 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiasBed -- Rigorous Texture Bias Evaluation
Dec 01, 2022



The well-documented presence of texture bias in modern convolutional neural networks has led to a plethora of algorithms that promote an emphasis on shape cues, often to support generalization to new domains. Yet, common datasets, benchmarks and general model selection strategies are missing, and there is no agreed, rigorous evaluation protocol. In this paper, we investigate difficulties and limitations when training networks with reduced texture bias. In particular, we also show that proper evaluation and meaningful comparisons between methods are not trivial. We introduce BiasBed, a testbed for texture- and style-biased training, including multiple datasets and a range of existing algorithms. It comes with an extensive evaluation protocol that includes rigorous hypothesis testing to gauge the significance of the results, despite the considerable training instability of some style bias methods. Our extensive experiments, shed new light on the need for careful, statistically founded evaluation protocols for style bias (and beyond). E.g., we find that some algorithms proposed in the literature do not significantly mitigate the impact of style bias at all. With the release of BiasBed, we hope to foster a common understanding of consistent and meaningful comparisons, and consequently faster progress towards learning methods free of texture bias. Code is available at https://github.com/D1noFuzi/BiasBed
Fine-grained Population Mapping from Coarse Census Counts and Open Geodata
Nov 08, 2022Fine-grained population maps are needed in several domains, like urban planning, environmental monitoring, public health, and humanitarian operations. Unfortunately, in many countries only aggregate census counts over large spatial units are collected, moreover, these are not always up-to-date. We present POMELO, a deep learning model that employs coarse census counts and open geodata to estimate fine-grained population maps with 100m ground sampling distance. Moreover, the model can also estimate population numbers when no census counts at all are available, by generalizing across countries. In a series of experiments for several countries in sub-Saharan Africa, the maps produced with POMELOare in good agreement with the most detailed available reference counts: disaggregation of coarse census counts reaches R2 values of 85-89%; unconstrained prediction in the absence of any counts reaches 48-69%.
Mapping Vulnerable Populations with AI
Jul 29, 2021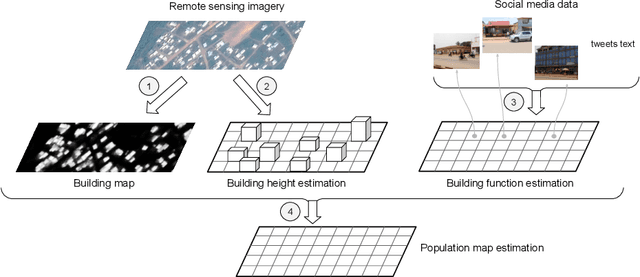


Humanitarian actions require accurate information to efficiently delegate support operations. Such information can be maps of building footprints, building functions, and population densities. While the access to this information is comparably easy in industrialized countries thanks to reliable census data and national geo-data infrastructures, this is not the case for developing countries, where that data is often incomplete or outdated. Building maps derived from remote sensing images may partially remedy this challenge in such countries, but are not always accurate due to different landscape configurations and lack of validation data. Even when they exist, building footprint layers usually do not reveal more fine-grained building properties, such as the number of stories or the building's function (e.g., office, residential, school, etc.). In this project we aim to automate building footprint and function mapping using heterogeneous data sources. In a first step, we intend to delineate buildings from satellite data, using deep learning models for semantic image segmentation. Building functions shall be retrieved by parsing social media data like for instance tweets, as well as ground-based imagery, to automatically identify different buildings functions and retrieve further information such as the number of building stories. Building maps augmented with those additional attributes make it possible to derive more accurate population density maps, needed to support the targeted provision of humanitarian aid.