 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Talking Head Models With Adjacent Frame Prior for Speech-Preserving Facial Expression Manipulation
Jan 19, 2026Speech-Preserving Facial Expression Manipulation (SPFEM) is an innovative technique aimed at altering facial expressions in images and videos while retaining the original mouth movements. Despite advancements, SPFEM still struggles with accurate lip synchronization due to the complex interplay between facial expressions and mouth shapes. Capitalizing on the advanced capabilities of audio-driven talking head generation (AD-THG) models in synthesizing precise lip movements, our research introduces a novel integration of these models with SPFEM. We present a new framework, Talking Head Facial Expression Manipulation (THFEM), which utilizes AD-THG models to generate frames with accurately synchronized lip movements from audio inputs and SPFEM-altered images. However, increasing the number of frames generated by AD-THG models tends to compromise the realism and expression fidelity of the images. To counter this, we develop an adjacent frame learning strategy that finetunes AD-THG models to predict sequences of consecutive frames. This strategy enables the models to incorporate information from neighboring frames, significantly improving image quality during testing. Our extensive experimental evaluations demonstrate that this framework effectively preserves mouth shapes during expression manipulations, highlighting the substantial benefits of integrating AD-THG with SPFEM.
Deep learning for 3D point cloud processing -- from approaches, tasks to its implications on urban and environmental applications
Sep 15, 2025Point cloud processing as a fundamental task in the field of geomatics and computer vision, has been supporting tasks and applications at different scales from air to ground, including mapping, environmental monitoring, urban/tree structure modeling, automated driving, robotics, disaster responses etc. Due to the rapid development of deep learning, point cloud processing algorithms have nowadays been almost explicitly dominated by learning-based approaches, most of which are yet transitioned into real-world practices. Existing surveys primarily focus on the ever-updating network architecture to accommodate unordered point clouds, largely ignoring their practical values in typical point cloud processing applications, in which extra-large volume of data, diverse scene contents, varying point density, data modality need to be considered. In this paper, we provide a meta review on deep learning approaches and datasets that cover a selection of critical tasks of point cloud processing in use such as scene completion, registration, semantic segmentation, and modeling. By reviewing a broad range of urban and environmental applications these tasks can support, we identify gaps to be closed as these methods transformed into applications and draw concluding remarks in both the algorithmic and practical aspects of the surveyed methods.
Exploiting Temporal Audio-Visual Correlation Embedding for Audio-Driven One-Shot Talking Head Animation
Apr 08, 2025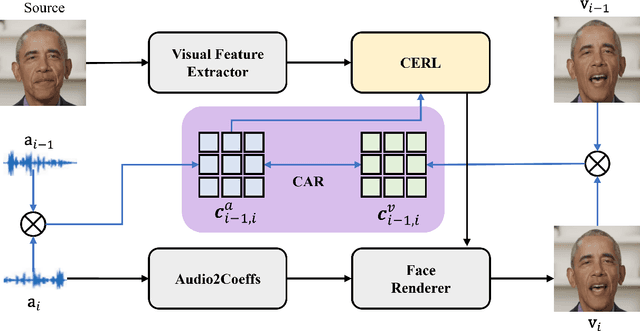
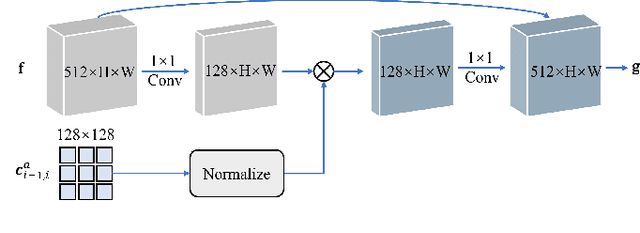
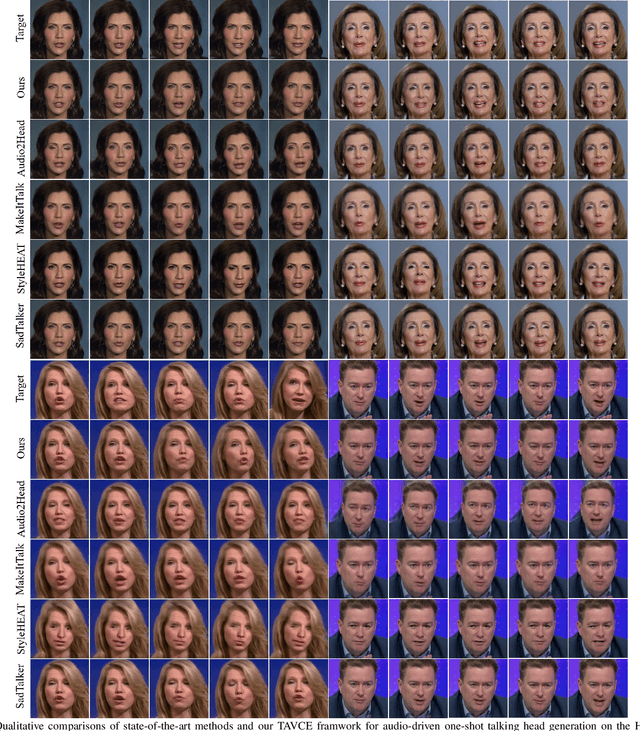

The paramount challenge in audio-driven One-shot Talking Head Animation (ADOS-THA) lies in capturing subtle imperceptible changes between adjacent video frames. Inherently, the temporal relationship of adjacent audio clips is highly correlated with that of the corresponding adjacent video frames, offering supplementary information that can be pivotal for guiding and supervising talking head animations. In this work, we propose to learn audio-visual correlations and integrate the correlations to help enhance feature representation and regularize final generation by a novel Temporal Audio-Visual Correlation Embedding (TAVCE) framework. Specifically, it first learns an audio-visual temporal correlation metric, ensuring the temporal audio relationships of adjacent clips are aligned with the temporal visual relationships of corresponding adjacent video frames. Since the temporal audio relationship contains aligned information about the visual frame, we first integrate it to guide learning more representative features via a simple yet effective channel attention mechanism. During training, we also use the alignment correlations as an additional objective to supervise generating visual frames. We conduct extensive experiments on several publicly available benchmarks (i.e., HDTF, LRW, VoxCeleb1, and VoxCeleb2) to demonstrate its superiority over existing leading algorithms.
Learning Semantic-Aware Representation in Visual-Language Models for Multi-Label Recognition with Partial Labels
Dec 14, 2024



Multi-label recognition with partial labels (MLR-PL), in which only some labels are known while others are unknown for each image, is a practical task in computer vision, since collecting large-scale and complete multi-label datasets is difficult in real application scenarios. Recently, vision language models (e.g. CLIP) have demonstrated impressive transferability to downstream tasks in data limited or label limited settings. However, current CLIP-based methods suffer from semantic confusion in MLR task due to the lack of fine-grained information in the single global visual and textual representation for all categories. In this work, we address this problem by introducing a semantic decoupling module and a category-specific prompt optimization method in CLIP-based framework. Specifically, the semantic decoupling module following the visual encoder learns category-specific feature maps by utilizing the semantic-guided spatial attention mechanism. Moreover, the category-specific prompt optimization method is introduced to learn text representations aligned with category semantics. Therefore, the prediction of each category is independent, which alleviate the semantic confusion problem. Extensive experiments on Microsoft COCO 2014 and Pascal VOC 2007 datasets demonstrate that the proposed framework significantly outperforms current state-of-art methods with a simpler model structure. Additionally, visual analysis shows that our method effectively separates information from different categories and achieves better performance compared to CLIP-based baseline method.