 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisasterVQA: A Visual Question Answering Benchmark Dataset for Disaster Scenes
Jan 20, 2026Social media imagery provides a low-latency source of situational information during natural and human-induced disasters, enabling rapid damage assessment and response. While Visual Question Answering (VQA) has shown strong performance in general-purpose domains, its suitability for the complex and safety-critical reasoning required in disaster response remains unclear. We introduce DisasterVQA, a benchmark dataset designed for perception and reasoning in crisis contexts. DisasterVQA consists of 1,395 real-world images and 4,405 expert-curated question-answer pairs spanning diverse events such as floods, wildfires, and earthquakes. Grounded in humanitarian frameworks including FEMA ESF and OCHA MIRA, the dataset includes binary, multiple-choice, and open-ended questions covering situational awareness and operational decision-making tasks. We benchmark seven state-of-the-art vision-language models and find performance variability across question types, disaster categories, regions, and humanitarian tasks. Although models achieve high accuracy on binary questions, they struggle with fine-grained quantitative reasoning, object counting, and context-sensitive interpretation, particularly for underrepresented disaster scenarios. DisasterVQA provides a challenging and practical benchmark to guide the development of more robust and operationally meaningful vision-language models for disaster response. The dataset is publicly available at https://zenodo.org/records/18267770.
VME: A Satellite Imagery Dataset and Benchmark for Detecting Vehicles in the Middle East and Beyond
May 28, 2025Detecting vehicles in satellite images is crucial for traffic management, urban planning, and disaster response. However, current models struggle with real-world diversity, particularly across different regions. This challenge is amplified by geographic bias in existing datasets, which often focus on specific areas and overlook regions like the Middle East. To address this gap, we present the Vehicles in the Middle East (VME) dataset, designed explicitly for vehicle detection in high-resolution satellite images from Middle Eastern countries. Sourced from Maxar, the VME dataset spans 54 cities across 12 countries, comprising over 4,000 image tiles and more than 100,000 vehicles, annotated using both manual and semi-automated methods. Additionally, we introduce the largest benchmark dataset for Car Detection in Satellite Imagery (CDSI), combining images from multiple sources to enhance global car detection. Our experiments demonstrate that models trained on existing datasets perform poorly on Middle Eastern images, while the VME dataset significantly improves detection accuracy in this region. Moreover, state-of-the-art models trained on CDSI achieve substantial improvements in global car detection.
Detecting Actionable Requests and Offers on Social Media During Crises Using LLMs
Apr 22, 2025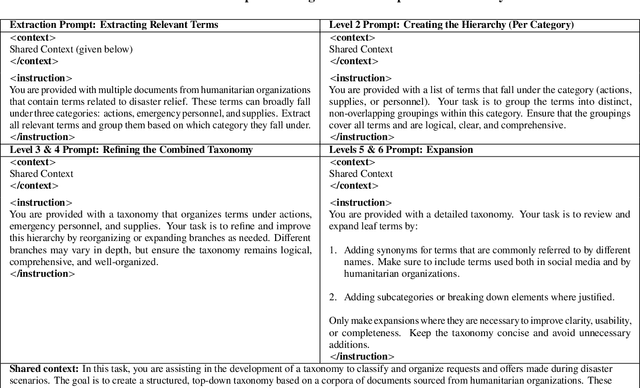
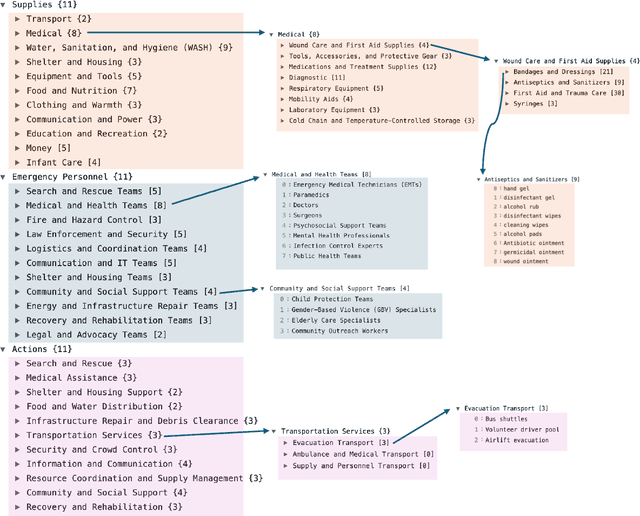

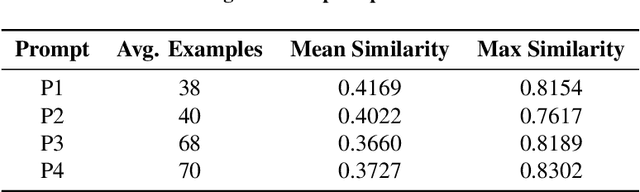
Natural disasters often result in a surge of social media activity, including requests for assistance, offers of help, sentiments, and general updates. To enable humanitarian organizations to respond more efficiently, we propose a fine-grained hierarchical taxonomy to systematically organize crisis-related information about requests and offers into three critical dimensions: supplies, emergency personnel, and actions. Leveraging the capabilities of Large Language Models (LLMs), we introduce Query-Specific Few-shot Learning (QSF Learning) that retrieves class-specific labeled examples from an embedding database to enhance the model's performance in detecting and classifying posts. Beyond classification, we assess the actionability of messages to prioritize posts requiring immediate attention. Extensive experiments demonstrate that our approach outperforms baseline prompting strategies, effectively identifying and prioritizing actionable requests and offers.
