 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe unrealized potential of agroforestry for an emissions-intensive agricultural commodity
Oct 28, 2024


Reconciling agricultural production with climate-change mitigation and adaptation is one of the most formidable problems in sustainability. One proposed strategy for addressing this problem is the judicious retention of trees in agricultural systems. However, the magnitude of the current and future-potential benefit that trees contribute remains uncertain, particularly in the agricultural sector where trees can also limit production. Here we help to resolve these issues across a West African region responsible for producing $\approx$60% of the world's cocoa, a crop that contributes one of the highest per unit carbon footprints of all foods. We use machine learning to generate spatially-explicit estimates of shade-tree cover and carbon stocks across the region. We find that existing shade-tree cover is low, and not spatially aligned with climate threat. But we also find enormous unrealized potential for the sector to counterbalance a large proportion of their high carbon footprint annually, without threatening production. Our methods can be applied to other globally significant commodities that can be grown in agroforests, and align with accounting requirements of carbon markets, and emerging legislative requirements for sustainability reporting.
AGBD: A Global-scale Biomass Dataset
Jun 07, 2024



Accurate estimates of Above Ground Biomass (AGB) are essential in addressing two of humanity's biggest challenges, climate change and biodiversity loss. Existing datasets for AGB estimation from satellite imagery are limited. Either they focus on specific, local regions at high resolution, or they offer global coverage at low resolution. There is a need for a machine learning-ready, globally representative, high-resolution benchmark. Our findings indicate significant variability in biomass estimates across different vegetation types, emphasizing the necessity for a dataset that accurately captures global diversity. To address these gaps, we introduce a comprehensive new dataset that is globally distributed, covers a range of vegetation types, and spans several years. This dataset combines AGB reference data from the GEDI mission with data from Sentinel-2 and PALSAR-2 imagery. Additionally, it includes pre-processed high-level features such as a dense canopy height map, an elevation map, and a land-cover classification map. We also produce a dense, high-resolution (10m) map of AGB predictions for the entire area covered by the dataset. Rigorously tested, our dataset is accompanied by several benchmark models and is publicly available. It can be easily accessed using a single line of code, offering a solid basis for efforts towards global AGB estimation. The GitHub repository github.com/ghjuliasialelli/AGBD serves as a one-stop shop for all code and data.
Accuracy and Consistency of Space-based Vegetation Height Maps for Forest Dynamics in Alpine Terrain
Sep 04, 2023



Monitoring and understanding forest dynamics is essential for environmental conservation and management. This is why the Swiss National Forest Inventory (NFI) provides countrywide vegetation height maps at a spatial resolution of 0.5 m. Its long update time of 6 years, however, limits the temporal analysis of forest dynamics. This can be improved by using spaceborne remote sensing and deep learning to generate large-scale vegetation height maps in a cost-effective way. In this paper, we present an in-depth analysis of these methods for operational application in Switzerland. We generate annual, countrywide vegetation height maps at a 10-meter ground sampling distance for the years 2017 to 2020 based on Sentinel-2 satellite imagery. In comparison to previous works, we conduct a large-scale and detailed stratified analysis against a precise Airborne Laser Scanning reference dataset. This stratified analysis reveals a close relationship between the model accuracy and the topology, especially slope and aspect. We assess the potential of deep learning-derived height maps for change detection and find that these maps can indicate changes as small as 250 $m^2$. Larger-scale changes caused by a winter storm are detected with an F1-score of 0.77. Our results demonstrate that vegetation height maps computed from satellite imagery with deep learning are a valuable, complementary, cost-effective source of evidence to increase the temporal resolution for national forest assessments.
BiasBed -- Rigorous Texture Bias Evaluation
Dec 01, 2022



