 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Time-Series Foundation Models Deployment-Ready? A Systematic Study of Adversarial Robustness Across Domains
May 26, 2025Time Series Foundation Models (TSFMs), which are pretrained on large-scale, cross-domain data and capable of zero-shot forecasting in new scenarios without further training, are increasingly adopted in real-world applications. However, as the zero-shot forecasting paradigm gets popular, a critical yet overlooked question emerges: Are TSFMs robust to adversarial input perturbations? Such perturbations could be exploited in man-in-the-middle attacks or data poisoning. To address this gap, we conduct a systematic investigation into the adversarial robustness of TSFMs. Our results show that even minimal perturbations can induce significant and controllable changes in forecast behaviors, including trend reversal, temporal drift, and amplitude shift, posing serious risks to TSFM-based services. Through experiments on representative TSFMs and multiple datasets, we reveal their consistent vulnerabilities and identify potential architectural designs, such as structural sparsity and multi-task pretraining, that may improve robustness. Our findings offer actionable guidance for designing more resilient forecasting systems and provide a critical assessment of the adversarial robustness of TSFMs.
LUIEO: A Lightweight Model for Integrating Underwater Image Enhancement and Object Detection
Dec 01, 2024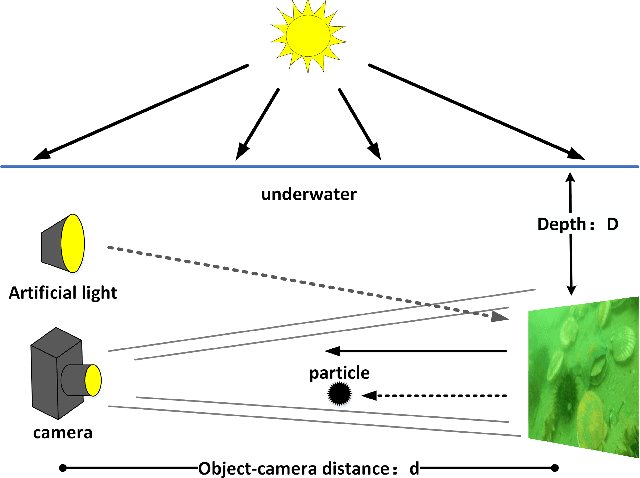
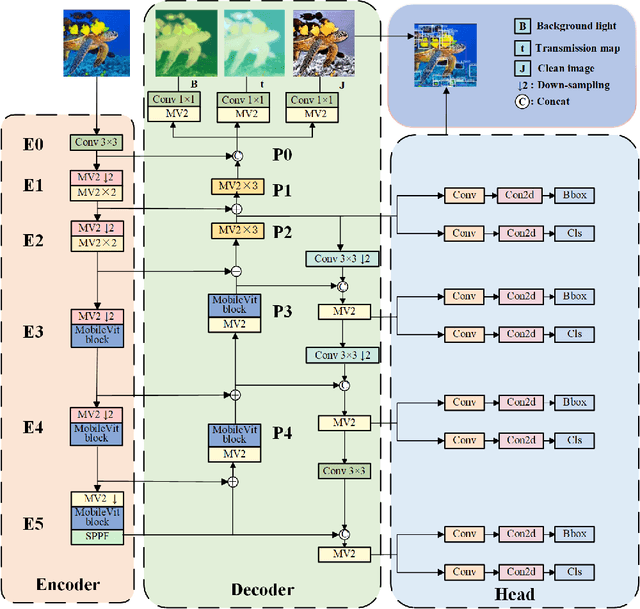
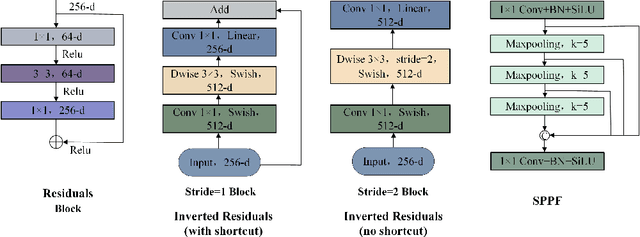
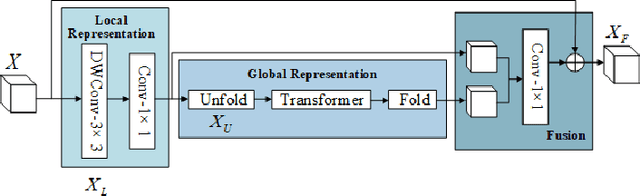
Underwater optical images inevitably suffer from various degradation factors such as blurring, low contrast, and color distortion, which hinder the accuracy of object detection tasks. Due to the lack of paired underwater/clean images, most research methods adopt a strategy of first enhancing and then detecting, resulting in a lack of feature communication between the two learning tasks. On the other hand, due to the contradiction between the diverse degradation factors of underwater images and the limited number of samples, existing underwater enhancement methods are difficult to effectively enhance degraded images of unknown water bodies, thereby limiting the improvement of object detection accuracy. Therefore, most underwater target detection results are still displayed on degraded images, making it difficult to visually judge the correctness of the detection results. To address the above issues, this paper proposes a multi-task learning method that simultaneously enhances underwater images and improves detection accuracy. Compared