Benchmarking Object Detectors under Real-World Distribution Shifts in Satellite Imagery
Mar 24, 2025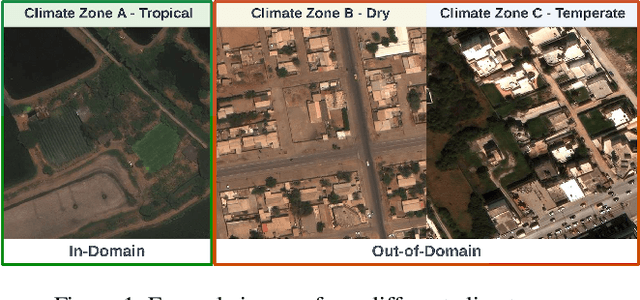
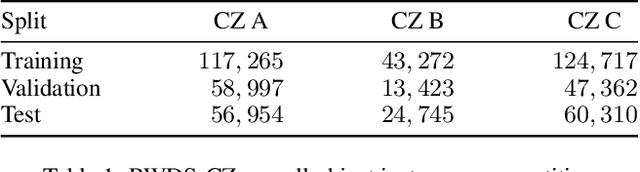
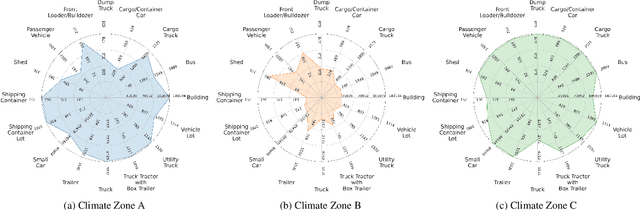
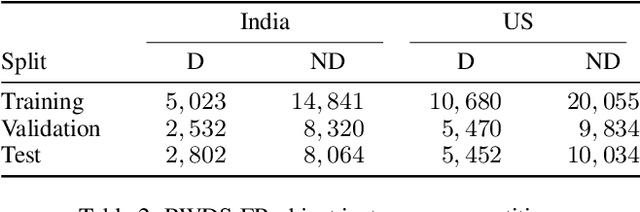
Object detectors have achieved remarkable performance in many applications; however, these deep learning models are typically designed under the i.i.d. assumption, meaning they are trained and evaluated on data sampled from the same (source) distribution. In real-world deployment, however, target distributions often differ from source data, leading to substantial performance degradation. Domain Generalisation (DG) seeks to bridge this gap by enabling models to generalise to Out-Of-Distribution (OOD) data without access to target distributions during training, enhancing robustness to unseen conditions. In this work, we examine the generalisability and robustness of state-of-the-art object detectors under real-world distribution shifts, focusing particularly on spatial domain shifts. Despite the need, a standardised benchmark dataset specifically designed for assessing object detection under realistic DG scenarios is currently lacking. To address this, we introduce Real-World Distribution Shifts (RWDS), a suite of three novel DG benchmarking datasets that focus on humanitarian and climate change applications. These datasets enable the investigation of domain shifts across (i) climate zones and (ii) various disasters and geographic regions. To our knowledge, these are the first DG benchmarking datasets tailored for object detection in real-world, high-impact contexts. We aim for these datasets to serve as valuable resources for evaluating the robustness and generalisation of future object detection models. Our datasets and code are available at https://github.com/RWGAI/RWDS.
