 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBezierFormer: A Unified Architecture for 2D and 3D Lane Detection
Apr 25, 2024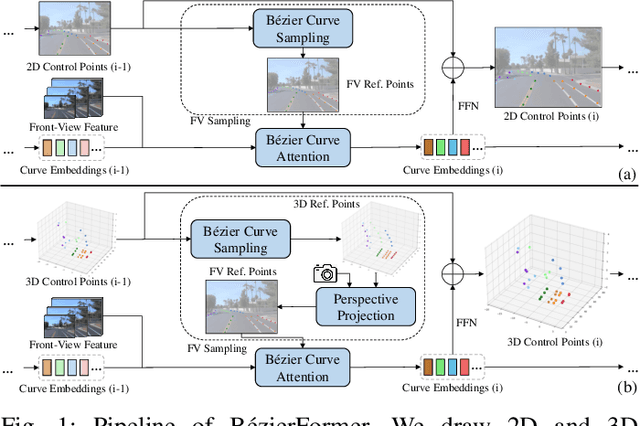
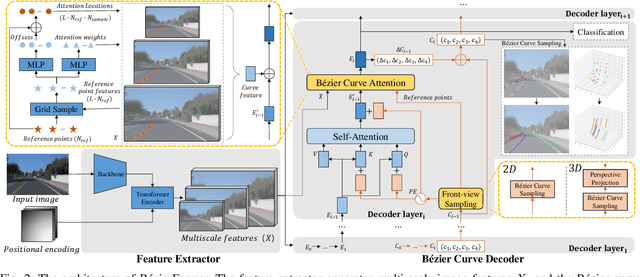
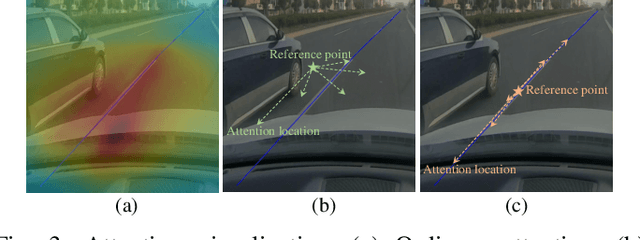

Lane detection has made significant progress in recent years, but there is not a unified architecture for its two sub-tasks: 2D lane detection and 3D lane detection. To fill this gap, we introduce B\'{e}zierFormer, a unified 2D and 3D lane detection architecture based on B\'{e}zier curve lane representation. B\'{e}zierFormer formulate queries as B\'{e}zier control points and incorporate a novel B\'{e}zier curve attention mechanism. This attention mechanism enables comprehensive and accurate feature extraction for slender lane curves via sampling and fusing multiple reference points on each curve. In addition, we propose a novel Chamfer IoU-based loss which is more suitable for the B\'{e}zier control points regression. The state-of-the-art performance of B\'{e}zierFormer on widely-used 2D and 3D lane detection benchmarks verifies its effectiveness and suggests the worthiness of further exploration.
A survey on deep learning approaches for data integration in autonomous driving system
Jun 17, 2023



The perception module of self-driving vehicles relies on a multi-sensor system to understand its environment. Recent advancements in deep learning have led to the rapid development of approaches that integrate multi-sensory measurements to enhance perception capabilities. This paper surveys the latest deep learning integration techniques applied to the perception module in autonomous driving systems, categorizing integration approaches based on "what, how, and when to integrate." A new taxonomy of integration is proposed, based on three dimensions: multi-view, multi-modality, and multi-frame. The integration operations and their pros and cons are summarized, providing new insights into the properties of an "ideal" data integration approach that can alleviate the limitations of existing methods. After reviewing hundreds of relevant papers, this survey concludes with a discussion of the key features of an optimal data integration approach.
