 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEDIC: A Multi-Task Learning Dataset for Disaster Image Classification
Aug 29, 2021
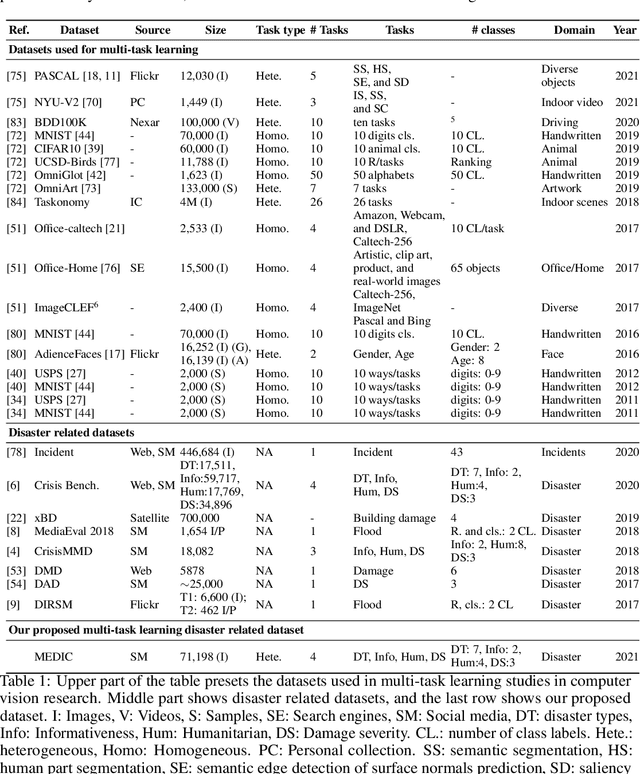
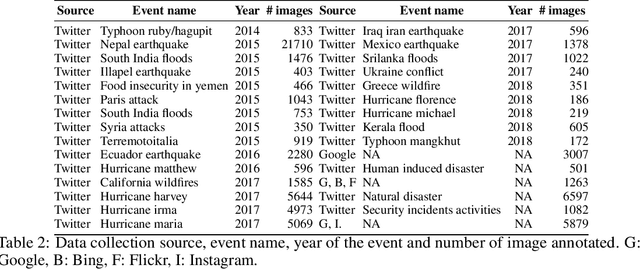

Recent research in disaster informatics demonstrates a practical and important use case of artificial intelligence to save human lives and sufferings during post-natural disasters based on social media contents (text and images). While notable progress has been made using texts, research on exploiting the images remains relatively under-explored. To advance the image-based approach, we propose MEDIC (available at: https://crisisnlp.qcri.org/medic/index.html), which is the largest social media image classification dataset for humanitarian response consisting of 71,198 images to address four different tasks in a multi-task learning setup. This is the first dataset of its kind: social media image, disaster response, and multi-task learning research. An important property of this dataset is its high potential to contribute research on multi-task learning, which recently receives much interest from the machine learning community and has shown remarkable results in terms of memory, inference speed, performance, and generalization capability. Therefore, the proposed dataset is an important resource for advancing image-based disaster management and multi-task machine learning research.
A Review of Bangla Natural Language Processing Tasks and the Utility of Transformer Models
Jul 25, 2021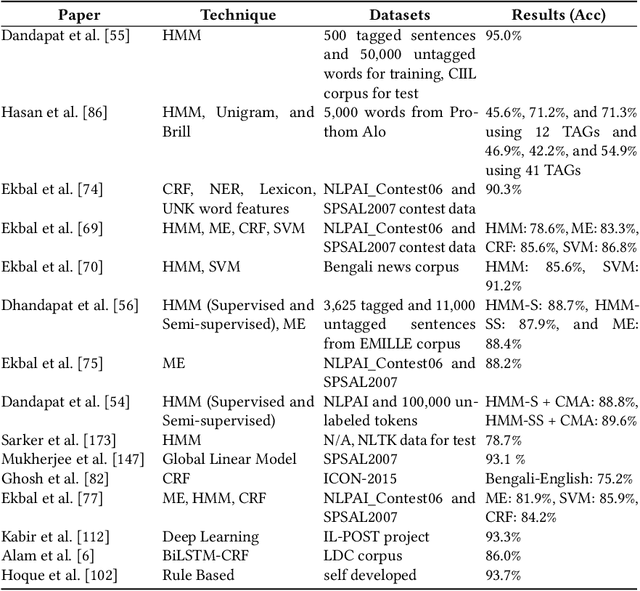