The well-documented presence of texture bias in modern convolutional neural networks has led to a plethora of algorithms that promote an emphasis on shape cues, often to support generalization to new domains. Yet, common datasets, benchmarks and general model selection strategies are missing, and there is no agreed, rigorous evaluation protocol. In this paper, we investigate difficulties and limitations when training networks with reduced texture bias. In particular, we also show that proper evaluation and meaningful comparisons between methods are not trivial. We introduce BiasBed, a testbed for texture- and style-biased training, including multiple datasets and a range of existing algorithms. It comes with an extensive evaluation protocol that includes rigorous hypothesis testing to gauge the significance of the results, despite the considerable training instability of some style bias methods. Our extensive experiments, shed new light on the need for careful, statistically founded evaluation protocols for style bias (and beyond). E.g., we find that some algorithms proposed in the literature do not significantly mitigate the impact of style bias at all. With the release of BiasBed, we hope to foster a common understanding of consistent and meaningful comparisons, and consequently faster progress towards learning methods free of texture bias. Code is available at https://github.com/D1noFuzi/BiasBed
Tetrahedral Diffusion Models for 3D Shape Generation
Nov 23, 2022



Recently, probabilistic denoising diffusion models (DDMs) have greatly advanced the generative power of neural networks. DDMs, inspired by non-equilibrium thermodynamics, have not only been used for 2D image generation, but can also readily be applied to 3D point clouds. However, representing 3D shapes as point clouds has a number of drawbacks, most obvious perhaps that they have no notion of topology or connectivity. Here, we explore an alternative route and introduce tetrahedral diffusion models, an extension of DDMs to tetrahedral partitions of 3D space. The much more structured 3D