NeMO: Neural Map Growing System for Spatiotemporal Fusion in Bird's-Eye-View and BDD-Map Benchmark
Jun 07, 2023

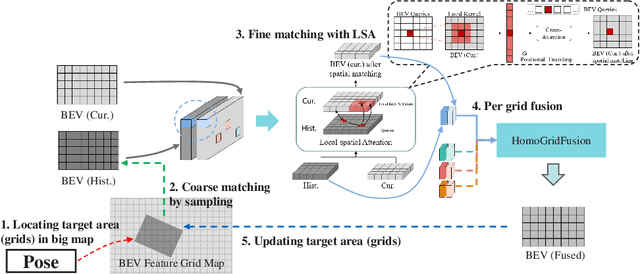

Vision-centric Bird's-Eye View (BEV) representation is essential for autonomous driving systems (ADS). Multi-frame temporal fusion which leverages historical information has been demonstrated to provide more comprehensive perception results. While most research focuses on ego-centric maps of fixed settings, long-range local map generation remains less explored. This work outlines a new paradigm, named NeMO, for generating local maps through the utilization of a readable and writable big map, a learning-based fusion module, and an interaction mechanism between the two. With an assumption that the feature distribution of all BEV grids follows an identical pattern, we adopt a shared-weight neural network for all grids to update the big map. This paradigm supports the fusion of longer time series and the generation of long-range BEV local maps. Furthermore, we release BDD-Map, a BDD100K-based dataset incorporating map element annotations, including lane lines, boundaries, and pedestrian crossing. Experiments on the NuScenes and BDD-Map datasets demonstrate that NeMO outperforms state-of-the-art map segmentation methods. We also provide a new scene-level BEV map evaluation setting along with the corresponding baseline for a more comprehensive comparison.
RIO: Rotation-equivariance supervised learning of robust inertial odometry
Nov 23, 2021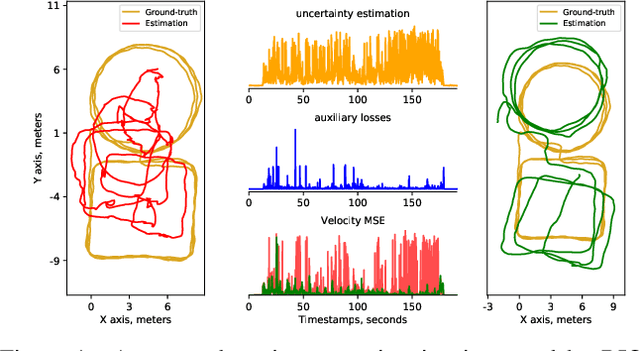
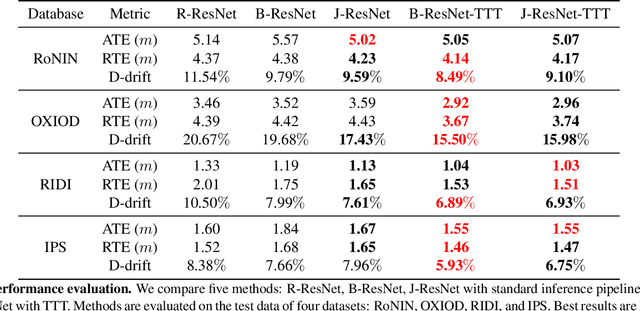
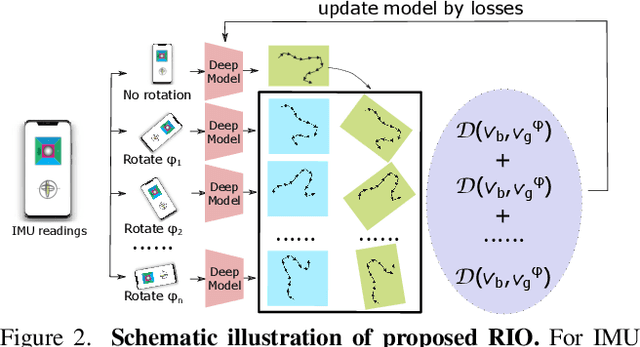
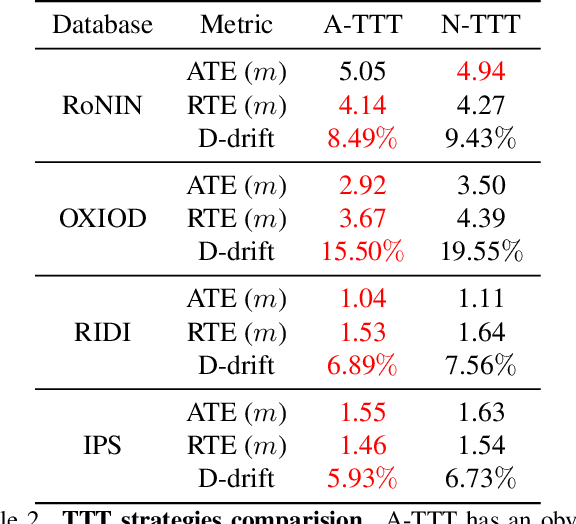
