 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Real-time System for Detecting Landslide Reports on Social Media using Artificial Intelligence
Feb 14, 2022This paper presents an online system that leverages social media data in real time to identify landslide-related information automatically using state-of-the-art artificial intelligence techniques. The designed system can (i) reduce the information overload by eliminating duplicate and irrelevant content, (ii) identify landslide images, (iii) infer geolocation of the images, and (iv) categorize the user type (organization or person) of the account sharing the information. The system was deployed in February 2020 online at https://landslide-aidr.qcri.org/landslide_system.php to monitor live Twitter data stream and has been running continuously since then to provide time-critical information to partners such as British Geological Survey and European Mediterranean Seismological Centre. We trust this system can both contribute to harvesting of global landslide data for further research and support global landslide maps to facilitate emergency response and decision making.
TBCOV: Two Billion Multilingual COVID-19 Tweets with Sentiment, Entity, Geo, and Gender Labels
Oct 04, 2021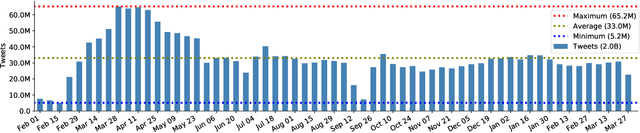

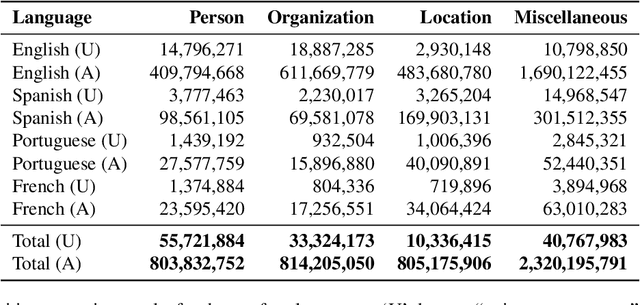

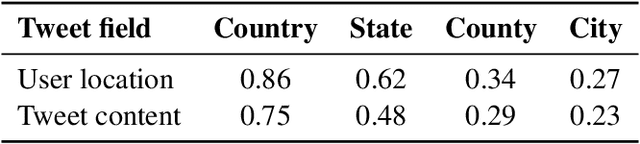
The widespread usage of social networks during mass convergence events, such as health emergencies and disease outbreaks, provides instant access to citizen-generated data that carry rich information about public opinions, sentiments, urgent needs, and situational reports. Such information can help authorities understand the emergent situation and react accordingly. Moreover, social media plays a vital role in tackling misinformation and disinformation. This work presents TBCOV, a large-scale Twitter dataset comprising more than two billion multilingual tweets related to the COVID-19 pandemic collected worldwide over a continuous period of more than one year. More importantly, several state-of-the-art deep learning models are used to enrich the data with important attributes, including sentiment labels, named-entities (e.g., mentions of persons, organizations, locations), user types, and gender information. Last but not least, a geotagging method is proposed to assign country, state, county, and city information to tweets, enabling a myriad of data analysis tasks to understand real-world issues. Our sentiment and trend analyses reveal interesting insights and confirm TBCOV's broad coverage of important topics.
Landslide Detection in Real-Time Social Media Image Streams
Oct 03, 2021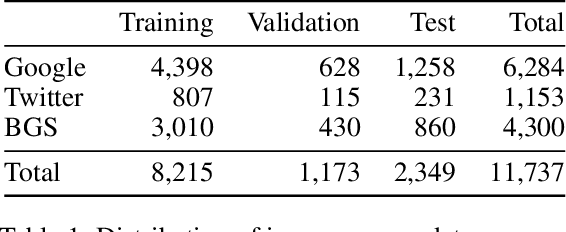

