 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHQOD: Harmonious Quantization for Object Detection
Aug 05, 2024

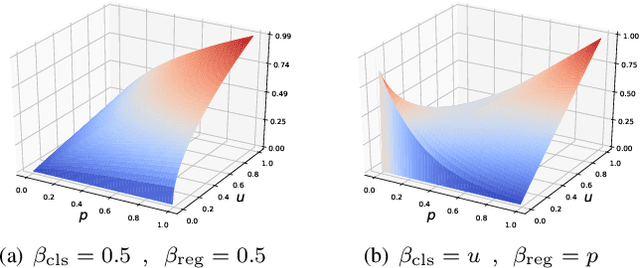
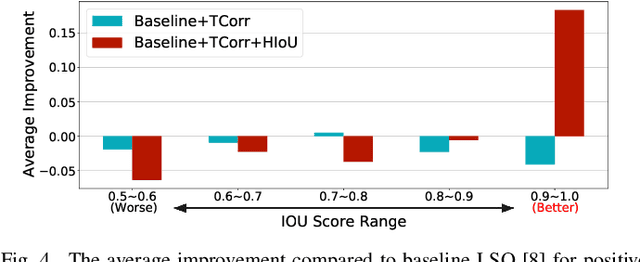
Task inharmony problem commonly occurs in modern object detectors, leading to inconsistent qualities between classification and regression tasks. The predicted boxes with high classification scores but poor localization positions or low classification scores but accurate localization positions will worsen the performance of detectors after Non-Maximum Suppression. Furthermore, when object detectors collaborate with Quantization-Aware Training (QAT), we observe that the task inharmony problem will be further exacerbated, which is considered one of the main causes of the performance degradation of quantized detectors. To tackle this issue, we propose the Harmonious Quantization for Object Detection (HQOD) framework, which consists of two components. Firstly, we propose a task-correlated loss to encourage detectors to focus on improving samples with lower task harmony quality during QAT. Secondly, a harmonious Intersection over Union (IoU) loss is incorporated to balance the optimization of the regression branch across different IoU levels. The proposed HQOD can be easily integrated into different QAT algorithms and detectors. Remarkably, on the MS COCO dataset, our 4-bit ATSS with ResNet-50 backbone achieves a state-of-the-art mAP of 39.6%, even surpassing the full-precision one.
BezierFormer: A Unified Architecture for 2D and 3D Lane Detection
Apr 25, 2024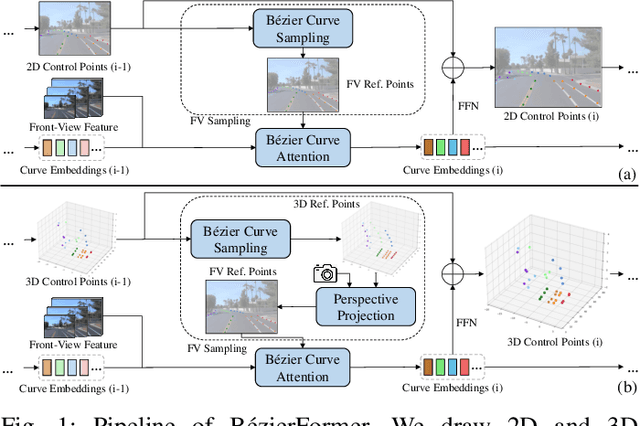
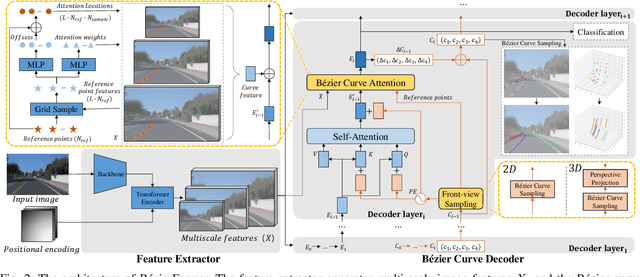
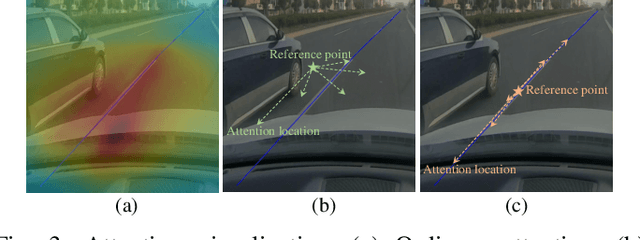

Lane detection has made significant progress in recent years, but there is not a unified architecture for its two sub-tasks: 2D lane detection and 3D lane detection. To fill this gap, we introduce B\'{e}zierFormer, a unified 2D and 3D lane detection architecture based on B\'{e}zier curve lane representation. B\'{e}zierFormer formulate queries as B\'{e}zier control points and incorporate a novel B\'{e}zier curve attention mechanism. This attention mechanism enables comprehensive and accurate feature extraction for slender lane curves via sampling and fusing multiple reference points on each curve. In addition, we propose a novel Chamfer IoU-based loss which is more suitable for the B\'{e}zier control points regression. The state-of-the-art performance of B\'{e}zierFormer on widely-used 2D and 3D lane detection benchmarks verifies its effectiveness and suggests the worthiness of further exploration.
QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models
Oct 12, 2023Large Language Models (LLMs) excel in NLP, but their demands hinder their widespread deployment. While Quantization-Aware Training (QAT) offers a solution, its extensive training costs make Post-Training Quantization (PTQ) a more practical approach for LLMs. In existing studies, activation outliers in particular channels are identified as the bottleneck to PTQ accuracy. They propose to transform the magnitudes from activations to weights, which however offers limited alleviation or suffers from unstable gradients, resulting in a severe performance drop at low-bitwidth. In this paper, we propose QLLM, an accurate and efficient low-bitwidth PTQ method designed for LLMs. QLLM introduces an adaptive channel reassembly technique that reallocates the magnitude of outliers to other channels, thereby mitigating their impact on the quantization range. This is achieved by channel disassembly and channel assembly, which first breaks down the outlier channels into several sub-channels to ensure a more balanced distribution of activation magnitudes. Then similar channels are merged to maintain the original channel number for efficiency. Additionally, an adaptive strategy is designed to autonomously determine the optimal number of sub-channels for channel disassembly. To further compensate for the performance loss caused by quantization, we propose an efficient tuning method that only learns a small number of low-rank weights while freezing the pre-trained quantized model. After training, these low-rank parameters can be fused into the frozen weights without affecting inference. Extensive experiments on LLaMA-1 and LLaMA-2 show that QLLM can obtain accurate quantized models efficiently. For example, QLLM quantizes the 4-bit LLaMA-2-70B within 10 hours on a single A100-80G GPU, outperforming the previous state-of-the-art method by 7.89% on the average accuracy across five zero-shot tasks.
NeMO: Neural Map Growing System for Spatiotemporal Fusion in Bird's-Eye-View and BDD-Map Benchmark
Jun 07, 2023

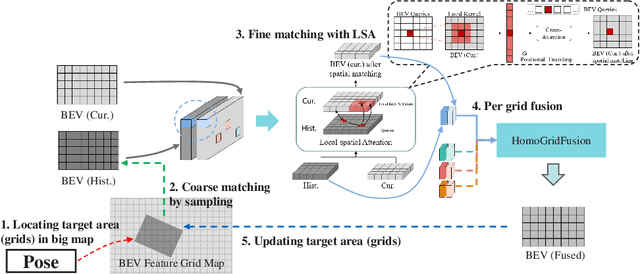

Vision-centric Bird's-Eye View (BEV) representation is essential for autonomous driving systems (ADS). Multi-frame temporal fusion which leverages historical information has been demonstrated to provide more comprehensive perception results. While most research focuses on ego-centric maps of fixed settings, long-range local map generation remains less explored. This work outlines a new paradigm, named NeMO, for generating local maps through the utilization of a readable and writable big map, a learning-based fusion module, and an interaction mechanism between the two. With an assumption that the feature distribution of all BEV grids follows an identical pattern, we adopt a shared-weight neural network for all grids to update the big map. This paradigm supports the fusion of longer time series and the generation of long-range BEV local maps. Furthermore, we release BDD-Map, a BDD100K-based dataset incorporating map element annotations, including lane lines, boundaries, and pedestrian crossing. Experiments on the NuScenes and BDD-Map datasets demonstrate that NeMO outperforms state-of-the-art map segmentation methods. We also provide a new scene-level BEV map evaluation setting along with the corresponding baseline for a more comprehensive comparison.