This paper introduces rotation-equivariance as a self-supervisor to train inertial odometry models. We demonstrate that the self-supervised scheme provides a powerful supervisory signal at training phase as well as at inference stage. It reduces the reliance on massive amounts of labeled data for training a robust model and makes it possible to update the model using various unlabeled data. Further, we propose adaptive Test-Time Training (TTT) based on uncertainty estimations in order to enhance the generalizability of the inertial odometry to various unseen data. We show in experiments that the Rotation-equivariance-supervised Inertial Odometry (RIO) trained with 30% data achieves on par performance with a model trained with the whole database. Adaptive TTT improves models performance in all cases and makes more than 25% improvements under several scenarios.
Learning multiview 3D point cloud registration
Jan 15, 2020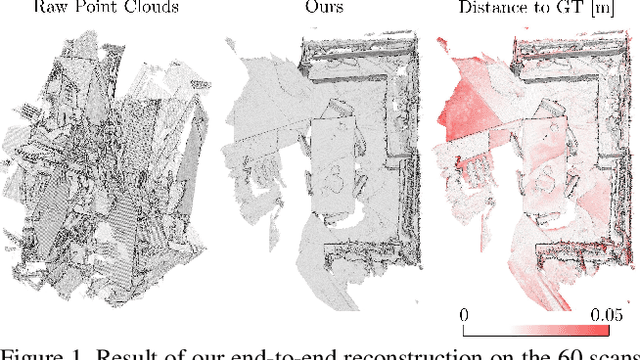

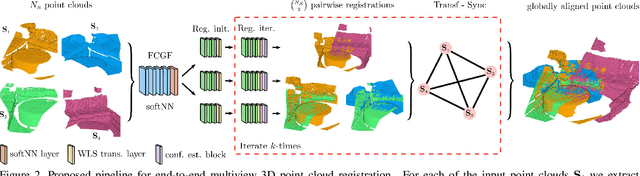

We present a novel, end-to-end learnable, multiview 3D point cloud registration algorithm. Registration of multiple scans typically follows a two-stage pipeline: the initial pairwise alignment and the globally consistent refinement. The former is often ambiguous due to the low overlap of neighboring point clouds, symmetries and repetitive scene parts. Therefore, the latter global refinement aims at establishing the cyclic consistency across multiple scans and helps in resolving the ambiguous cases. In this paper we propose, to the best of our knowledge, the first end-to-end algorithm for joint learning of both parts of this two-stage problem. Experimental evaluation on well accepted benchmark datasets shows that our approach outperforms the state-of-the-art by a significant margin, while being end-to-end trainable and computationally less costly. Moreover, we present detailed analysis and an ablation study that validate the novel components of our approach. The source code and pretrained models will be made publicly available under https: //github.com/zgojcic/3D_multiview_reg.
