 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Masked Mamba Diffusion Model for CT to MRI Conversion
Paper and Code
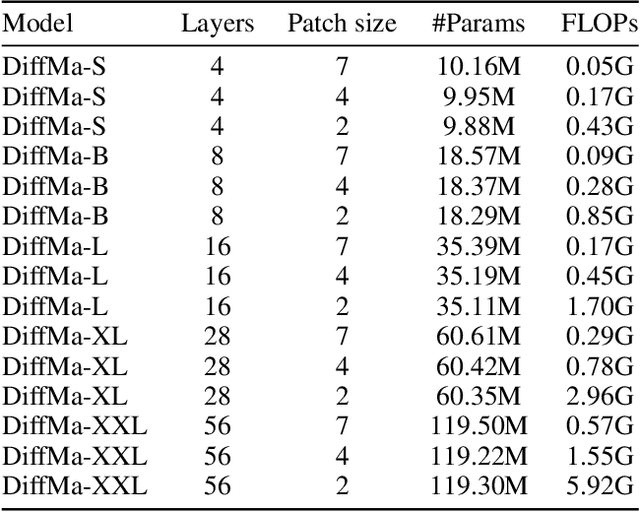
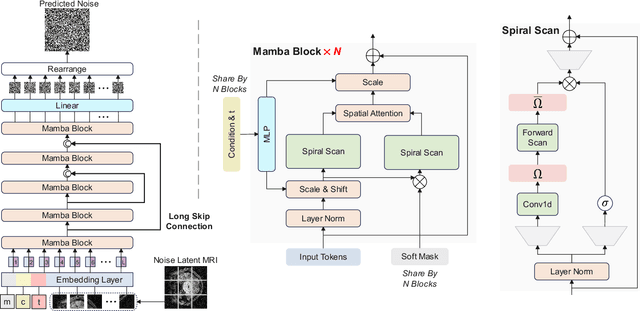
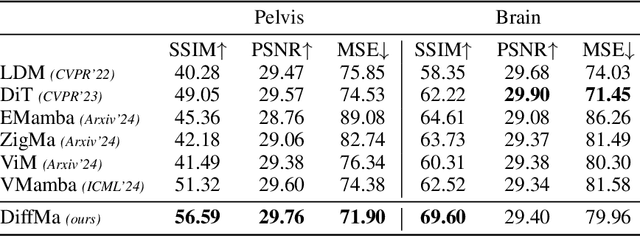
Magnetic Resonance Imaging (MRI) and Computed Tomography (CT) are the predominant modalities utilized in the field of medical imaging. Although MRI capture the complexity of anatomical structures with greater detail than CT, it entails a higher financial costs and requires longer image acquisition times. In this study, we aim to train latent diffusion model for CT to MRI conversion, replacing the commonly-used U-Net or Transformer backbone with a State-Space Model (SSM) called Mamba that operates on latent patches. First, we noted critical oversights in the scan scheme of most Mamba-based vision methods, including inadequate attention to the spatial continuity of patch tokens and the lack of consideration for their varying importance to the target task. Secondly, extending from this insight, we introduce Diffusion Mamba (DiffMa), employing soft masked to integrate Cross-Sequence Attention into Mamba and conducting selective scan in a spiral manner. Lastly, extensive experiments demonstrate impressive performance by DiffMa in medical image generation tasks, with notable advantages in input scaling efficiency over existing benchmark models. The code and models are available at https://github.com/wongzbb/DiffMa-Diffusion-Mamba