Monitoring Critical Infrastructure Facilities During Disasters Using Large Language Models
Apr 18, 2024Critical Infrastructure Facilities (CIFs), such as healthcare and transportation facilities, are vital for the functioning of a community, especially during large-scale emergencies. In this paper, we explore a potential application of Large Language Models (LLMs) to monitor the status of CIFs affected by natural disasters through information disseminated in social media networks. To this end, we analyze social media data from two disaster events in two different countries to identify reported impacts to CIFs as well as their impact severity and operational status. We employ state-of-the-art open-source LLMs to perform computational tasks including retrieval, classification, and inference, all in a zero-shot setting. Through extensive experimentation, we report the results of these tasks using standard evaluation metrics and reveal insights into the strengths and weaknesses of LLMs. We note that although LLMs perform well in classification tasks, they encounter challenges with inference tasks, especially when the context/prompt is complex and lengthy. Additionally, we outline various potential directions for future exploration that can be beneficial during the initial adoption phase of LLMs for disaster response tasks.
Fine-grained Population Mapping from Coarse Census Counts and Open Geodata
Nov 08, 2022Fine-grained population maps are needed in several domains, like urban planning, environmental monitoring, public health, and humanitarian operations. Unfortunately, in many countries only aggregate census counts over large spatial units are collected, moreover, these are not always up-to-date. We present POMELO, a deep learning model that employs coarse census counts and open geodata to estimate fine-grained population maps with 100m ground sampling distance. Moreover, the model can also estimate population numbers when no census counts at all are available, by generalizing across countries. In a series of experiments for several countries in sub-Saharan Africa, the maps produced with POMELOare in good agreement with the most detailed available reference counts: disaggregation of coarse census counts reaches R2 values of 85-89%; unconstrained prediction in the absence of any counts reaches 48-69%.
A Survey on Computer Vision based Human Analysis in the COVID-19 Era
Nov 07, 2022



The emergence of COVID-19 has had a global and profound impact, not only on society as a whole, but also on the lives of individuals. Various prevention measures were introduced around the world to limit the transmission of the disease, including face masks, mandates for social distancing and regular disinfection in public spaces, and the use of screening applications. These developments also triggered the need for novel and improved computer vision techniques capable of (i) providing support to the prevention measures through an automated analysis of visual data, on the one hand, and (ii) facilitating normal operation of existing vision-based services, such as biometric authentication schemes, on the other. Especially important here, are computer vision techniques that focus on the analysis of people and faces in visual data and have been affected the most by the partial occlusions introduced by the mandates for facial masks. Such computer vision based human analysis techniques include face and face-mask detection approaches, face recognition techniques, crowd counting solutions, age and expression estimation procedures, models for detecting face-hand interactions and many others, and have seen considerable attention over recent years. The goal of this survey is to provide an introduction to the problems induced by COVID-19 into such research and to present a comprehensive review of the work done in the computer vision based human analysis field. Particular attention is paid to the impact of facial masks on the performance of various methods and recent solutions to mitigate this problem. Additionally, a detailed review of existing datasets useful for the development and evaluation of methods for COVID-19 related applications is also provided. Finally, to help advance the field further, a discussion on the main open challenges and future research direction is given.
Bias-Aware Face Mask Detection Dataset
Nov 02, 2022In December 2019, a novel coronavirus (COVID-19) spread so quickly around the world that many countries had to set mandatory face mask rules in public areas to reduce the transmission of the virus. To monitor public adherence, researchers aimed to rapidly develop efficient systems that can detect faces with masks automatically. However, the lack of representative and novel datasets proved to be the biggest challenge. Early attempts to collect face mask datasets did not account for potential race, gender, and age biases. Therefore, the resulting models show inherent biases toward specific race groups, such as Asian or Caucasian. In this work, we present a novel face mask detection dataset that contains images posted on Twitter during the pandemic from around the world. Unlike previous datasets, the proposed Bias-Aware Face Mask Detection (BAFMD) dataset contains more images from underrepresented race and age groups to mitigate the problem for the face mask detection task. We perform experiments to investigate potential biases in widely used face mask detection datasets and illustrate that the BAFMD dataset yields models with better performance and generalization ability. The dataset is publicly available at https://github.com/Alpkant/BAFMD.
