 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIGV-RRT: Prior-Real-Time Observation Fusion for Active Object Search in Changing Environments
Mar 23, 2026Object Goal Navigation (ObjectNav) in temporally changing indoor environments is challenging because object relocation can invalidate historical scene knowledge. To address this issue, we propose a probabilistic planning framework that combines uncertainty-aware scene priors with online target relevance estimates derived from a Vision Language Model (VLM). The framework contains a dual-layer semantic mapping module and a real-time planner. The mapping module includes an Information Gain Map (IGM) built from a 3D scene graph (3DSG) during prior exploration to model object co-occurrence relations and provide global guidance on likely target regions. It also maintains a VLM score map (VLM-SM) that fuses confidence-weighted semantic observations into the map for local validation of the current scene. Based on these two cues, we develop a planner that jointly exploits information gain and semantic evidence for online decision making. The planner biases tree expansion toward semantically salient regions with high prior likelihood and strong online relevance (IGV-RRT), while preserving kinematic feasibility through gradient-based analysis. Simulation and real-world experiments demonstrate that the proposed method effectively mitigates the impact of object rearrangement, achieving higher search efficiency and success rates than representative baselines in complex indoor environments.
Multimodal Graph Representation Learning with Dynamic Information Pathways
Mar 10, 2026Multimodal graphs, where nodes contain heterogeneous features such as images and text, are increasingly common in real-world applications. Effectively learning on such graphs requires both adaptive intra-modal message passing and efficient inter-modal aggregation. However, most existing approaches to multimodal graph learning are typically extended from conventional graph neural networks and rely on static structures or dense attention, which limit flexibility and expressive node embedding learning. In this paper, we propose a novel multimodal graph representation learning framework with Dynamic information Pathways (DiP). By introducing modality-specific pseudo nodes, DiP enables dynamic message routing within each modality via proximity-guided pseudo-node interactions and captures inter-modality dependence through efficient information pathways in a shared state space. This design achieves adaptive, expressive, and sparse message propagation across modalities with linear complexity. We conduct the link prediction and node classification tasks to evaluate performance and carry out full experimental analyses. Extensive experiments across multiple benchmarks demonstrate that DiP consistently outperforms baselines.
FusionEdit: Semantic Fusion and Attention Modulation for Training-Free Image Editing
Feb 09, 2026Text-guided image editing aims to modify specific regions according to the target prompt while preserving the identity of the source image. Recent methods exploit explicit binary masks to constrain editing, but hard mask boundaries introduce artifacts and reduce editability. To address these issues, we propose FusionEdit, a training-free image editing framework that achieves precise and controllable edits. First, editing and preserved regions are automatically identified by measuring semantic discrepancies between source and target prompts. To mitigate boundary artifacts, FusionEdit performs distance-aware latent fusion along region boundaries to yield the soft and accurate mask, and employs a total variation loss to enforce smooth transitions, obtaining natural editing results. Second, FusionEdit leverages AdaIN-based modulation within DiT attention layers to perform a statistical attention fusion in the editing region, enhancing editability while preserving global consistency with the source image. Extensive experiments demonstrate that our FusionEdit significantly outperforms state-of-the-art methods. Code is available at \href{https://github.com/Yvan1001/FusionEdit}{https://github.com/Yvan1001/FusionEdit}.
Just in time Informed Trees: Manipulability-Aware Asymptotically Optimized Motion Planning
Jan 27, 2026In high-dimensional robotic path planning, traditional sampling-based methods often struggle to efficiently identify both feasible and optimal paths in complex, multi-obstacle environments. This challenge is intensified in robotic manipulators, where the risk of kinematic singularities and self-collisions further complicates motion efficiency and safety. To address these issues, we introduce the Just-in-Time Informed Trees (JIT*) algorithm, an enhancement over Effort Informed Trees (EIT*), designed to improve path planning through two core modules: the Just-in-Time module and the Motion Performance module. The Just-in-Time module includes "Just-in-Time Edge," which dynamically refines edge connectivity, and "Just-in-Time Sample," which adjusts sampling density in bottleneck areas to enable faster initial path discovery. The Motion Performance module balances manipulability and trajectory cost through dynamic switching, optimizing motion control while reducing the risk of singularities. Comparative analysis shows that JIT* consistently outperforms traditional sampling-based planners across $\mathbb{R}^4$ to $\mathbb{R}^{16}$ dimensions. Its effectiveness is further demonstrated in single-arm and dual-arm manipulation tasks, with experimental results available in a video at https://youtu.be/nL1BMHpMR7c.
