 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Perfect Match: 3D Point Cloud Matching with Smoothed Densities
Paper and Code


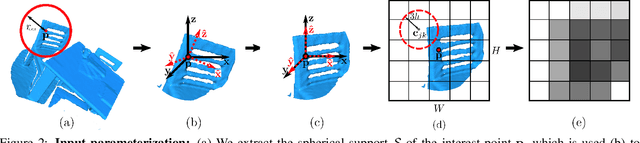

We propose 3DSmoothNet, a full workflow to match 3D point clouds with a siamese deep learning architecture and fully convolutional layers using a voxelized smoothed density value (SDV) representation. The latter is computed per interest point and aligned to the local reference frame (LRF) to achieve rotation invariance. Our compact, learned, rotation invariant 3D point cloud descriptor achieves 94.9% average recall on the 3DMatch benchmark data set, outperforming the state-of-the-art by more than 20 percent points with only 32 output dimensions. This very low output dimension allows for near real-time correspondence search with 0.1 ms per feature point on a standard PC. Our approach is sensor- and scene-agnostic because of SDV, LRF and learning highly descriptive features with fully convolutional layers. We show that 3DSmoothNet trained only on RGB-D indoor scenes of buildings achieves 79.0% average recall on laser scans of outdoor vegetation, more than double the performance of our closest, learningbased competitors.