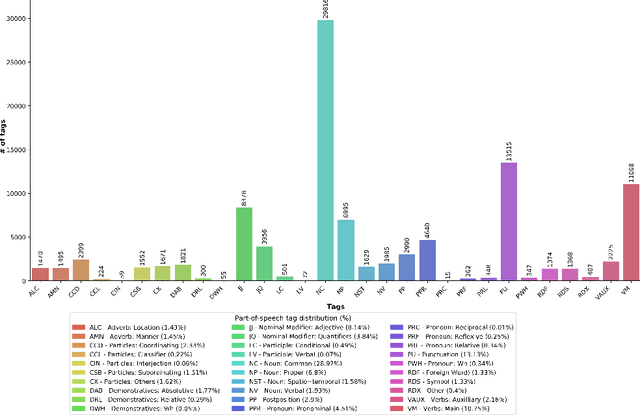
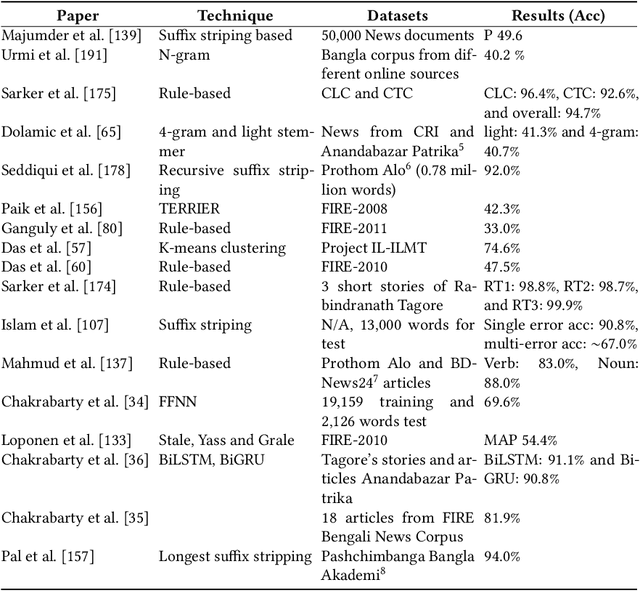
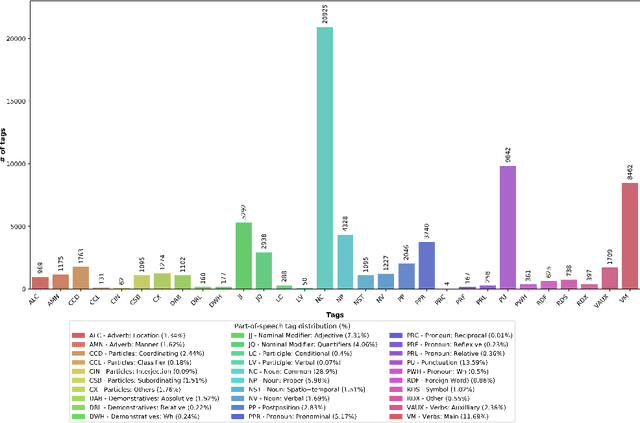
Bangla -- ranked as the 6th most widely spoken language across the world (https://www.ethnologue.com/guides/ethnologue200), with 230 million native speakers -- is still considered as a low-resource language in the natural language processing (NLP) community. With three decades of research, Bangla NLP (BNLP) is still lagging behind mainly due to the scarcity of resources and the challenges that come with it. There is sparse work in different areas of BNLP; however, a thorough survey reporting previous work and recent advances is yet to be done. In this study, we first provide a review of Bangla NLP tasks, resources, and tools available to the research community; we benchmark datasets collected from various platforms for nine NLP tasks using current state-of-the-art algorithms (i.e., transformer-based models). We provide comparative results for the studied NLP tasks by comparing monolingual vs. multilingual models of varying sizes. We report our results using both individual and consolidated datasets and provide data splits for future research. We reviewed a total of 108 papers and conducted 175 sets of experiments. Our results show promising performance using transformer-based models while highlighting the trade-off with computational costs. We hope that such a comprehensive survey will motivate the community to build on and further advance the research on Bangla NLP.
