptation mechanism with a test data reconstructor, enabling UrbanMind to dynamically adjust to unseen test data by reconstructing LLM-generated embeddings. Extensive experiments on real-world urban datasets across multiple cities demonstrate that UrbanMind consistently outperforms state-of-the-art baselines, achieving high accuracy and robust generalization, even in zero-shot settings.
Fine-grained Spatio-temporal Event Prediction with Self-adaptive Anchor Graph
Jan 15, 2025Event prediction tasks often handle spatio-temporal data distributed in a large spatial area. Different regions in the area exhibit different characteristics while having latent correlations. This spatial heterogeneity and correlations greatly affect the spatio-temporal distributions of event occurrences, which has not been addressed by state-of-the-art models. Learning spatial dependencies of events in a continuous space is challenging due to its fine granularity and a lack of prior knowledge. In this work, we propose a novel Graph Spatio-Temporal Point Process (GSTPP) model for fine-grained event prediction. It adopts an encoder-decoder architecture that jointly models the state dynamics of spatially localized regions using neural Ordinary Differential Equations (ODEs). The state evolution is built on the foundation of a novel Self-Adaptive Anchor Graph (SAAG) that captures spatial dependencies. By adaptively localizing the anchor nodes in the space and jointly constructing the correlation edges between them, the SAAG enhances the model's ability of learning complex spatial event patterns. The proposed GSTPP model greatly improves the accuracy of fine-grained event prediction. Extensive experimental results show that our method greatly improves the prediction accuracy over existing spatio-temporal event prediction approaches.
BANER: Boundary-Aware LLMs for Few-Shot Named Entity Recognition
Dec 03, 2024



Despite the recent success of two-stage prototypical networks in few-shot named entity recognition (NER), challenges such as over/under-detected false spans in the span detection stage and unaligned entity prototypes in the type classification stage persist. Additionally, LLMs have not proven to be effective few-shot information extractors in general. In this paper, we propose an approach called Boundary-Aware LLMs for Few-Shot Named Entity Recognition to address these issues. We introduce a boundary-aware contrastive learning strategy to enhance the LLM's ability to perceive entity boundaries for generalized entity spans. Additionally, we utilize LoRAHub to align information from the target domain to the source domain, thereby enhancing adaptive cross-domain classification capabilities. Extensive experiments across various benchmarks demonstrate that our framework outperforms prior methods, validating its effectiveness. In particular, the proposed strategies demonstrate effectiveness across a range of LLM architectures. The code and data are released on https://github.com/UESTC-GQJ/BANER.
Learning Granularity Representation for Temporal Knowledge Graph Completion
Aug 27, 2024

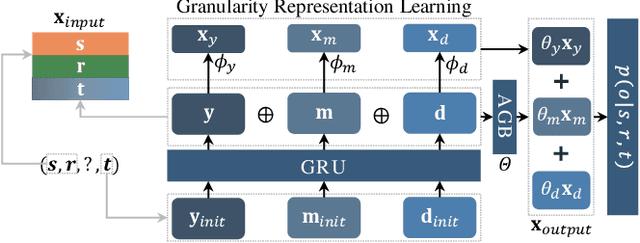

Temporal Knowledge Graphs (TKGs) incorporate temporal information to reflect the dynamic structural knowledge and evolutionary patterns of real-world facts. Nevertheless, TKGs are still limited in downstream applications due to the problem of incompleteness. Consequently, TKG completion (also known as link prediction) has been widely studied, with recent research focusing on incorporating independent embeddings of time or combining them with entities and relations to form temporal representations. However, most existing methods overlook the impact of history from a multi-granularity aspect. The inherent semantics of human-defined temporal granularities, such as ordinal dates, reveal general patterns to which facts typically adhere. To counter this limitation, this paper proposes \textbf{L}earning \textbf{G}ranularity \textbf{Re}presentation (termed $\mathsf{LGRe}$) for TKG completion. It comprises two main components: Granularity Representation Learning (GRL) and Adaptive Granularity Balancing (AGB). Specifically, GRL employs time-specific multi-layer convolutional neural networks to capture interactions between entities and relations at different granularities. After that, AGB generates adaptive weights for these embeddings according to temporal semantics, resulting in expressive representations of predictions. Moreover, to reflect similar semantics of adjacent timestamps, a temporal loss function is introduced. Extensive experimental results on four event benchmarks demonstrate the effectiveness of $\mathsf{LGRe}$ in learning time-related representations. To ensure reproducibility, our code is available at https://github.com/KcAcoZhang/LGRe.
Historically Relevant Event Structuring for Temporal Knowledge Graph Reasoning
May 17, 2024