Feature-wise change detection and robust indoor positioning using RANSAC-like approach
Dec 18, 2019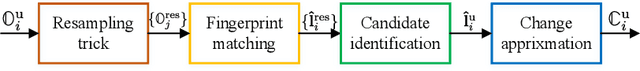
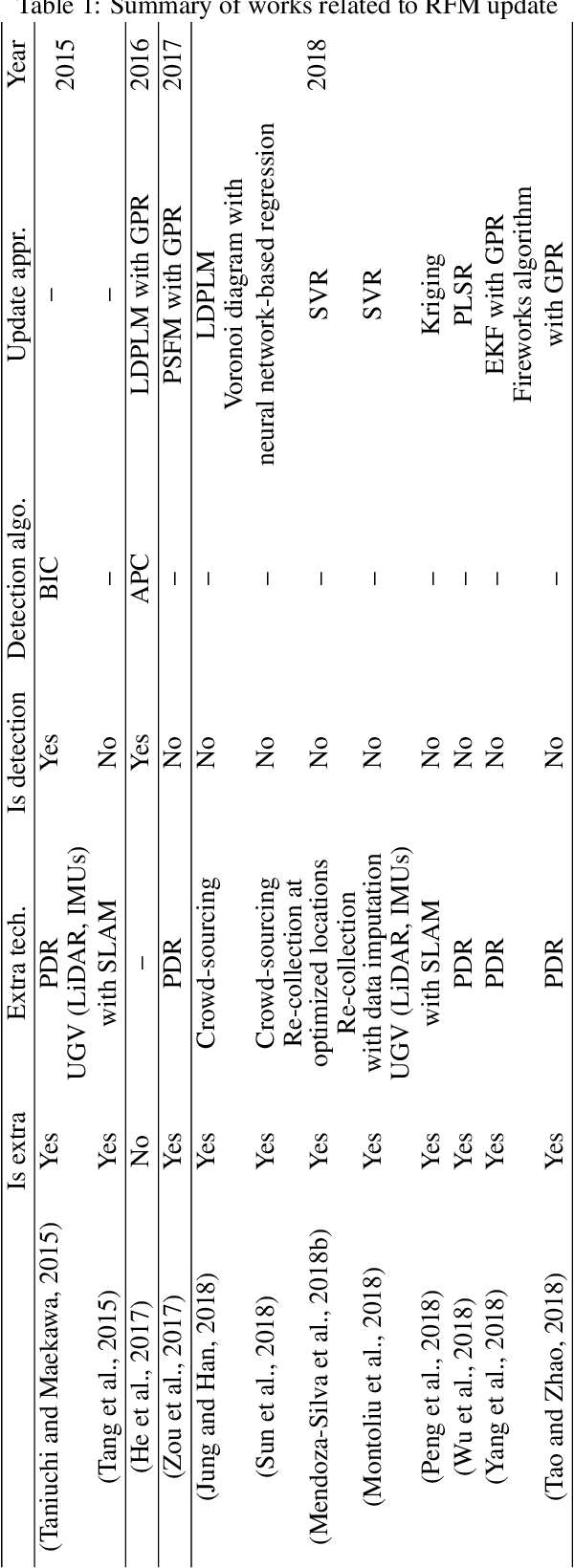

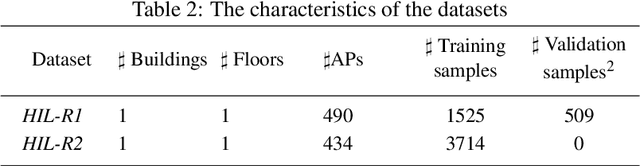
Fingerprinting-based positioning, one of the promising indoor positioning solutions, has been broadly explored owing to the pervasiveness of sensor-rich mobile devices, the prosperity of opportunistically measurable location-relevant signals and the progress of data-driven algorithms. One critical challenge is to controland improve the quality of the reference fingerprint map (RFM), which is built at the offline stage and applied for online positioning. The key concept concerningthe quality control of the RFM is updating the RFM according to the newly measured data. Though varies methods have been proposed for adapting the RFM, they approach the problem by introducing extra-positioning schemes (e.g. PDR orUGV) and directly adjust the RFM without distinguishing whether critical changes have occurred. This paper aims at proposing an extra-positioning-free solution by making full use of the redundancy of measurable features. Loosely inspired by random sampling consensus (RANSAC), arbitrarily sampled subset of features from the online measurement are used for generating multi-resamples, which areused for estimating the intermediate locations. In the way of resampling, it can mitigate the impact of the changed features on positioning and enables to retrieve accurate location estimation. The users location is robustly computed by identifying the candidate locations from these intermediate ones using modified Jaccardindex (MJI) and the feature-wise change belief is calculated according to the world model of the RFM and the estimated variability of features. In order to validate our proposed approach, two levels of experimental analysis have been carried out. On the simulated dataset, the average change detection accuracy is about 90%. Meanwhile, the improvement of positioning accuracy within 2 m is about 20% by dropping out the features that are detected as changed when performing positioning comparing to that of using all measured features for location estimation. On the long-term collected dataset, the average change detection accuracy is about 85%.
