 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAirSpatialBot: A Spatially-Aware Aerial Agent for Fine-Grained Vehicle Attribute Recognization and Retrieval
Jan 04, 2026Despite notable advancements in remote sensing vision-language models (VLMs), existing models often struggle with spatial understanding, limiting their effectiveness in real-world applications. To push the boundaries of VLMs in remote sensing, we specifically address vehicle imagery captured by drones and introduce a spatially-aware dataset AirSpatial, which comprises over 206K instructions and introduces two novel tasks: Spatial Grounding and Spatial Question Answering. It is also the first remote sensing grounding dataset to provide 3DBB. To effectively leverage existing image understanding of VLMs to spatial domains, we adopt a two-stage training strategy comprising Image Understanding Pre-training and Spatial Understanding Fine-tuning. Utilizing this trained spatially-aware VLM, we develop an aerial agent, AirSpatialBot, which is capable of fine-grained vehicle attribute recognition and retrieval. By dynamically integrating task planning, image understanding, spatial understanding, and task execution capabilities, AirSpatialBot adapts to diverse query requirements. Experimental results validate the effectiveness of our approach, revealing the spatial limitations of existing VLMs while providing valuable insights. The model, code, and datasets will be released at https://github.com/VisionXLab/AirSpatialBot
DVGBench: Implicit-to-Explicit Visual Grounding Benchmark in UAV Imagery with Large Vision-Language Models
Jan 02, 2026Remote sensing (RS) large vision-language models (LVLMs) have shown strong promise across visual grounding (VG) tasks. However, existing RS VG datasets predominantly rely on explicit referring expressions-such as relative position, relative size, and color cues-thereby constraining performance on implicit VG tasks that require scenario-specific domain knowledge. This article introduces DVGBench, a high-quality implicit VG benchmark for drones, covering six major application scenarios: traffic, disaster, security, sport, social activity, and productive activity. Each object provides both explicit and implicit queries. Based on the dataset, we design DroneVG-R1, an LVLM that integrates the novel Implicit-to-Explicit Chain-of-Thought (I2E-CoT) within a reinforcement learning paradigm. This enables the model to take advantage of scene-specific expertise, converting implicit references into explicit ones and thus reducing grounding difficulty. Finally, an evaluation of mainstream models on both explicit and implicit VG tasks reveals substantial limitations in their reasoning capabilities. These findings provide actionable insights for advancing the reasoning capacity of LVLMs for drone-based agents. The code and datasets will be released at https://github.com/zytx121/DVGBench
Narrative-Driven Travel Planning: Geoculturally-Grounded Script Generation with Evolutionary Itinerary Optimization
Feb 20, 2025To enhance tourists' experiences and immersion, this paper proposes a narrative-driven travel planning framework called NarrativeGuide, which generates a geoculturally-grounded narrative script for travelers, offering a novel, role-playing experience for their journey. In the initial stage, NarrativeGuide constructs a knowledge graph for attractions within a city, then configures the worldview, character setting, and exposition based on the knowledge graph. Using this foundation, the knowledge graph is combined to generate an independent scene unit for each attraction. During the itinerary planning stage, NarrativeGuide models narrative-driven travel planning as an optimization problem, utilizing a genetic algorithm (GA) to refine the itinerary. Before evaluating the candidate itinerary, transition scripts are generated for each pair of adjacent attractions, which, along with the scene units, form a complete script. The weighted sum of script coherence, travel time, and attraction scores is then used as the fitness value to update the candidate solution set. Experimental results across four cities, i.e., Nanjing and Yangzhou in China, Paris in France, and Berlin in Germany, demonstrate significant improvements in narrative coherence and cultural fit, alongside a notable reduction in travel time and an increase in the quality of visited attractions. Our study highlights that incorporating external evolutionary optimization effectively addresses the limitations of large language models in travel planning.Our codes are available at https://github.com/Evan01225/Narrative-Driven-Travel-Planning.
TARGO: Benchmarking Target-driven Object Grasping under Occlusions
Jul 08, 2024Recent advances in predicting 6D grasp poses from a single depth image have led to promising performance in robotic grasping. However, previous grasping models face challenges in cluttered environments where nearby objects impact the target object's grasp. In this paper, we first establish a new benchmark dataset for TARget-driven Grasping under Occlusions, named TARGO. We make the following contributions: 1) We are the first to study the occlusion level of grasping. 2) We set up an evaluation benchmark consisting of large-scale synthetic data and part of real-world data, and we evaluated five grasp models and found that even the current SOTA model suffers when the occlusion level increases, leaving grasping under occlusion still a challenge. 3) We also generate a large-scale training dataset via a scalable pipeline, which can be used to boost the performance of grasping under occlusion and generalized to the real world. 4) We further propose a transformer-based grasping model involving a shape completion module, termed TARGO-Net, which performs most robustly as occlusion increases. Our benchmark dataset can be found at https://TARGO-benchmark.github.io/.
BezierFormer: A Unified Architecture for 2D and 3D Lane Detection
Apr 25, 2024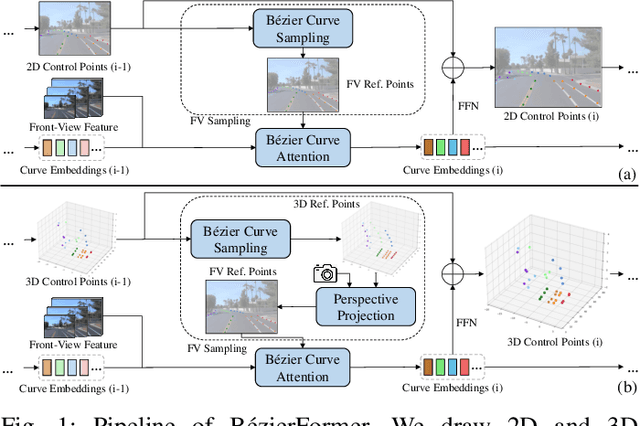
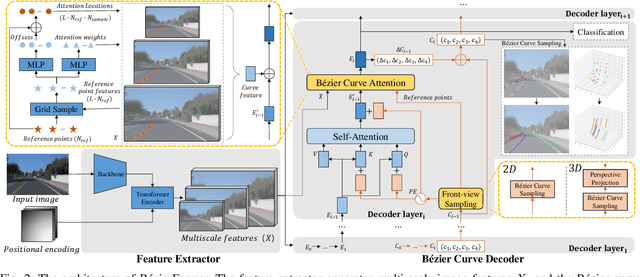
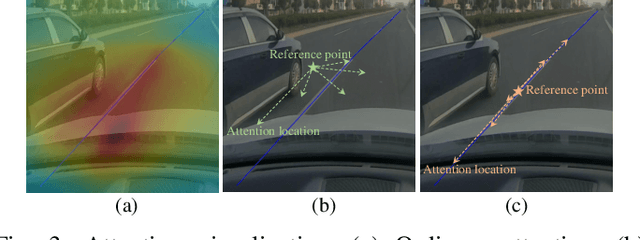