Temporal Knowledge Graph (TKG) reasoning focuses on predicting events through historical information within snapshots distributed on a timeline. Existing studies mainly concentrate on two perspectives of leveraging the history of TKGs, including capturing evolution of each recent snapshot or correlations among global historical facts. Despite the achieved significant accomplishments, these models still fall short of (1) investigating the influences of multi-granularity interactions across recent snapshots and (2) harnessing the expressive semantics of significant links accorded with queries throughout the entire history, especially events exerting a profound impact on the future. These inadequacies restrict representation ability to reflect historical dependencies and future trends thoroughly. To overcome these drawbacks, we propose an innovative TKG reasoning approach towards \textbf{His}torically \textbf{R}elevant \textbf{E}vents \textbf{S}tructuring ($\mathsf{HisRES}$). Concretely, $\mathsf{HisRES}$ comprises two distinctive modules excelling in structuring historically relevant events within TKGs, including a multi-granularity evolutionary encoder that captures structural and temporal dependencies of the most recent snapshots, and a global relevance encoder that concentrates on crucial correlations among events relevant to queries from the entire history. Furthermore, $\mathsf{HisRES}$ incorporates a self-gating mechanism for adaptively merging multi-granularity recent and historically relevant structuring representations. Extensive experiments on four event-based benchmarks demonstrate the state-of-the-art performance of $\mathsf{HisRES}$ and indicate the superiority and effectiveness of structuring historical relevance for TKG reasoning.
Dual-View Data Hallucination with Semantic Relation Guidance for Few-Shot Image Recognition
Jan 13, 2024



Learning to recognize novel concepts from just a few image samples is very challenging as the learned model is easily overfitted on the few data and results in poor generalizability. One promising but underexplored solution is to compensate the novel classes by generating plausible samples. However, most existing works of this line exploit visual information only, rendering the generated data easy to be distracted by some challenging factors contained in the few available samples. Being aware of the semantic information in the textual modality that reflects human concepts, this work proposes a novel framework that exploits semantic relations to guide dual-view data hallucination for few-shot image recognition. The proposed framework enables generating more diverse and reasonable data samples for novel classes through effective information transfer from base classes. Specifically, an instance-view data hallucination module hallucinates each sample of a novel class to generate new data by employing local semantic correlated attention and global semantic feature fusion derived from base classes. Meanwhile, a prototype-view data hallucination module exploits semantic-aware measure to estimate the prototype of a novel class and the associated distribution from the few samples, which thereby harvests the prototype as a more stable sample and enables resampling a large number of samples. We conduct extensive experiments and comparisons with state-of-the-art methods on several popular few-shot benchmarks to verify the effectiveness of the proposed framework.
Learning Multi-graph Structure for Temporal Knowledge Graph Reasoning
Dec 04, 2023



Temporal Knowledge Graph (TKG) reasoning that forecasts future events based on historical snapshots distributed over timestamps is denoted as extrapolation and has gained significant attention. Owing to its extreme versatility and variation in spatial and temporal correlations, TKG reasoning presents a challenging task, demanding efficient capture of concurrent structures and evolutional interactions among facts. While existing methods have made strides in this direction, they still fall short of harnessing the diverse forms of intrinsic expressive semantics of TKGs, which encompass entity correlations across multiple timestamps and periodicity of temporal information. This limitation constrains their ability to thoroughly reflect historical dependencies and future trends. In response to these drawbacks, this paper proposes an innovative reasoning approach that focuses on Learning Multi-graph Structure (LMS). Concretely, it comprises three distinct modules concentrating on multiple aspects of graph structure knowledge within TKGs, including concurrent and evolutional patterns along timestamps, query-specific correlations across timestamps, and semantic dependencies of timestamps, which capture TKG features from various perspectives. Besides, LMS incorporates an adaptive gate for merging entity representations both along and across timestamps effectively. Moreover, it integrates timestamp semantics into graph attention calculations and time-aware decoders, in order to impose temporal constraints on events and narrow down prediction scopes with historical statistics. Extensive experimental results on five event-based benchmark datasets demonstrate that LMS outperforms state-of-the-art extrapolation models, indicating the superiority of modeling a multi-graph perspective for TKG reasoning.