SliceLens: Fine-Grained and Grounded Error Slice Discovery for Multi-Instance Vision Tasks
Dec 31, 2025Systematic failures of computer vision models on subsets with coherent visual patterns, known as error slices, pose a critical challenge for robust model evaluation. Existing slice discovery methods are primarily developed for image classification, limiting their applicability to multi-instance tasks such as detection, segmentation, and pose estimation. In real-world scenarios, error slices often arise from corner cases involving complex visual relationships, where existing instance-level approaches lacking fine-grained reasoning struggle to yield meaningful insights. Moreover, current benchmarks are typically tailored to specific algorithms or biased toward image classification, with artificial ground truth that fails to reflect real model failures. To address these limitations, we propose SliceLens, a hypothesis-driven framework that leverages LLMs and VLMs to generate and verify diverse failure hypotheses through grounded visual reasoning, enabling reliable identification of fine-grained and interpretable error slices. We further introduce FeSD (Fine-grained Slice Discovery), the first benchmark specifically designed for evaluating fine-grained error slice discovery across instance-level vision tasks, featuring expert-annotated and carefully refined ground-truth slices with precise grounding to local error regions. Extensive experiments on both existing benchmarks and FeSD demonstrate that SliceLens achieves state-of-the-art performance, improving Precision@10 by 0.42 (0.73 vs. 0.31) on FeSD, and identifies interpretable slices that facilitate actionable model improvements, as validated through model repair experiments.
Estimated Informed Anytime Search for Sampling-Based Planning via Adaptive Sampler
Aug 29, 2025Path planning in robotics often involves solving continuously valued, high-dimensional problems. Popular informed approaches include graph-based searches, such as A*, and sampling-based methods, such as Informed RRT*, which utilize informed set and anytime strategies to expedite path optimization incrementally. Informed sampling-based planners define informed sets as subsets of the problem domain based on the current best solution cost. However, when no solution is found, these planners re-sample and explore the entire configuration space, which is time-consuming and computationally expensive. This article introduces Multi-Informed Trees (MIT*), a novel planner that constructs estimated informed sets based on prior admissible solution costs before finding the initial solution, thereby accelerating the initial convergence rate. Moreover, MIT* employs an adaptive sampler that dynamically adjusts the sampling strategy based on the exploration process. Furthermore, MIT* utilizes length-related adaptive sparse collision checks to guide lazy reverse search. These features enhance path cost efficiency and computation times while ensuring high success rates in confined scenarios. Through a series of simulations and real-world experiments, it is confirmed that MIT* outperforms existing single-query, sampling-based planners for problems in R^4 to R^16 and has been successfully applied to real-world robot manipulation tasks. A video showcasing our experimental results is available at: https://youtu.be/30RsBIdexTU