Social Media Images Classification Models for Real-time Disaster Response
Apr 09, 2021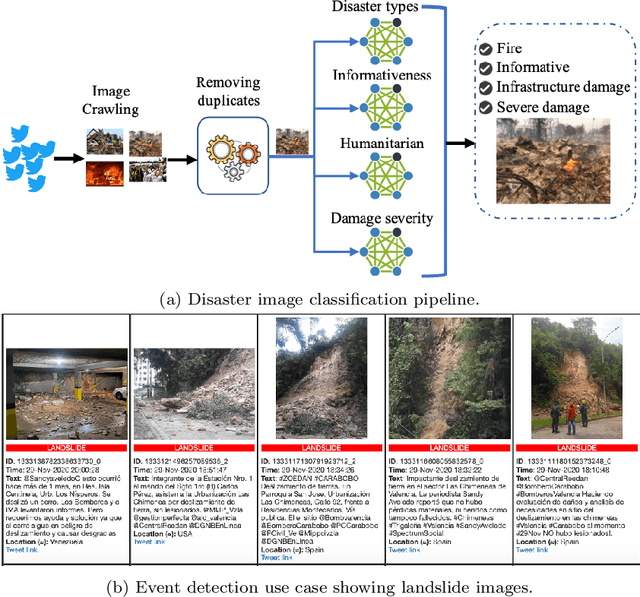
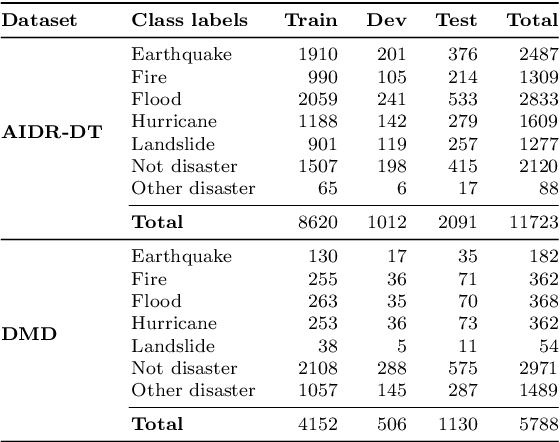

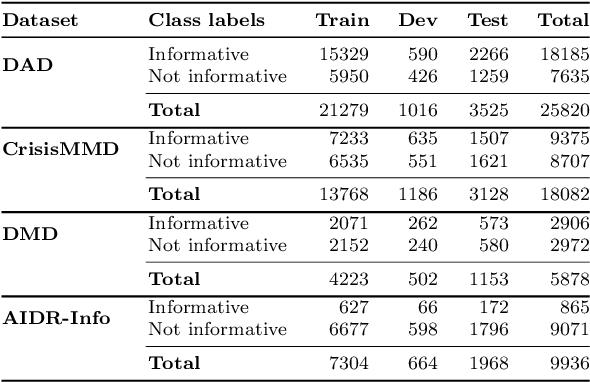
Images shared on social media help crisis managers in terms of gaining situational awareness and assessing incurred damages, among other response tasks. As the volume and velocity of such content are really high, therefore, real-time image classification became an urgent need in order to take a faster response. Recent advances in computer vision and deep neural networks have enabled the development of models for real-time image classification for a number of tasks, including detecting crisis incidents, filtering irrelevant images, classifying images into specific humanitarian categories, and assessing the severity of the damage. For developing real-time robust models, it is necessary to understand the capability of the publicly available pretrained models for these tasks. In the current state-of-art of crisis informatics, it is under-explored. In this study, we address such limitations. We investigate ten different architectures for four different tasks using the largest publicly available datasets for these tasks. We also explore the data augmentation, semi-supervised techniques, and a multitask setup. In our extensive experiments, we achieve promising results.
