 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptical Flow Representation Alignment Mamba Diffusion Model for Medical Video Generation
Nov 03, 2024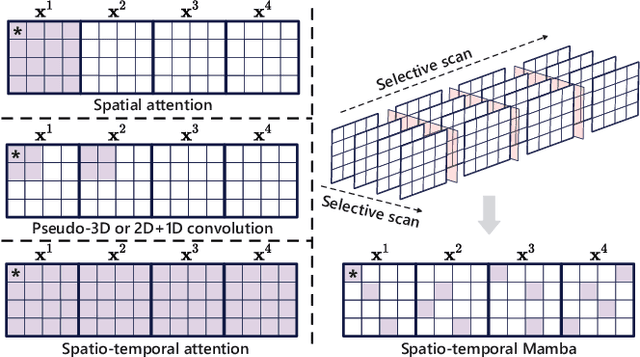
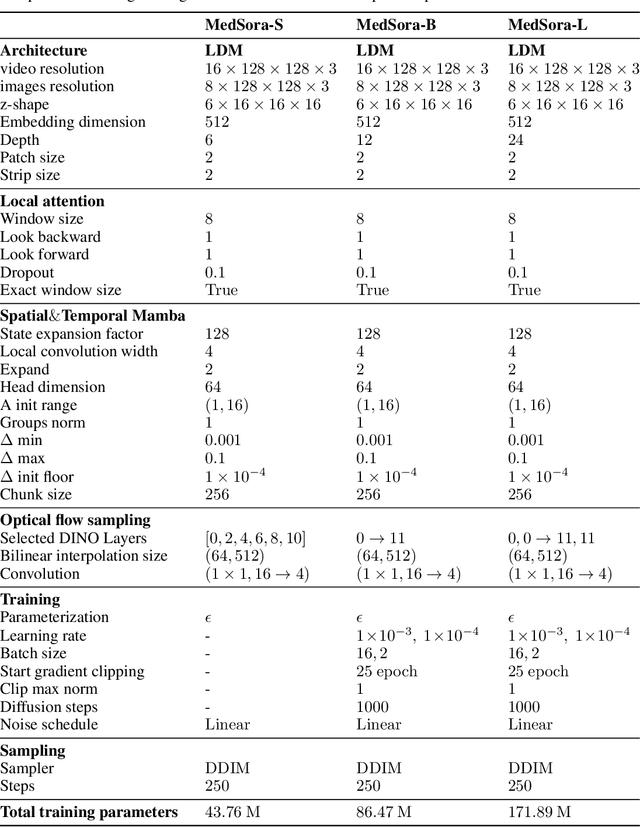
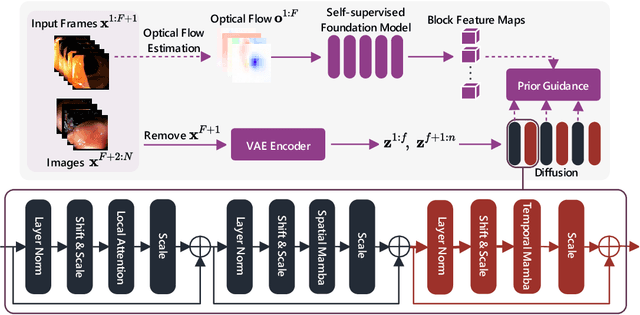
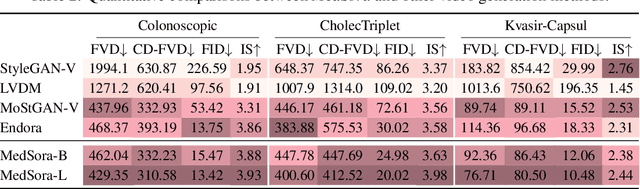
Medical video generation models are expected to have a profound impact on the healthcare industry, including but not limited to medical education and training, surgical planning, and simulation. Current video diffusion models typically build on image diffusion architecture by incorporating temporal operations (such as 3D convolution and temporal attention). Although this approach is effective, its oversimplification limits spatio-temporal performance and consumes substantial computational resources. To counter this, we propose Medical Simulation Video Generator (MedSora), which incorporates three key elements: i) a video diffusion framework integrates the advantages of attention and Mamba, balancing low computational load with high-quality video generation, ii) an optical flow representation alignment method that implicitly enhances attention to inter-frame pixels, and iii) a video variational autoencoder (VAE) with frequency compensation addresses the information loss of medical features that occurs when transforming pixel space into latent features and then back to pixel frames. Extensive experiments and applications demonstrate that MedSora exhibits superior visual quality in generating medical videos, outperforming the most advanced baseline methods. Further results and code are available at https://wongzbb.github.io/MedSora
LanDA: Language-Guided Multi-Source Domain Adaptation
Jan 25, 2024Multi-Source Domain Adaptation (MSDA) aims to mitigate changes in data distribution when transferring knowledge from multiple labeled source domains to an unlabeled target domain. However, existing MSDA techniques assume target domain images are available, yet overlook image-rich semantic information. Consequently, an open question is whether MSDA can be guided solely by textual cues in the absence of target domain images. By employing a multimodal model with a joint image and language embedding space, we propose a novel language-guided MSDA approach, termed LanDA, based on optimal transfer theory, which facilitates the transfer of multiple source domains to a new target domain, requiring only a textual description of the target domain without needing even a single target domain image, while retaining task-relevant information. We present extensive experiments across different transfer scenarios using a suite of relevant benchmarks, demonstrating that LanDA outperforms standard fine-tuning and ensemble approaches in both target and source domains.