An iterative scheme for feature based positioning using a weighted dissimilarity measure
May 30, 2019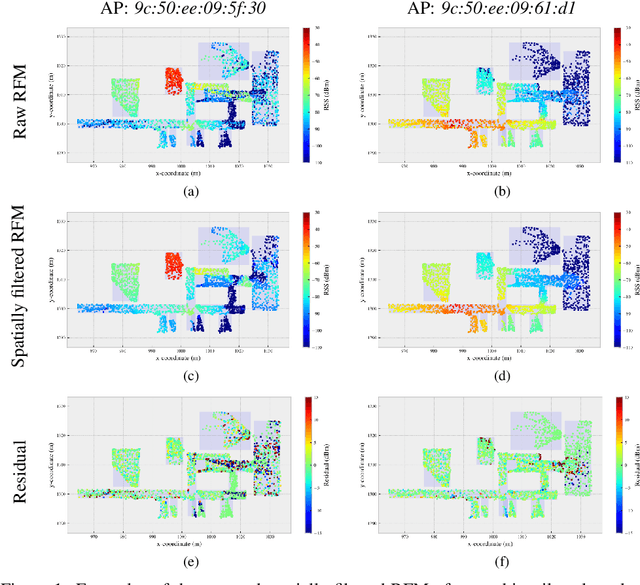

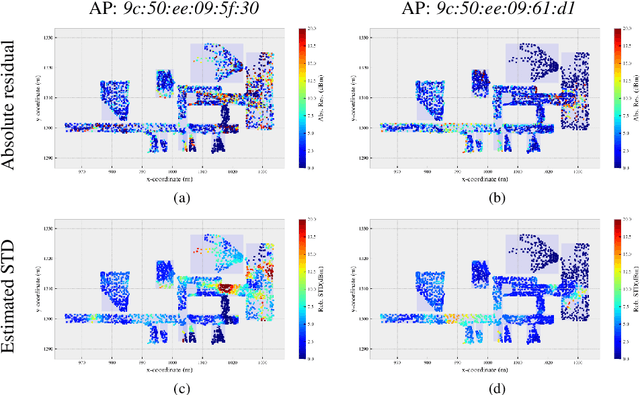
We propose an iterative scheme for feature-based positioning using a new weighted dissimilarity measure with the goal of reducing the impact of large errors among the measured or modeled features. The weights are computed from the location-dependent standard deviations of the features and stored as part of the reference fingerprint map (RFM). Spatial filtering and kernel smoothing of the kinematically collected raw data allow efficiently estimating the standard deviations during RFM generation. In the positioning stage, the weights control the contribution of each feature to the dissimilarity measure, which in turn quantifies the difference between the set of online measured features and the fingerprints stored in the RFM. Features with little variability contribute more to the estimated position than features with high variability. Iterations are necessary because the variability depends on the location, and the location is initially unknown when estimating the position. Using real WiFi signal strength data from extended test measurements with ground truth in an office building, we show that the standard deviations of these features vary considerably within the region of interest and are neither simple functions of the signal strength nor of the distances from the corresponding access points. This is the motivation to include the empirical standard deviations in the RFM. We then analyze the deviations of the estimated positions with and without the location-dependent weighting. In the present example the maximum radial positioning error from ground truth are reduced by 40% comparing to kNN without the weighted dissimilarity measure.