with single-task learning, the integrated model allows for the dynamic adjustment of information communication and sharing between different tasks. Due to the fact that real underwater images can only provide annotated object labels, this paper introduces physical constraints to ensure that object detection tasks do not interfere with image enhancement tasks. Therefore, this article introduces a physical module to decompose underwater images into clean images, background light, and transmission images and uses a physical model to calculate underwater images for self-supervision. Numerical experiments demonstrate that the proposed model achieves satisfactory results in visual performance, object detection accuracy, and detection efficiency compared to state-of-the-art comparative methods.
See it, Think it, Sorted: Large Multimodal Models are Few-shot Time Series Anomaly Analyzers
Nov 04, 2024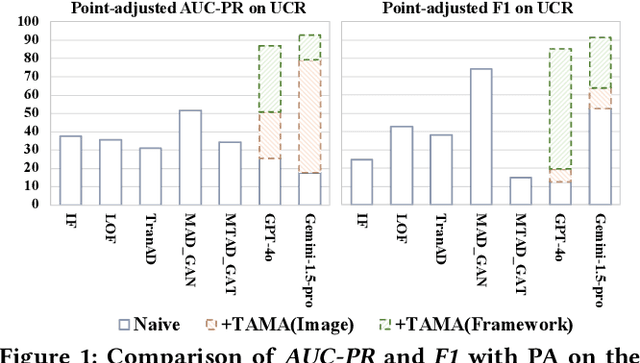

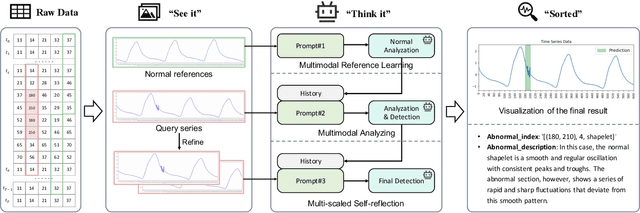

Time series anomaly detection (TSAD) is becoming increasingly vital due to the rapid growth of time series data across various sectors. Anomalies in web service data, for example, can signal critical incidents such as system failures or server malfunctions, necessitating timely detection and response. However, most existing TSAD methodologies rely heavily on manual feature engineering or require extensive labeled training data, while also offering limited interpretability. To address these challenges, we introduce a pioneering framework called the Time Series Anomaly Multimodal Analyzer (TAMA), which leverages the power of Large Multimodal Models (LMMs) to enhance both the detection and interpretation of anomalies in time series data. By converting time series into visual formats that LMMs can efficiently process, TAMA leverages few-shot in-context learning capabilities to reduce dependence on extensive labeled datasets. Our methodology is validated through rigorous experimentation on multiple real-world datasets, where TAMA consistently outperforms state-of-the-art methods in TSAD tasks. Additionally, TAMA provides rich, natural language-based semantic analysis, offering deeper insights into the nature of detected anomalies. Furthermore, we contribute one of the first open-source datasets that includes anomaly detection labels, anomaly type labels, and contextual description, facilitating broader exploration and advancement within this critical field. Ultimately, TAMA not only excels in anomaly detection but also provides a comprehensive approach for understanding the underlying causes of anomalies, pushing TSAD forward through innovative methodologies and insights.