Learning Program Representations for Food Images and Cooking Recipes
Mar 30, 2022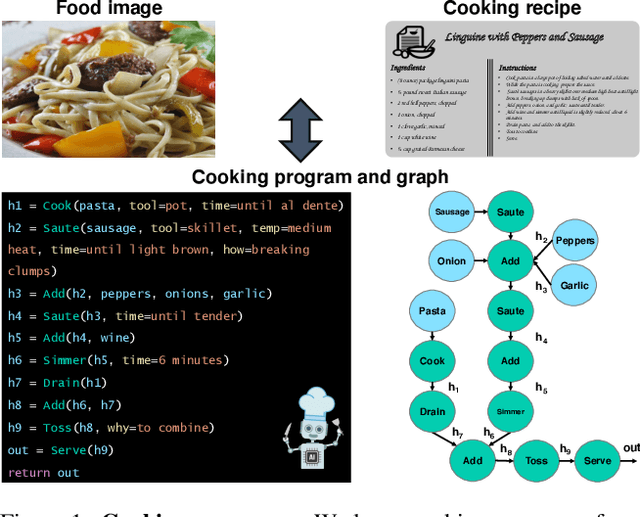
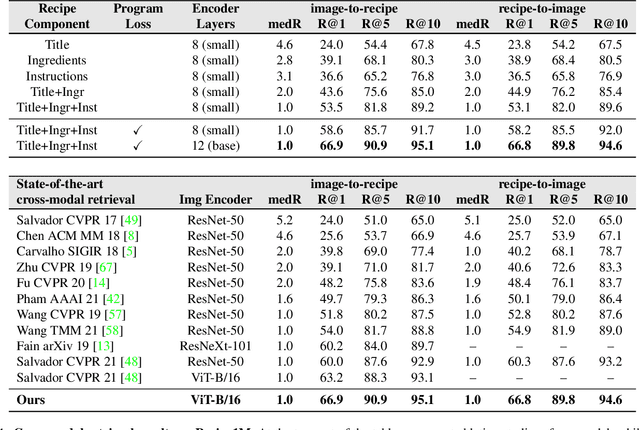
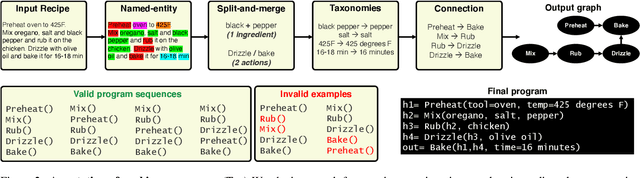
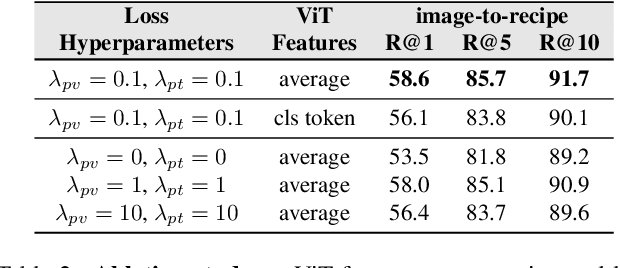
In this paper, we are interested in modeling a how-to instructional procedure, such as a cooking recipe, with a meaningful and rich high-level representation. Specifically, we propose to represent cooking recipes and food images as cooking programs. Programs provide a structured representation of the task, capturing cooking semantics and sequential relationships of actions in the form of a graph. This allows them to be easily manipulated by users and executed by agents. To this end, we build a model that is trained to learn a joint embedding between recipes and food images via self-supervision and jointly generate a program from this embedding as a sequence. To validate our idea, we crowdsource programs for cooking recipes and show that: (a) projecting the image-recipe embeddings into programs leads to better cross-modal retrieval results; (b) generating programs from images leads to better recognition results compared to predicting raw cooking instructions; and (c) we can generate food images by manipulating programs via optimizing the latent code of a GAN. Code, data, and models are available online.
A Real-time System for Detecting Landslide Reports on Social Media using Artificial Intelligence
Feb 14, 2022This paper presents an online system that leverages social media data in real time to identify landslide-related information automatically using state-of-the-art artificial intelligence techniques. The designed system can (i) reduce the information overload by eliminating duplicate and irrelevant content, (ii) identify landslide images, (iii) infer geolocation of the images, and (iv) categorize the user type (organization or person) of the account sharing the information. The system was deployed in February 2020 online at https://landslide-aidr.qcri.org/landslide_system.php to monitor live Twitter data stream and has been running continuously since then to provide time-critical information to partners such as British Geological Survey and European Mediterranean Seismological Centre. We trust this system can both contribute to harvesting of global landslide data for further research and support global landslide maps to facilitate emergency response and decision making.