The Perfect Match: 3D Point Cloud Matching with Smoothed Densities
Nov 16, 2018

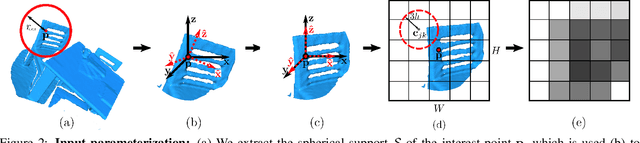

We propose 3DSmoothNet, a full workflow to match 3D point clouds with a siamese deep learning architecture and fully convolutional layers using a voxelized smoothed density value (SDV) representation. The latter is computed per interest point and aligned to the local reference frame (LRF) to achieve rotation invariance. Our compact, learned, rotation invariant 3D point cloud descriptor achieves 94.9% average recall on the 3DMatch benchmark data set, outperforming the state-of-the-art by more than 20 percent points with only 32 output dimensions. This very low output dimension allows for near real-time correspondence search with 0.1 ms per feature point on a standard PC. Our approach is sensor- and scene-agnostic because of SDV, LRF and learning highly descriptive features with fully convolutional layers. We show that 3DSmoothNet trained only on RGB-D indoor scenes of buildings achieves 79.0% average recall on laser scans of outdoor vegetation, more than double the performance of our closest, learningbased competitors.
CDM: Compound dissimilarity measure and an application to fingerprinting-based positioning
Jun 26, 2018

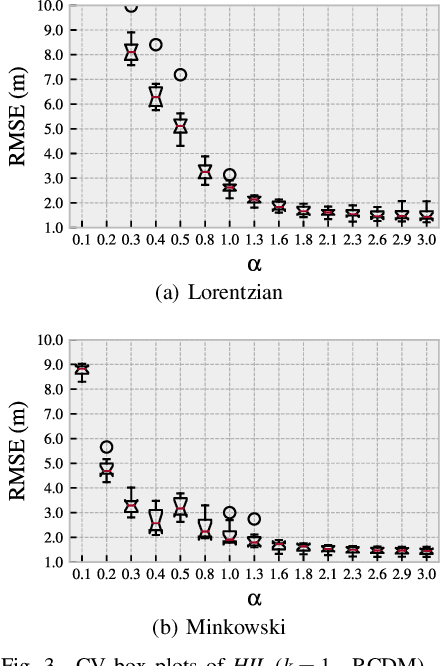
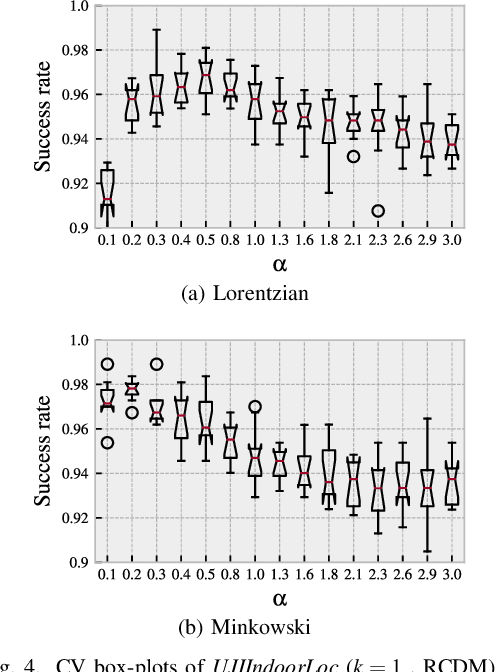
A non-vector-based dissimilarity measure is proposed by combining vector-based distance metrics and set operations. This proposed compound dissimilarity measure (CDM) is applicable to quantify similarity of collections of attribute/feature pairs where not all attributes are present in all collections. This is a typical challenge in the context of e.g., fingerprinting-based positioning (FbP). Compared to vector-based distance metrics (e.g., Minkowski), the merits of the proposed CDM are i) the data do not need to be converted to vectors of equal dimension, ii) shared and unshared attributes can be weighted differently within the assessment, and iii) additional degrees of freedom within the measure allow to adapt its properties to application needs in a data-driven way. We indicate the validity of the proposed CDM by demonstrating the improvements of the positioning performance of fingerprinting-based