Optical Flow Representation Alignment Mamba Diffusion Model for Medical Video Generation
Nov 03, 2024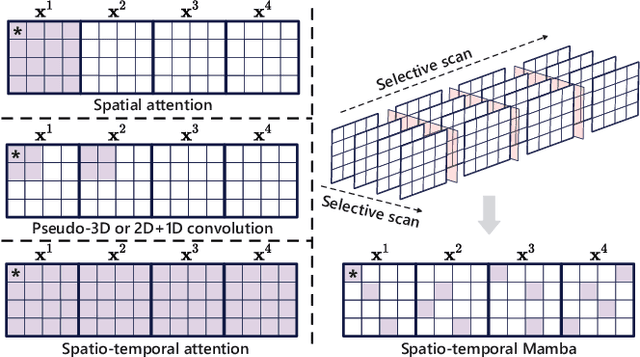
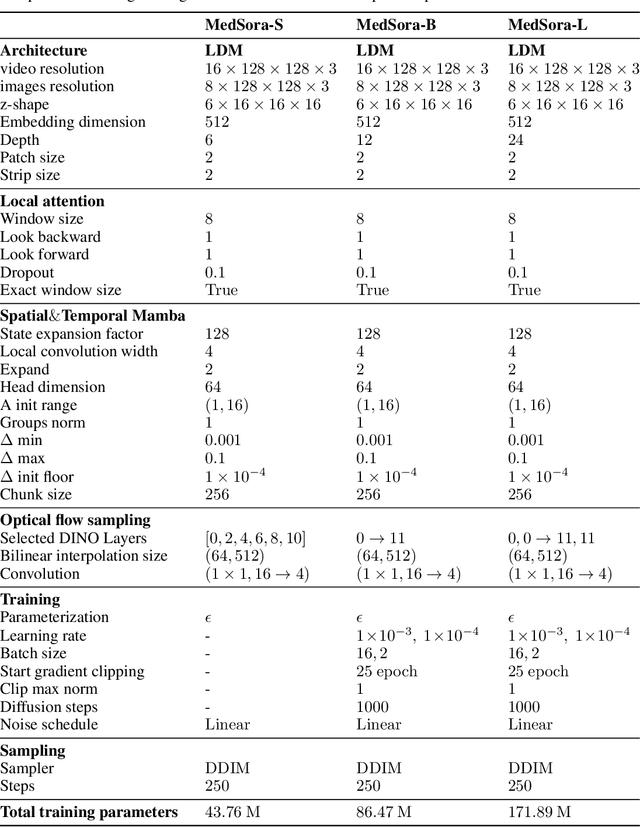
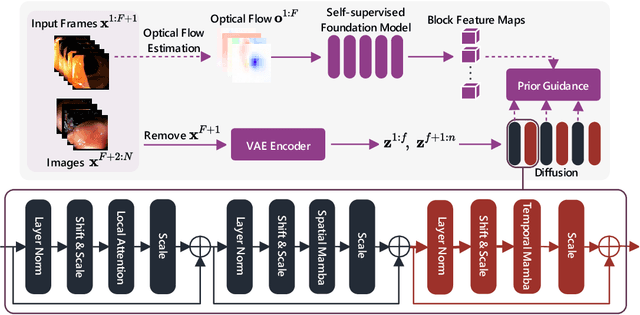
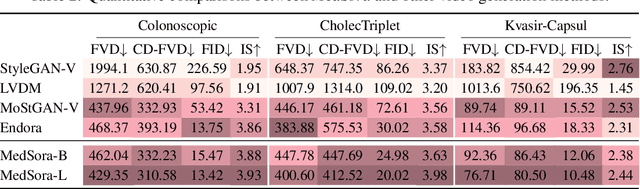
Medical video generation models are expected to have a profound impact on the healthcare industry, including but not limited to medical education and training, surgical planning, and simulation. Current video diffusion models typically build on image diffusion architecture by incorporating temporal operations (such as 3D convolution and temporal attention). Although this approach is effective, its oversimplification limits spatio-temporal performance and consumes substantial computational resources. To counter this, we propose Medical Simulation Video Generator (MedSora), which incorporates three key elements: i) a video diffusion framework integrates the advantages of attention and Mamba, balancing low computational load with high-quality video generation, ii) an optical flow representation alignment method that implicitly enhances attention to inter-frame pixels, and iii) a video variational autoencoder (VAE) with frequency compensation addresses the information loss of medical features that occurs when transforming pixel space into latent features and then back to pixel frames. Extensive experiments and applications demonstrate that MedSora exhibits superior visual quality in generating medical videos, outperforming the most advanced baseline methods. Further results and code are available at https://wongzbb.github.io/MedSora