CentripetalNet: Pursuing High-quality Keypoint Pairs for Object Detection
Mar 20, 2020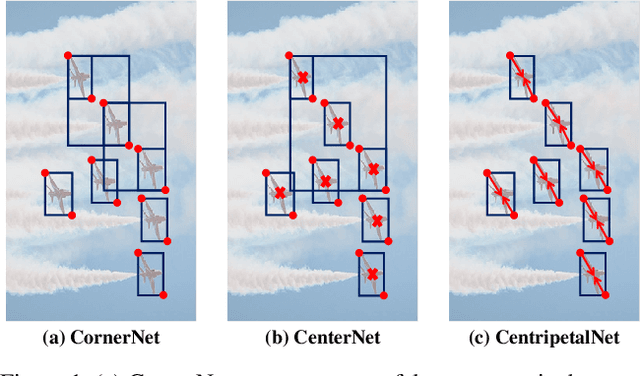
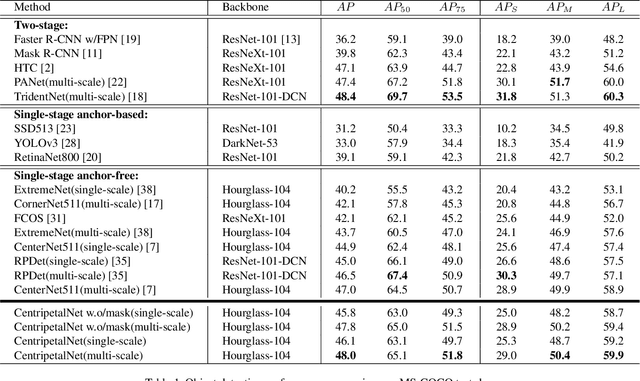
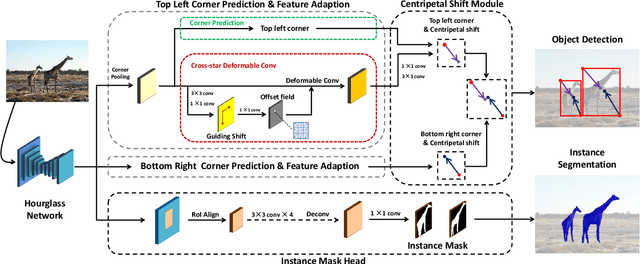
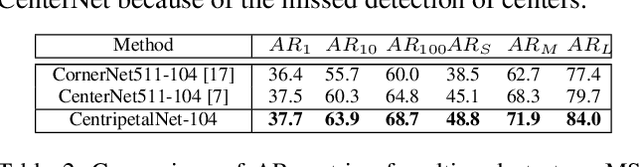
Keypoint-based detectors have achieved pretty-well performance. However, incorrect keypoint matching is still widespread and greatly affects the performance of the detector. In this paper, we propose CentripetalNet which uses centripetal shift to pair corner keypoints from the same instance. CentripetalNet predicts the position and the centripetal shift of the corner points and matches corners whose shifted results are aligned. Combining position information, our approach matches corner points more accurately than the conventional embedding approaches do. Corner pooling extracts information inside the bounding boxes onto the border. To make this information more aware at the corners, we design a cross-star deformable convolution network to conduct feature adaption. Furthermore, we explore instance segmentation on anchor-free detectors by equipping our CentripetalNet with a mask prediction module. On MS-COCO test-dev, our CentripetalNet not only outperforms all existing anchor-free detectors with an AP of 48.0% but also achieves comparable performance to the state-of-the-art instance segmentation approaches with a 40.2% MaskAP. Code will be available at https://github.com/KiveeDong/CentripetalNet.