 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Population Mapping from Coarse Census Counts and Open Geodata
Nov 08, 2022Fine-grained population maps are needed in several domains, like urban planning, environmental monitoring, public health, and humanitarian operations. Unfortunately, in many countries only aggregate census counts over large spatial units are collected, moreover, these are not always up-to-date. We present POMELO, a deep learning model that employs coarse census counts and open geodata to estimate fine-grained population maps with 100m ground sampling distance. Moreover, the model can also estimate population numbers when no census counts at all are available, by generalizing across countries. In a series of experiments for several countries in sub-Saharan Africa, the maps produced with POMELOare in good agreement with the most detailed available reference counts: disaggregation of coarse census counts reaches R2 values of 85-89%; unconstrained prediction in the absence of any counts reaches 48-69%.
Mapping Vulnerable Populations with AI
Jul 29, 2021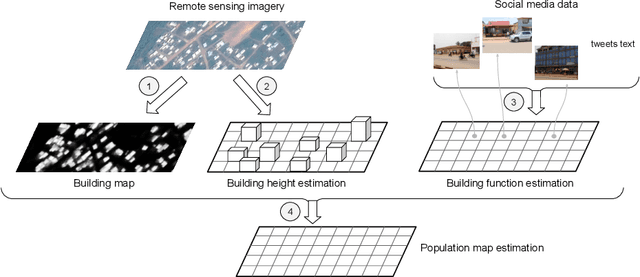


Humanitarian actions require accurate information to efficiently delegate support operations. Such information can be maps of building footprints, building functions, and population densities. While the access to this information is comparably easy in industrialized countries thanks to reliable census data and national geo-data infrastructures, this is not the case for developing countries, where that data is often incomplete or outdated. Building maps derived from remote sensing images may partially remedy this challenge in such countries, but are not always accurate due to different landscape configurations and lack of validation data. Even when they exist, building footprint layers usually do not reveal more fine-grained building properties, such as the number of stories or the building's function (e.g., office, residential, school, etc.). In this project we aim to automate building footprint and function mapping using heterogeneous data sources. In a first step, we intend to delineate buildings from satellite data, using deep learning models for semantic image segmentation. Building functions shall be retrieved by parsing social media data like for instance tweets, as well as ground-based imagery, to automatically identify different buildings functions and retrieve further information such as the number of building stories. Building maps augmented with those additional attributes make it possible to derive more accurate population density maps, needed to support the targeted provision of humanitarian aid.
Deploying machine learning to assist digital humanitarians: making image annotation in OpenStreetMap more efficient
Sep 17, 2020

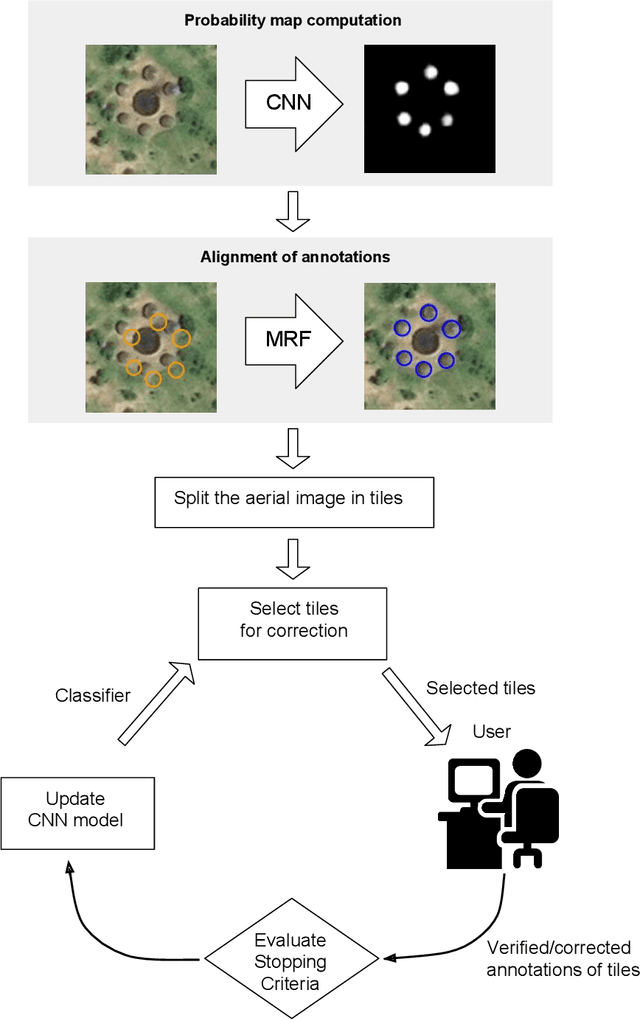
Locating populations in rural areas of developing countries has attracted the attention of humanitarian mapping projects since it is important to plan actions that affect vulnerable areas. Recent efforts have tackled this problem as the detection of buildings in aerial images. However, the quality and the amount of rural building annotated data in open mapping services like OpenStreetMap (OSM) is not sufficient for training accurate models for such detection. Although these methods have the potential of aiding in the update of rural building information, they are not accurate enough to automatically update the rural building maps. In this paper, we explore a human-computer interaction approach and propose an interactive method to support and optimize the work of volunteers in OSM. The user is asked to verify/correct the annotation of selected tiles during several iterations and therefore improving the model with the new annotated data. The experimental results, with simulated and real user annotation corrections, show that the proposed method greatly reduces the amount of data that the volunteers of OSM need to verify/correct. The proposed methodology could benefit humanitarian mapping projects, not only by making more efficient the process of annotation but also by improving the engagement of volunteers.