AnyTaskTune: Advanced Domain-Specific Solutions through Task-Fine-Tuning
Jul 09, 2024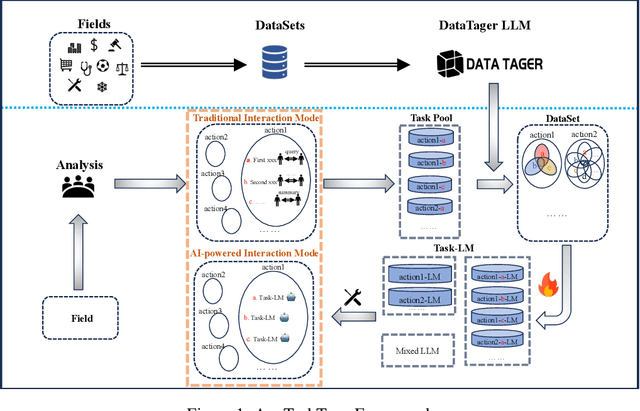
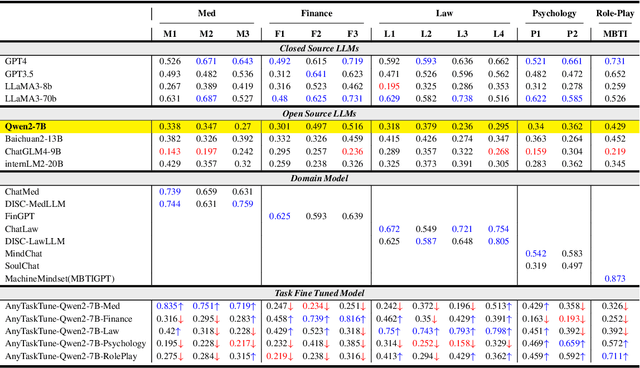


The pervasive deployment of Large Language Models-LLMs in various sectors often neglects the nuanced requirements of individuals and small organizations, who benefit more from models precisely tailored to their specific business contexts rather than those with broadly superior general capabilities. This work introduces \textbf{AnyTaskTune}, a novel fine-tuning methodology coined as \textbf{Task-Fine-Tune}, specifically developed to elevate model performance on a diverse array of domain-specific tasks. This method involves a meticulous process to identify and define targeted sub-tasks within a domain, followed by the creation of specialized enhancement datasets for fine-tuning, thereby optimizing task-specific model performance. We conducted comprehensive fine-tuning experiments not only in the legal domain for tasks such as keyword extraction and sentence prediction but across over twenty different sub-tasks derived from the domains of finance, healthcare, law, psychology, consumer services, and human resources. To substantiate our approach and facilitate community engagement, we will open-source these bilingual task datasets. Our findings demonstrate that models fine-tuned using the \textbf{Task-Fine-Tune} methodology not only achieve superior performance on these specific tasks but also significantly outperform models with higher general capabilities in their respective domains. Our work is publicly available at \url{https://github.com/PandaVT/DataTager}.