Genetic Informed Trees (GIT*): Path Planning via Reinforced Genetic Programming Heuristics
Aug 28, 2025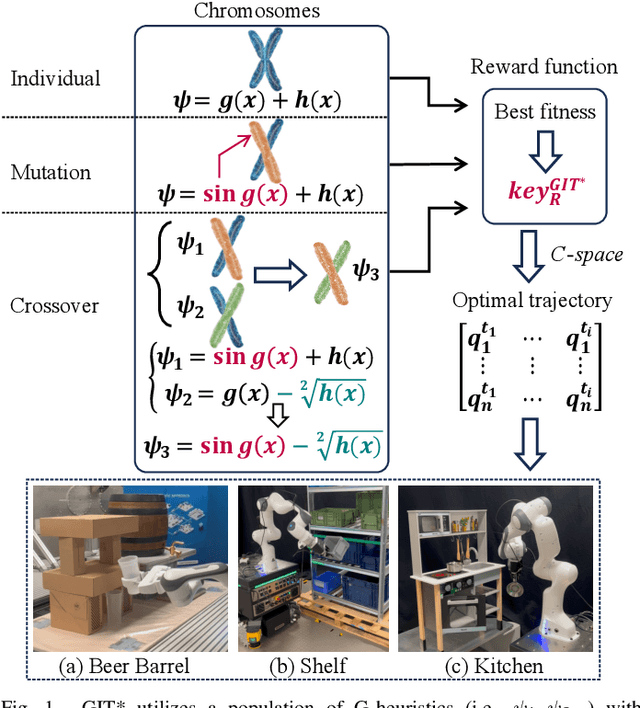
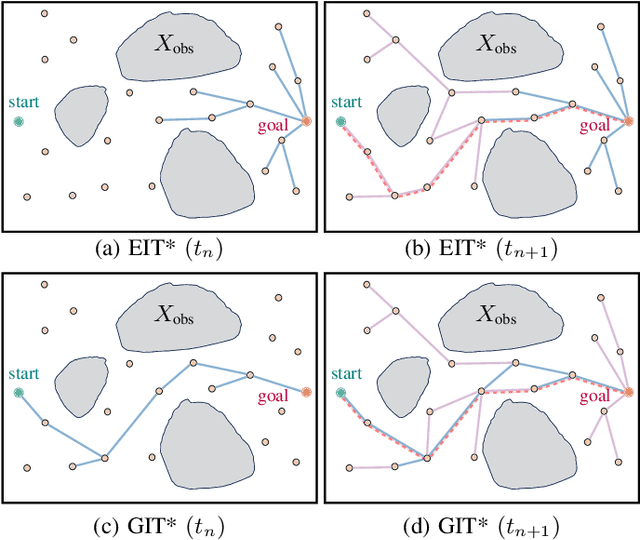
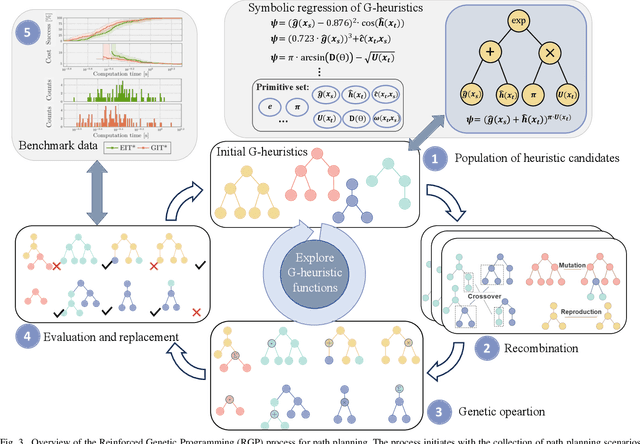
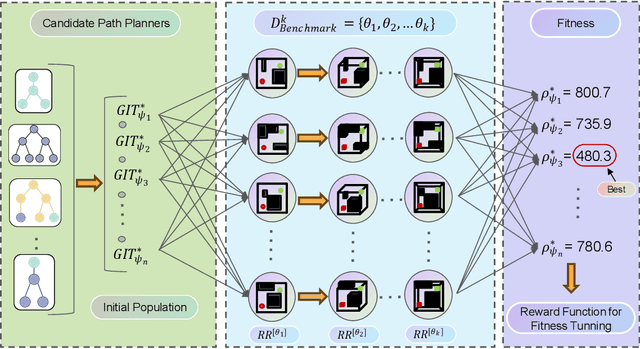
Optimal path planning involves finding a feasible state sequence between a start and a goal that optimizes an objective. This process relies on heuristic functions to guide the search direction. While a robust function can improve search efficiency and solution quality, current methods often overlook available environmental data and simplify the function structure due to the complexity of information relationships. This study introduces Genetic Informed Trees (GIT*), which improves upon Effort Informed Trees (EIT*) by integrating a wider array of environmental data, such as repulsive forces from obstacles and the dynamic importance of vertices, to refine heuristic functions for better guidance. Furthermore, we integrated reinforced genetic programming (RGP), which combines genetic programming with reward system feedback to mutate genotype-generative heuristic functions for GIT*. RGP leverages a multitude of data types, thereby improving computational efficiency and solution quality within a set timeframe. Comparative analyses demonstrate that GIT* surpasses existing single-query, sampling-based planners in problems ranging from R^4 to R^16 and was tested on a real-world mobile manipulation task. A video showcasing our experimental results is available at https://youtu.be/URjXbc_BiYg
APT*: Asymptotically Optimal Motion Planning via Adaptively Prolated Elliptical R-Nearest Neighbors
Aug 27, 2025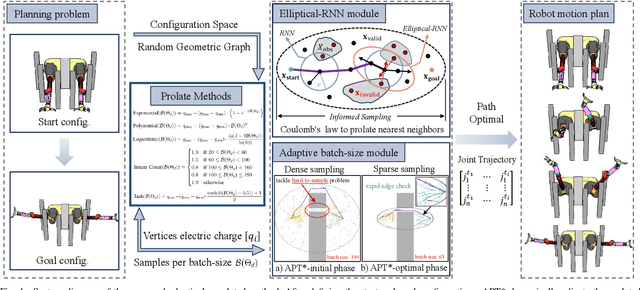
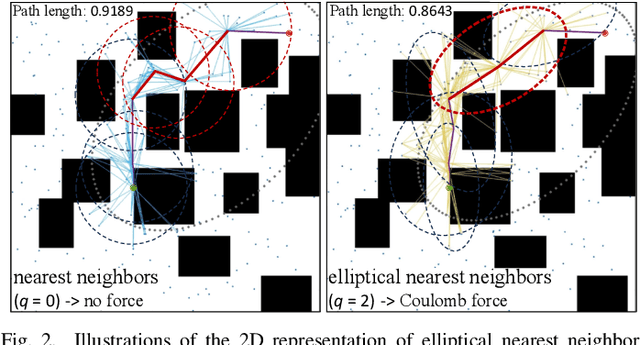
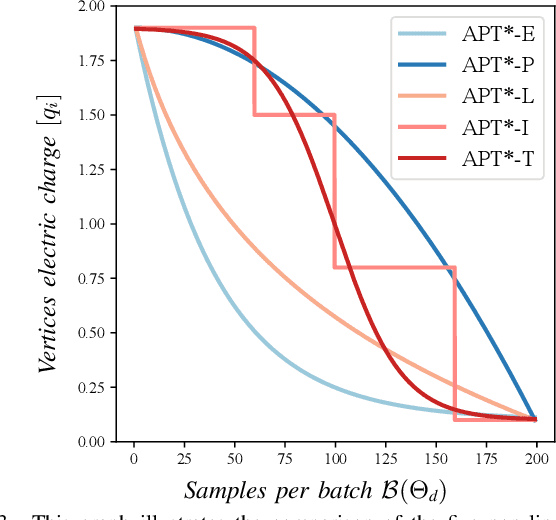
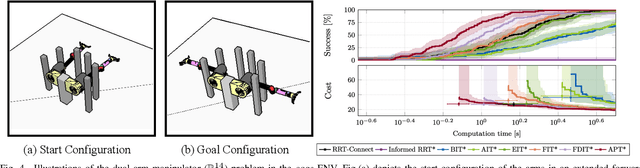
Optimal path planning aims to determine a sequence of states from a start to a goal while accounting for planning objectives. Popular methods often integrate fixed batch sizes and neglect information on obstacles, which is not problem-specific. This study introduces Adaptively Prolated Trees (APT*), a novel sampling-based motion planner that extends based on Force Direction Informed Trees (FDIT*), integrating adaptive batch-sizing and elliptical $r$-nearest neighbor modules to dynamically modulate the path searching process based on environmental feedback. APT* adjusts batch sizes based on the hypervolume of the informed sets and considers vertices as electric charges that obey Coulomb's law to define virtual forces via neighbor samples, thereby refining the prolate nearest neighbor selection. These modules employ non-linear prolate methods to adaptively adjust the electric charges of vertices for force definition, thereby improving the convergence rate with lower solution costs. Comparative analyses show that APT* outperforms existing single-query sampling-based planners in dimensions from $\mathbb{R}^4$ to $\mathbb{R}^{16}$, and it was further validated through a real-world robot manipulation task. A video showcasing our experimental results is available at: https://youtu.be/gCcUr8LiEw4