Understanding urban landuse from the above and ground perspectives: a deep learning, multimodal solution
May 05, 2019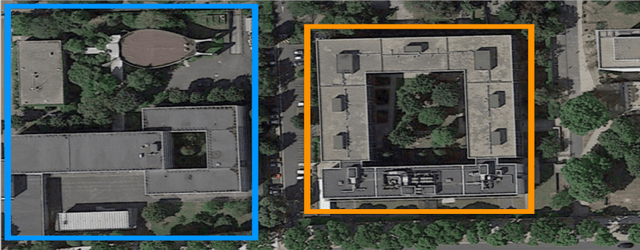
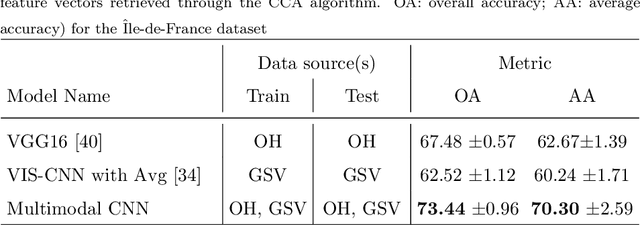
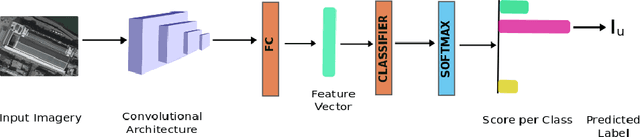
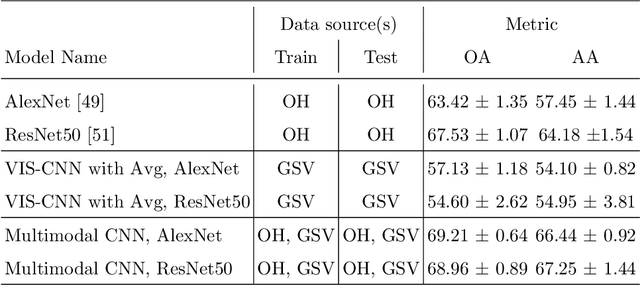
Landuse characterization is important for urban planning. It is traditionally performed with field surveys or manual photo interpretation, two practices that are time-consuming and labor-intensive. Therefore, we aim to automate landuse mapping at the urban-object level with a deep learning approach based on data from multiple sources (or modalities). We consider two image modalities: overhead imagery from Google Maps and ensembles of ground-based pictures (side-views) per urban-object from Google Street View (GSV). These modalities bring complementary visual information pertaining to the urban-objects. We propose an end-to-end trainable model, which uses OpenStreetMap annotations as labels. The model can accommodate a variable number of GSV pictures for the ground-based branch and can also function in the absence of ground pictures at prediction time. We test the effectiveness of our model over the area of \^Ile-de-France, France, and test its generalization abilities on a set of urban-objects from the city of Nantes, France. Our proposed multimodal Convolutional Neural Network achieves considerably higher accuracies than methods that use a single image modality, making it suitable for automatic landuse map updates. Additionally, our approach could be easily scaled to multiple cities, because it is based on data sources available for many cities worldwide.