Lane detection has made significant progress in recent years, but there is not a unified architecture for its two sub-tasks: 2D lane detection and 3D lane detection. To fill this gap, we introduce B\'{e}zierFormer, a unified 2D and 3D lane detection architecture based on B\'{e}zier curve lane representation. B\'{e}zierFormer formulate queries as B\'{e}zier control points and incorporate a novel B\'{e}zier curve attention mechanism. This attention mechanism enables comprehensive and accurate feature extraction for slender lane curves via sampling and fusing multiple reference points on each curve. In addition, we propose a novel Chamfer IoU-based loss which is more suitable for the B\'{e}zier control points regression. The state-of-the-art performance of B\'{e}zierFormer on widely-used 2D and 3D lane detection benchmarks verifies its effectiveness and suggests the worthiness of further exploration.
Unravel Anomalies: An End-to-end Seasonal-Trend Decomposition Approach for Time Series Anomaly Detection
Sep 30, 2023Traditional Time-series Anomaly Detection (TAD) methods often struggle with the composite nature of complex time-series data and a diverse array of anomalies. We introduce TADNet, an end-to-end TAD model that leverages Seasonal-Trend Decomposition to link various types of anomalies to specific decomposition components, thereby simplifying the analysis of complex time-series and enhancing detection performance. Our training methodology, which includes pre-training on a synthetic dataset followed by fine-tuning, strikes a balance between effective decomposition and precise anomaly detection. Experimental validation on real-world datasets confirms TADNet's state-of-the-art performance across a diverse range of anomalies.
Topic Modeling with Wasserstein Autoencoders
Jul 24, 2019
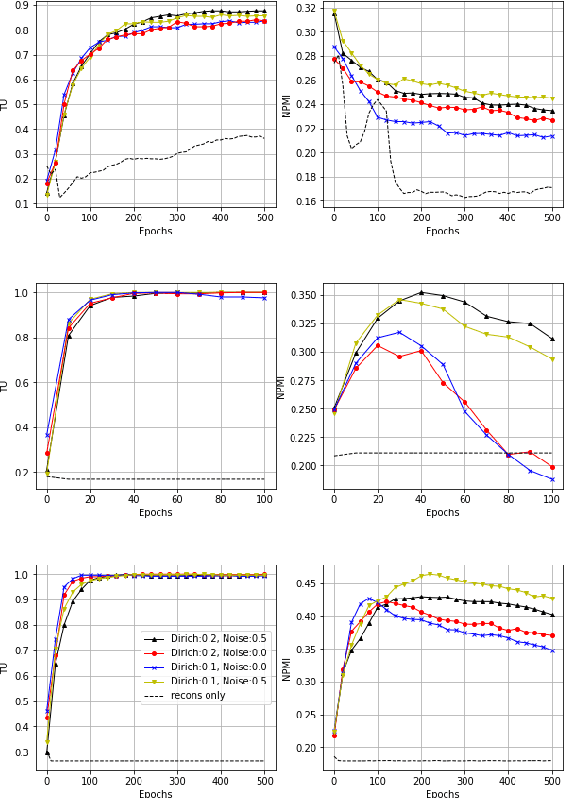


We propose a novel neural topic model in the Wasserstein autoencoders (WAE) framework. Unlike existing variational autoencoder based models, we directly enforce Dirichlet prior on the latent document-topic vectors. We exploit the structure of the latent space and apply a suitable kernel in minimizing the Maximum Mean Discrepancy (MMD) to perform distribution matching. We discover that MMD performs much better than the Generative Adversarial Network (GAN) in matching high dimensional Dirichlet distribution. We further discover that incorporating randomness in the encoder output during training leads to significantly more coherent topics. To measure the diversity of the produced topics, we propose a simple topic uniqueness metric. Together with the widely used coherence measure NPMI, we offer a more wholistic evaluation of topic quality. Experiments on several real datasets show that our model produces significantly better topics than existing topic models.
Coherence-Aware Neural Topic Modeling
Sep 07, 2018



Topic models are evaluated based on their ability to describe documents well (i.e. low perplexity) and to produce topics that carry coherent semantic meaning. In topic modeling so far, perplexity is a direct optimization target. However, topic coherence, owing to its challenging computation, is not optimized for and is only evaluated after training. In this work, under a neural variational inference framework, we propose methods to incorporate a topic coherence objective into the training process. We demonstrate that such a coherence-aware topic model exhibits a similar level of perplexity as baseline models but achieves substantially higher topic coherence.