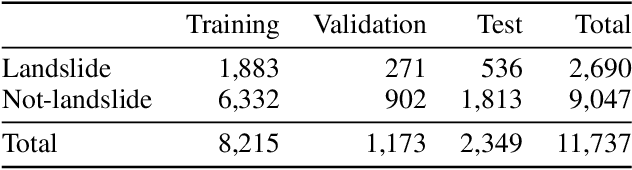
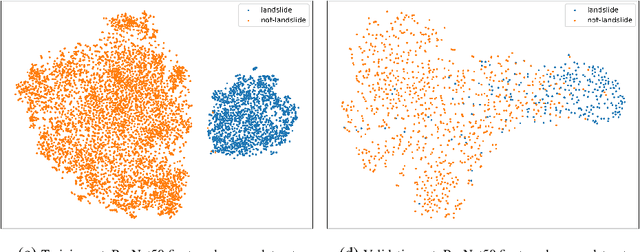
Lack of global data inventories obstructs scientific modeling of and response to landslide hazards which are oftentimes deadly and costly. To remedy this limitation, new approaches suggest solutions based on citizen science that requires active participation. However, as a non-traditional data source, social media has been increasingly used in many disaster response and management studies in recent years. Inspired by this trend, we propose to capitalize on social media data to mine landslide-related information automatically with the help of artificial intelligence (AI) techniques. Specifically, we develop a state-of-the-art computer vision model to detect landslides in social media image streams in real time. To that end, we create a large landslide image dataset labeled by experts and conduct extensive model training experiments. The experimental results indicate that the proposed model can be deployed in an online fashion to support global landslide susceptibility maps and emergency response.
HumAID: Human-Annotated Disaster Incidents Data from Twitter with Deep Learning Benchmarks
Apr 08, 2021
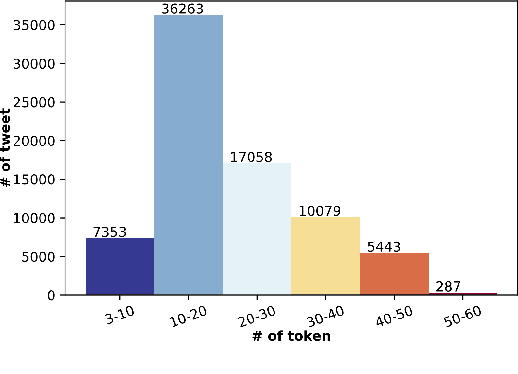


Social networks are widely used for information consumption and dissemination, especially during time-critical events such as natural disasters. Despite its significantly large volume, social media content is often too noisy for direct use in any application. Therefore, it is important to filter, categorize, and concisely summarize the available content to facilitate effective consumption and decision-making. To address such issues automatic classification systems have been developed using supervised modeling approaches, thanks to the earlier efforts on creating labeled datasets. However, existing datasets are limited in different aspects (e.g., size, contains duplicates) and less suitable to support more advanced and data-hungry deep learning models. In this paper, we present a new large-scale dataset with ~77K human-labeled tweets, sampled from a pool of ~24 million tweets across 19 disaster events that happened between 2016 and 2019. Moreover, we propose a data collection and sampling pipeline, which is important for social media data sampling for human annotation. We report multiclass classification results using classic and deep learning (fastText and transformer) based models to set the ground for future studies. The dataset and associated resources are publicly available. https://crisisnlp.qcri.org/humaid_dataset.html
Deep Learning Benchmarks and Datasets for Social Media Image Classification for Disaster Response
Nov 17, 2020