Soft Masked Mamba Diffusion Model for CT to MRI Conversion
Jun 22, 2024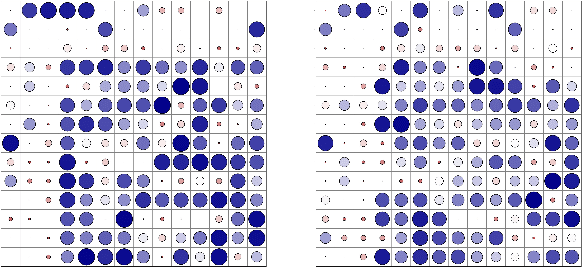
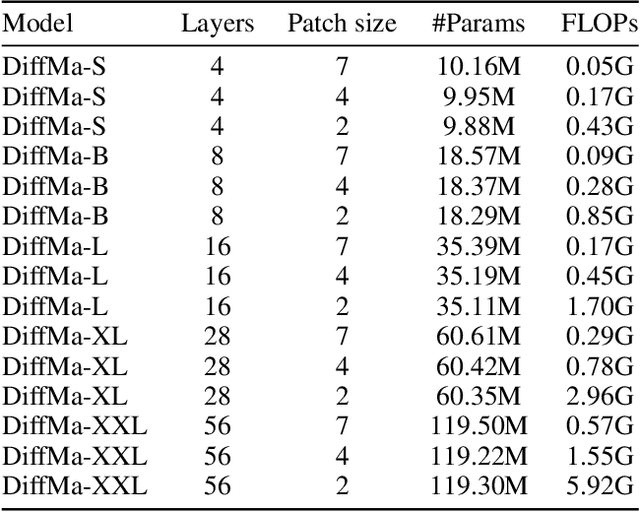
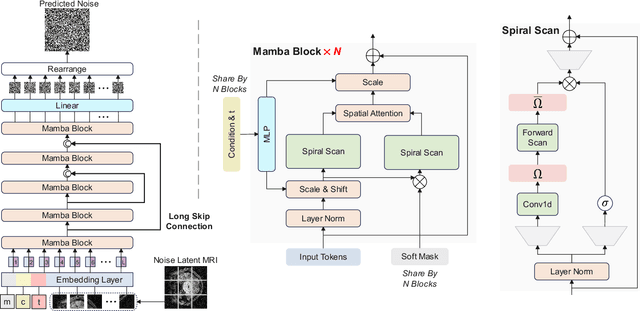
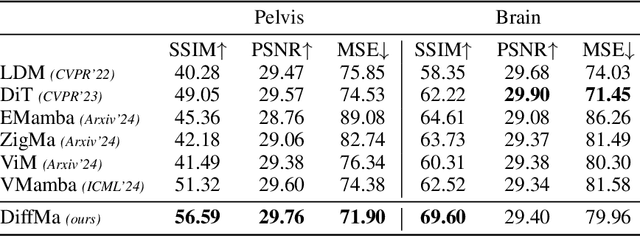
Magnetic Resonance Imaging (MRI) and Computed Tomography (CT) are the predominant modalities utilized in the field of medical imaging. Although MRI capture the complexity of anatomical structures with greater detail than CT, it entails a higher financial costs and requires longer image acquisition times. In this study, we aim to train latent diffusion model for CT to MRI conversion, replacing the commonly-used U-Net or Transformer backbone with a State-Space Model (SSM) called Mamba that operates on latent patches. First, we noted critical oversights in the scan scheme of most Mamba-based vision methods, including inadequate attention to the spatial continuity of patch tokens and the lack of consideration for their varying importance to the target task. Secondly, extending from this insight, we introduce Diffusion Mamba (DiffMa), employing soft masked to integrate Cross-Sequence Attention into Mamba and conducting selective scan in a spiral manner. Lastly, extensive experiments demonstrate impressive performance by DiffMa in medical image generation tasks, with notable advantages in input scaling efficiency over existing benchmark models. The code and models are available at https://github.com/wongzbb/DiffMa-Diffusion-Mamba
PCLMix: Weakly Supervised Medical Image Segmentation via Pixel-Level Contrastive Learning and Dynamic Mix Augmentation
May 10, 2024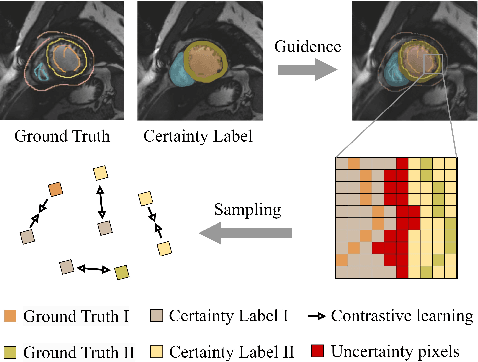
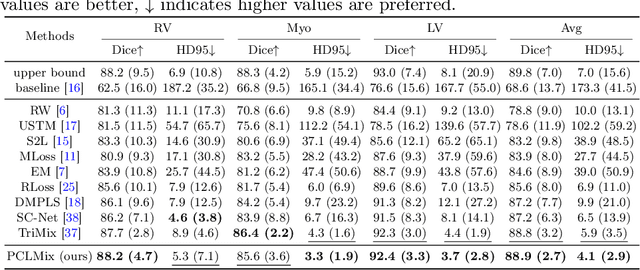
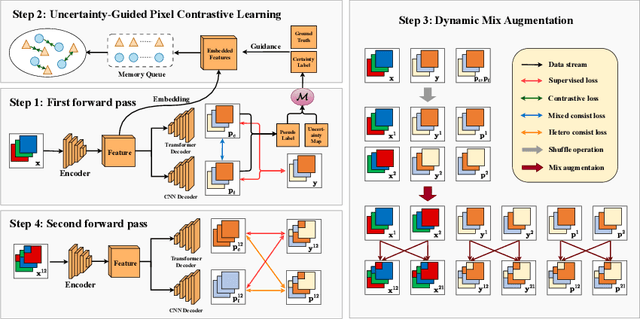
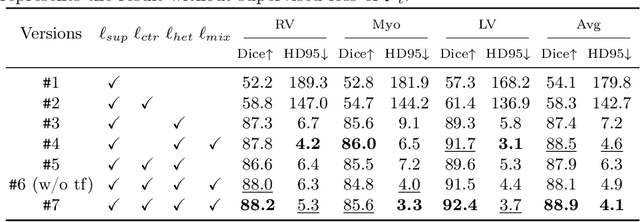