representation with space-filling tetrahedra makes it possible to guide and regularize the diffusion process and to apply it to colorized assets. To manipulate the proposed representation, we develop tetrahedral convolutions, down- and up-sampling kernels. With those operators, 3D shape generation amounts to learning displacement vectors and signed distance values on the tetrahedral grid. Our experiments confirm that Tetrahedral Diffusion yields plausible, visually pleasing and diverse 3D shapes, is able to handle surface attributes like color, and can be guided at test time to manipulate the resulting shapes.
Satellite-based high-resolution maps of cocoa planted area for Côte d'Ivoire and Ghana
Jun 13, 2022
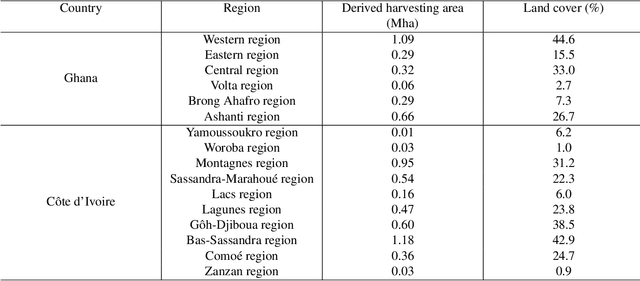
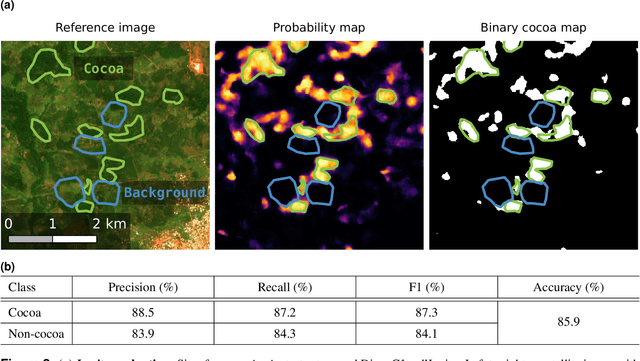
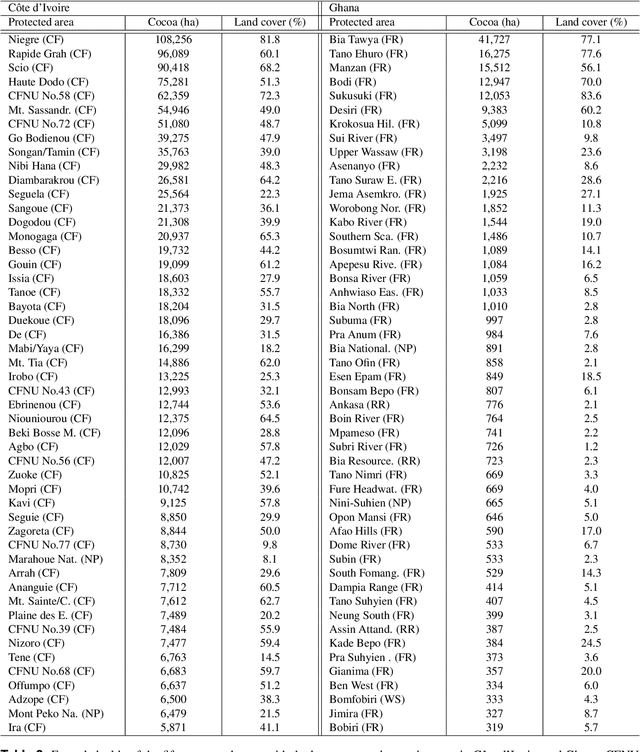
C\^ote d'Ivoire and Ghana, the world's largest producers of cocoa, account for two thirds of the global cocoa production. In both countries, cocoa is the primary perennial crop, providing income to almost two million farmers. Yet precise maps of cocoa planted area are missing, hindering accurate quantification of expansion in protected areas, production and yields, and limiting information available for improved sustainability governance. Here, we combine cocoa plantation data with publicly available satellite imagery in a deep learning framework and create high-resolution maps of cocoa plantations for both countries, validated in situ. Our results suggest that cocoa cultivation is an underlying driver of over 37% and 13% of forest loss in protected areas in C\^ote d'Ivoire and Ghana, respectively, and that official reports substantially underestimate the planted area, up to 40% in Ghana. These maps serve as a crucial building block to advance understanding of conservation and economic development in cocoa producing regions.
Zero-Shot Bird Species Recognition by Learning from Field Guides
Jun 03, 2022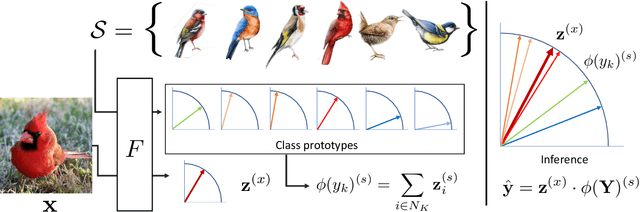
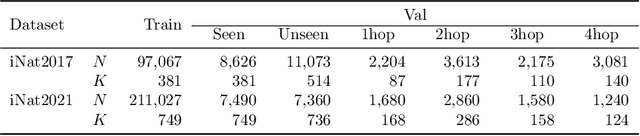
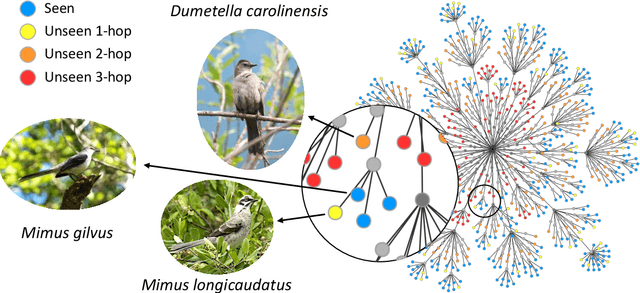