WLAN indoor positioning using four different datasets, three of them publicly available. When processing these datasets using CDM instead of conventional distance metrics the accuracy of identifying buildings and floors improves by about 5% on average. The 2d positioning errors in terms of root mean squared error (RMSE) are reduced by a factor of two, and the percentage of position solutions with less than 2m error improves by over 10%.
Jaccard analysis and LASSO-based feature selection for location fingerprinting with limited computational complexity
Nov 21, 2017

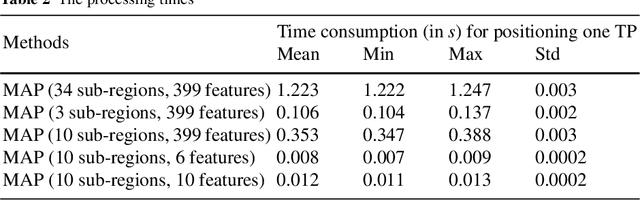
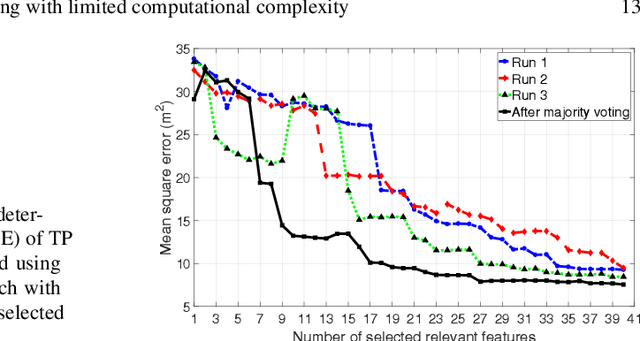
We propose an approach to reduce both computational complexity and data storage requirements for the online positioning stage of a fingerprinting-based indoor positioning system (FIPS) by introducing segmentation of the region of interest (RoI) into sub-regions, sub-region selection using a modified Jaccard index, and feature selection based on randomized least absolute shrinkage and selection operator (LASSO). We implement these steps into a Bayesian framework of position estimation using the maximum a posteriori (MAP) principle. An additional benefit of these steps is that the time for estimating the position, and the required data storage are virtually independent of the size of the RoI and of the total number of available features within the RoI. Thus the proposed steps facilitate application of FIPS to large areas. Results of an experimental analysis using real data collected in an office building using a Nexus 6P smart phone as user device and a total station for providing position ground truth corroborate the expected performance of the proposed approach. The positioning accuracy obtained by only processing 10 automatically identified features instead of all available ones and limiting position estimation to 10 automatically identified sub-regions instead of the entire RoI is equivalent to processing all available data. In the chosen example, 50% of the errors are less than 1.8 m and 90% are less than 5 m. However, the computation time using the automatically identified subset of data is only about 1% of that required for processing the entire data set.