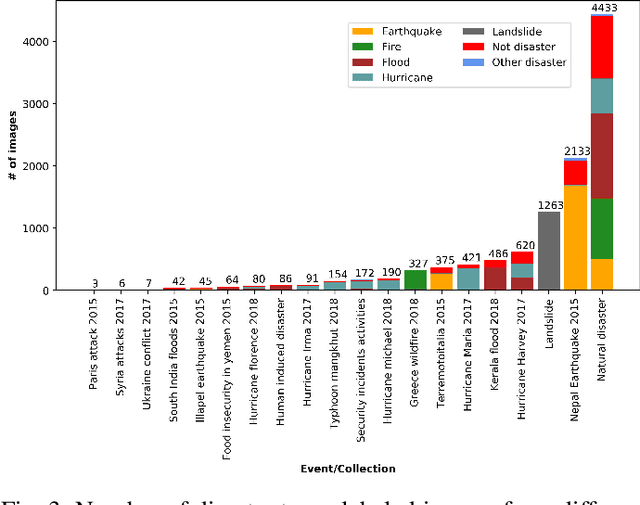
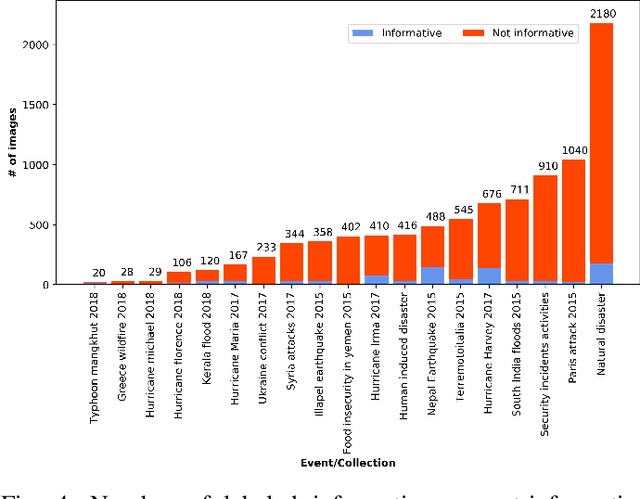
During a disaster event, images shared on social media helps crisis managers gain situational awareness and assess incurred damages, among other response tasks. Recent advances in computer vision and deep neural networks have enabled the development of models for real-time image classification for a number of tasks, including detecting crisis incidents, filtering irrelevant images, classifying images into specific humanitarian categories, and assessing the severity of damage. Despite several efforts, past works mainly suffer from limited resources (i.e., labeled images) available to train more robust deep learning models. In this study, we propose new datasets for disaster type detection, and informativeness classification, and damage severity assessment. Moreover, we relabel existing publicly available datasets for new tasks. We identify exact- and near-duplicates to form non-overlapping data splits, and finally consolidate them to create larger datasets. In our extensive experiments, we benchmark several state-of-the-art deep learning models and achieve promising results. We release our datasets and models publicly, aiming to provide proper baselines as well as to spur further research in the crisis informatics community.
GeoCoV19: A Dataset of Hundreds of Millions of Multilingual COVID-19 Tweets with Location Information
May 22, 2020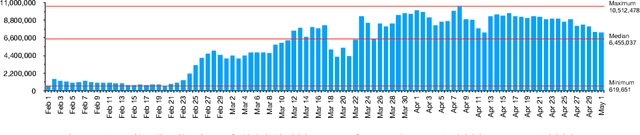


The past several years have witnessed a huge surge in the use of social media platforms during mass convergence events such as health emergencies, natural or human-induced disasters. These non-traditional data sources are becoming vital for disease forecasts and surveillance when preparing for epidemic and pandemic outbreaks. In this paper, we present GeoCoV19, a large-scale Twitter dataset containing more than 524 million multilingual tweets posted over a period of 90 days since February 1, 2020. Moreover, we employ a gazetteer-based approach to infer the geolocation of tweets. We postulate that this large-scale, multilingual, geolocated social media data can empower the research communities to evaluate how societies are collectively coping with this unprecedented global crisis as well as to develop computational methods to address challenges such as identifying fake news, understanding communities' knowledge gaps, building disease forecast and surveillance models, among others.
Rapid Damage Assessment Using Social Media Images by Combining Human and Machine Intelligence
Apr 14, 2020



Rapid damage assessment is one of the core tasks that response organizations perform at the onset of a disaster to understand the scale of damage to infrastructures such as roads, bridges, and buildings. This work analyzes the usefulness of social media imagery content to perform rapid damage assessment during a real-world disaster. An automatic image processing system, which was activated in collaboration with a volunteer response organization, processed ~280K images to understand the extent of damage caused by the disaster. The system achieved an accuracy of 76% computed based on the feedback received from the domain experts who analyzed ~29K system-processed images during the disaster. An extensive error analysis reveals several insights and challenges faced by the system, which are vital for the research community to advance this line of research.