Capsizing-Guided Trajectory Optimization for Autonomous Navigation with Rough Terrain
Aug 11, 2025It is a challenging task for ground robots to autonomously navigate in harsh environments due to the presence of non-trivial obstacles and uneven terrain. This requires trajectory planning that balances safety and efficiency. The primary challenge is to generate a feasible trajectory that prevents robot from tip-over while ensuring effective navigation. In this paper, we propose a capsizing-aware trajectory planner (CAP) to achieve trajectory planning on the uneven terrain. The tip-over stability of the robot on rough terrain is analyzed. Based on the tip-over stability, we define the traversable orientation, which indicates the safe range of robot orientations. This orientation is then incorporated into a capsizing-safety constraint for trajectory optimization. We employ a graph-based solver to compute a robust and feasible trajectory while adhering to the capsizing-safety constraint. Extensive simulation and real-world experiments validate the effectiveness and robustness of the proposed method. The results demonstrate that CAP outperforms existing state-of-the-art approaches, providing enhanced navigation performance on uneven terrains.
Embodied Perception for Test-time Grasping Detection Adaptation with Knowledge Infusion
Apr 07, 2025



It has always been expected that a robot can be easily deployed to unknown scenarios, accomplishing robotic grasping tasks without human intervention. Nevertheless, existing grasp detection approaches are typically off-body techniques and are realized by training various deep neural networks with extensive annotated data support. {In this paper, we propose an embodied test-time adaptation framework for grasp detection that exploits the robot's exploratory capabilities.} The framework aims to improve the generalization performance of grasping skills for robots in an unforeseen environment. Specifically, we introduce embodied assessment criteria based on the robot's manipulation capability to evaluate the quality of the grasp detection and maintain suitable samples. This process empowers the robots to actively explore the environment and continuously learn grasping skills, eliminating human intervention. Besides, to improve the efficiency of robot exploration, we construct a flexible knowledge base to provide context of initial optimal viewpoints. Conditioned on the maintained samples, the grasp detection networks can be adapted in the test-time scene. When the robot confronts new objects, it will undergo the same adaptation procedure mentioned above to realize continuous learning. Extensive experiments conducted on a real-world robot demonstrate the effectiveness and generalization of our proposed framework.