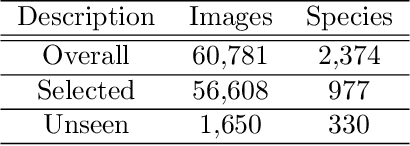
We exploit field guides to learn bird species recognition, in particular zero-shot recognition of unseen species. The illustrations contained in field guides deliberately focus on discriminative properties of a species, and can serve as side information to transfer knowledge from seen to unseen classes. We study two approaches: (1) a contrastive encoding of illustrations that can be fed into zero-shot learning schemes; and (2) a novel method that leverages the fact that illustrations are also images and as such structurally more similar to photographs than other kinds of side information. Our results show that illustrations from field guides, which are readily available for a wide range of species, are indeed a competitive source of side information. On the iNaturalist2021 subset, we obtain a harmonic mean from 749 seen and 739 unseen classes greater than $45\%$ (@top-10) and $15\%$ (@top-1). Which shows that field guides are a valuable option for challenging real-world scenarios with many species.
Learning Graph Regularisation for Guided Super-Resolution
Mar 27, 2022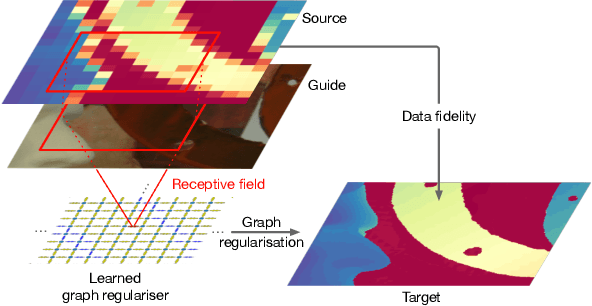

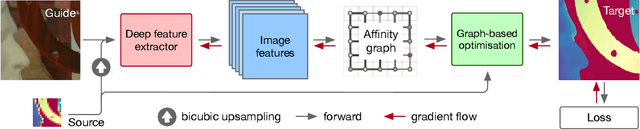

We introduce a novel formulation for guided super-resolution. Its core is a differentiable optimisation layer that operates on a learned affinity graph. The learned graph potentials make it possible to leverage rich contextual information from the guide image, while the explicit graph optimisation within the architecture guarantees rigorous fidelity of the high-resolution target to the low-resolution source. With the decision to employ the source as a constraint rather than only as an input to the prediction, our method differs from state-of-the-art deep architectures for guided super-resolution, which produce targets that, when downsampled, will only approximately reproduce the source. This is not only theoretically appealing, but also produces crisper, more natural-looking images. A key property of our method is that, although the graph connectivity is restricted to the pixel lattice, the associated edge potentials are learned with a deep feature extractor and can encode rich context information over large receptive fields. By taking advantage of the sparse graph connectivity, it becomes possible to propagate gradients through the optimisation layer and learn the edge potentials from data. We extensively evaluate our method on several datasets, and consistently outperform recent baselines in terms of quantitative reconstruction errors, while also delivering visually sharper outputs. Moreover, we demonstrate that our method generalises particularly well to new datasets not seen during training.
Digital Taxonomist: Identifying Plant Species in Citizen Scientists' Photographs
Jun 07, 2021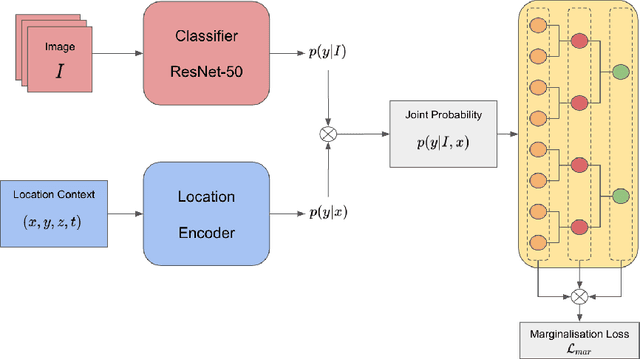