Correcting rural building annotations in OpenStreetMap using convolutional neural networks
Jan 24, 2019



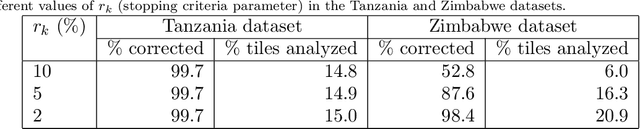
Rural building mapping is paramount to support demographic studies and plan actions in response to crisis that affect those areas. Rural building annotations exist in OpenStreetMap (OSM), but their quality and quantity are not sufficient for training models that can create accurate rural building maps. The problems with these annotations essentially fall into three categories: (i) most commonly, many annotations are geometrically misaligned with the updated imagery; (ii) some annotations do not correspond to buildings in the images (they are misannotations or the buildings have been destroyed); and (iii) some annotations are missing for buildings in the images (the buildings were never annotated or were built between subsequent image acquisitions). First, we propose a method based on Markov Random Field (MRF) to align the buildings with their annotations. The method maximizes the correlation between annotations and a building probability map while enforcing that nearby buildings have similar alignment vectors. Second, the annotations with no evidence in the building probability map are removed. Third, we present a method to detect non-annotated buildings with predefined shapes and add their annotation. The proposed methodology shows considerable improvement in accuracy of the OSM annotations for two regions of Tanzania and Zimbabwe, being more accurate than state-of-the-art baselines.
An Iterative Spanning Forest Framework for Superpixel Segmentation
Jan 30, 2018
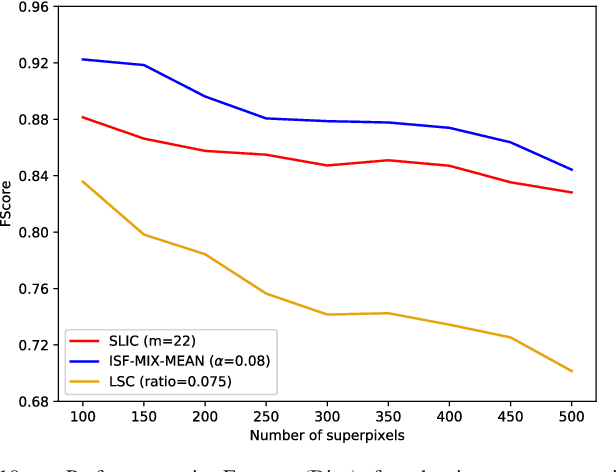
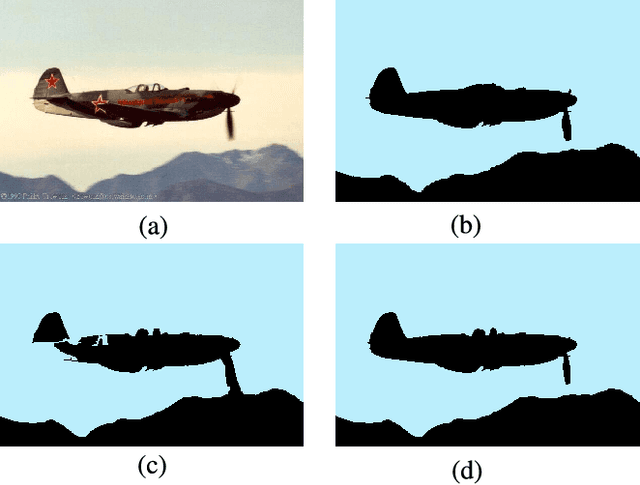

Superpixel segmentation has become an important research problem in image processing. In this paper, we propose an Iterative Spanning Forest (ISF) framework, based on sequences of Image Foresting Transforms, where one can choose i) a seed sampling strategy, ii) a connectivity function, iii) an adjacency relation, and iv) a seed pixel recomputation procedure to generate improved sets of connected superpixels (supervoxels in 3D) per iteration. The superpixels in ISF structurally correspond to spanning trees rooted at those seeds. We present five ISF methods to illustrate different choices of its components. These methods are compared with approaches from the state-of-the-art in effectiveness and efficiency. The experiments involve 2D and 3D datasets with distinct characteristics, and a high level application, named sky image segmentation. The theoretical properties of ISF are demonstrated in the supplementary material and the results show that some of its methods are competitive with or superior to the best baselines in effectiveness and efficiency.