In weakly supervised medical image segmentation, the absence of structural priors and the discreteness of class feature distribution present a challenge, i.e., how to accurately propagate supervision signals from local to global regions without excessively spreading them to other irrelevant regions? To address this, we propose a novel weakly supervised medical image segmentation framework named PCLMix, comprising dynamic mix augmentation, pixel-level contrastive learning, and consistency regularization strategies. Specifically, PCLMix is built upon a heterogeneous dual-decoder backbone, addressing the absence of structural priors through a strategy of dynamic mix augmentation during training. To handle the discrete distribution of class features, PCLMix incorporates pixel-level contrastive learning based on prediction uncertainty, effectively enhancing the model's ability to differentiate inter-class pixel differences and intra-class consistency. Furthermore, to reinforce segmentation consistency and robustness, PCLMix employs an auxiliary decoder for dual consistency regularization. In the inference phase, the auxiliary decoder will be dropped and no computation complexity is increased. Extensive experiments on the ACDC dataset demonstrate that PCLMix appropriately propagates local supervision signals to the global scale, further narrowing the gap between weakly supervised and fully supervised segmentation methods. Our code is available at https://github.com/Torpedo2648/PCLMix.
Unravel Anomalies: An End-to-end Seasonal-Trend Decomposition Approach for Time Series Anomaly Detection
Sep 30, 2023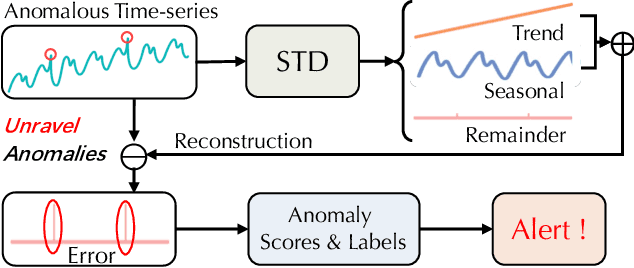



Traditional Time-series Anomaly Detection (TAD) methods often struggle with the composite nature of complex time-series data and a diverse array of anomalies. We introduce TADNet, an end-to-end TAD model that leverages Seasonal-Trend Decomposition to link various types of anomalies to specific decomposition components, thereby simplifying the analysis of complex time-series and enhancing detection performance. Our training methodology, which includes pre-training on a synthetic dataset followed by fine-tuning, strikes a balance between effective decomposition and precise anomaly detection. Experimental validation on real-world datasets confirms TADNet's state-of-the-art performance across a diverse range of anomalies.