Automatic identification of plant specimens from amateur photographs could improve species range maps, thus supporting ecosystems research as well as conservation efforts. However, classifying plant specimens based on image data alone is challenging: some species exhibit large variations in visual appearance, while at the same time different species are often visually similar; additionally, species observations follow a highly imbalanced, long-tailed distribution due to differences in abundance as well as observer biases. On the other hand, most species observations are accompanied by side information about the spatial, temporal and ecological context. Moreover, biological species are not an unordered list of classes but embedded in a hierarchical taxonomic structure. We propose a machine learning model that takes into account these additional cues in a unified framework. Our Digital Taxonomist is able to identify plant species in photographs more correctly.
Mapping oil palm density at country scale: An active learning approach
May 24, 2021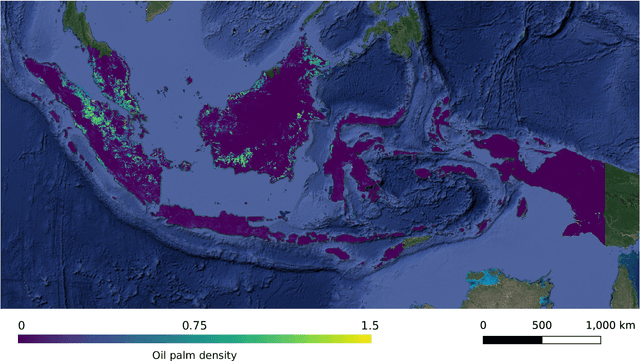

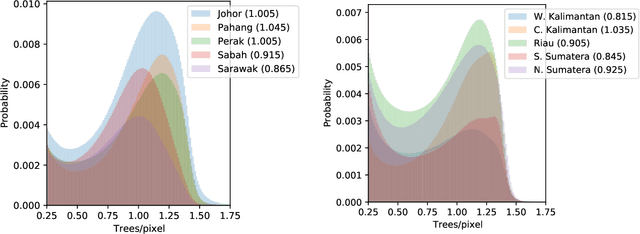
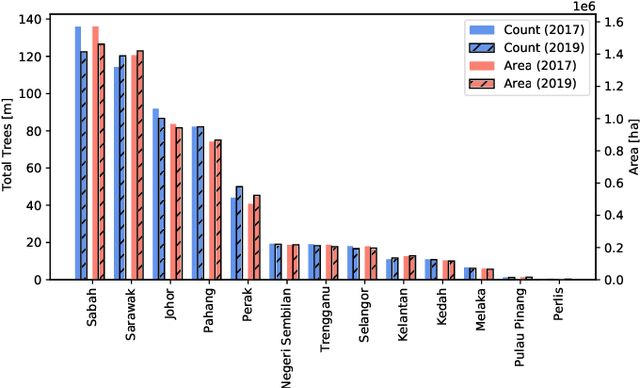
Accurate mapping of oil palm is important for understanding its past and future impact on the environment. We propose to map and count oil palms by estimating tree densities per pixel for large-scale analysis. This allows for fine-grained analysis, for example regarding different planting patterns. To that end, we propose a new, active deep learning method to estimate oil palm density at large scale from Sentinel-2 satellite images, and apply it to generate complete maps for Malaysia and Indonesia. What makes the regression of oil palm density challenging is the need for representative reference data that covers all relevant geographical conditions across a large territory. Specifically for density estimation, generating reference data involves counting individual trees. To keep the associated labelling effort low we propose an active learning (AL) approach that automatically chooses the most relevant samples to be labelled. Our method relies on estimates of the epistemic model uncertainty and of the diversity among samples, making it possible to retrieve an entire batch of relevant samples in a single iteration. Moreover, our algorithm has linear computational complexity and is easily parallelisable to cover large areas. We use our method to compute the first oil palm density map with $10\,$m Ground Sampling Distance (GSD) , for all of Indonesia and Malaysia and for two different years, 2017 and 2019. The maps have a mean absolute error of $\pm$7.3 trees/$ha$, estimated from an independent validation set. We also analyse density variations between different states within a country and compare them to official estimates. According to our estimates there are, in total, $>1.2$ billion oil palms in Indonesia covering $>$15 million $ha$, and $>0.5$ billion oil palms in Malaysia covering $>6$ million $ha$.