SageFormer: Series-Aware Graph-Enhanced Transformers for Multivariate Time Series Forecasting
Jul 04, 2023



Multivariate time series forecasting plays a critical role in diverse domains. While recent advancements in deep learning methods, especially Transformers, have shown promise, there remains a gap in addressing the significance of inter-series dependencies. This paper introduces SageFormer, a Series-aware Graph-enhanced Transformer model designed to effectively capture and model dependencies between series using graph structures. SageFormer tackles two key challenges: effectively representing diverse temporal patterns across series and mitigating redundant information among series. Importantly, the proposed series-aware framework seamlessly integrates with existing Transformer-based models, augmenting their ability to model inter-series dependencies. Through extensive experiments on real-world and synthetic datasets, we showcase the superior performance of SageFormer compared to previous state-of-the-art approaches.
Bridge the Performance Gap in Peak-hour Series Forecasting: The Seq2Peak Framework
Jul 04, 2023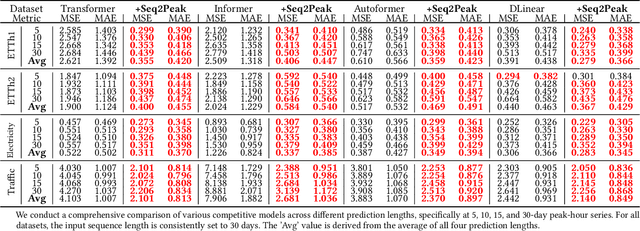
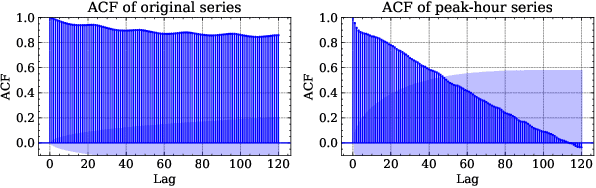
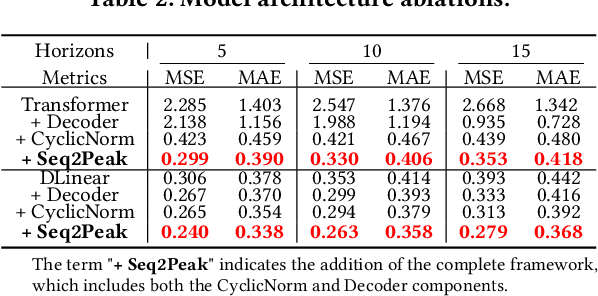
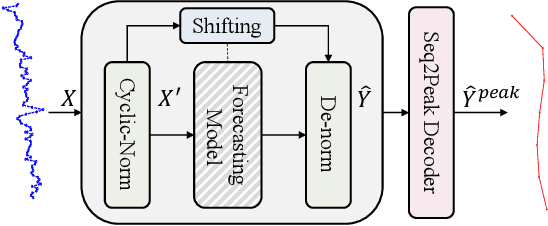
Peak-Hour Series Forecasting (PHSF) is a crucial yet underexplored task in various domains. While state-of-the-art deep learning models excel in regular Time Series Forecasting (TSF), they struggle to achieve comparable results in PHSF. This can be attributed to the challenges posed by the high degree of non-stationarity in peak-hour series, which makes direct forecasting more difficult than standard TSF. Additionally, manually extracting the maximum value from regular forecasting results leads to suboptimal performance due to models minimizing the mean deficit. To address these issues, this paper presents Seq2Peak, a novel framework designed specifically for PHSF tasks, bridging the performance gap observed in TSF models. Seq2Peak offers two key components: the CyclicNorm pipeline to mitigate the non-stationarity issue, and a simple yet effective trainable-parameter-free peak-hour decoder with a hybrid loss function that utilizes both the original series and peak-hour series as supervised signals. Extensive experimentation on publicly available time series datasets demonstrates the effectiveness of the proposed framework, yielding a remarkable average relative improvement of 37.7\% across four real-world datasets for both transformer- and non-transformer-based TSF models.