Deep Learning Benchmarks and Datasets for Social Media Image Classification for Disaster Response
Nov 17, 2020

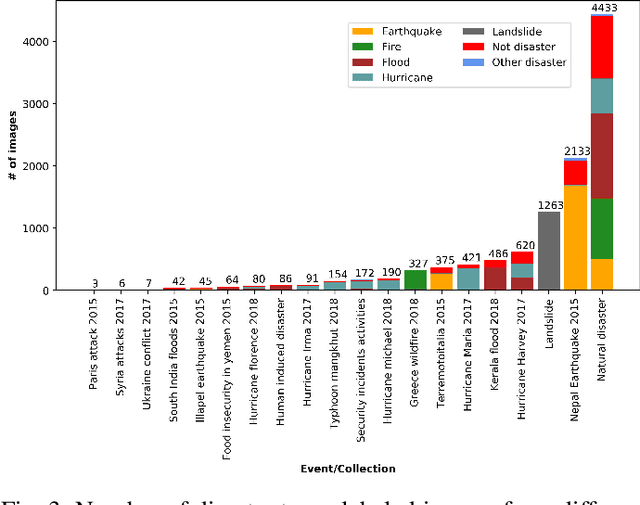
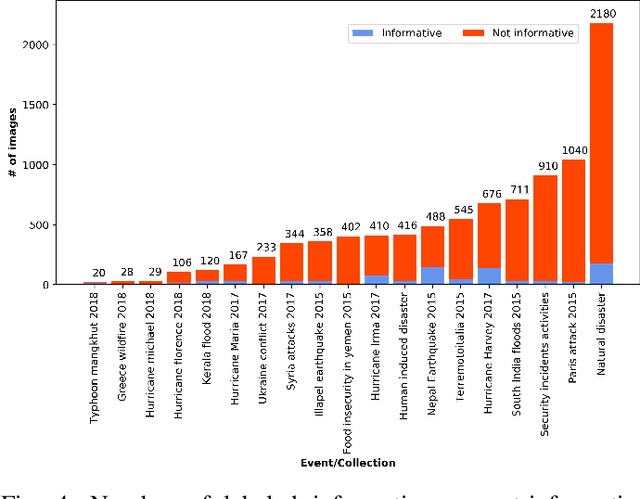
During a disaster event, images shared on social media helps crisis managers gain situational awareness and assess incurred damages, among other response tasks. Recent advances in computer vision and deep neural networks have enabled the development of models for real-time image classification for a number of tasks, including detecting crisis incidents, filtering irrelevant images, classifying images into specific humanitarian categories, and assessing the severity of damage. Despite several efforts, past works mainly suffer from limited resources (i.e., labeled images) available to train more robust deep learning models. In this study, we propose new datasets for disaster type detection, and informativeness classification, and damage severity assessment. Moreover, we relabel existing publicly available datasets for new tasks. We identify exact- and near-duplicates to form non-overlapping data splits, and finally consolidate them to create larger datasets. In our extensive experiments, we benchmark several state-of-the-art deep learning models and achieve promising results. We release our datasets and models publicly, aiming to provide proper baselines as well as to spur further research in the crisis informatics community.
Bangla Text Classification using Transformers
Nov 09, 2020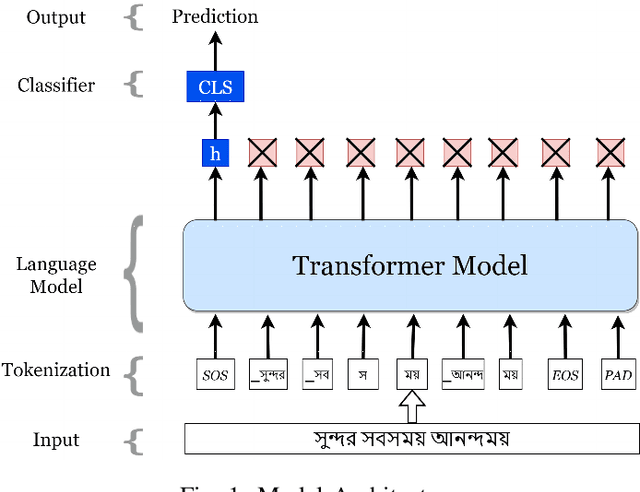
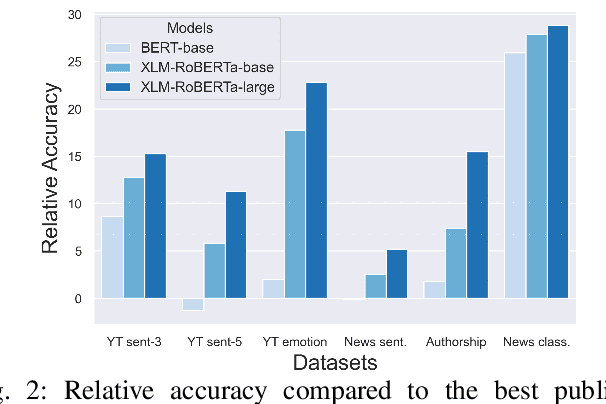
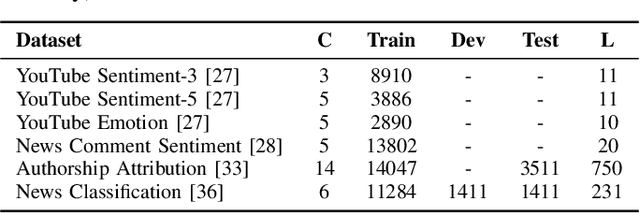
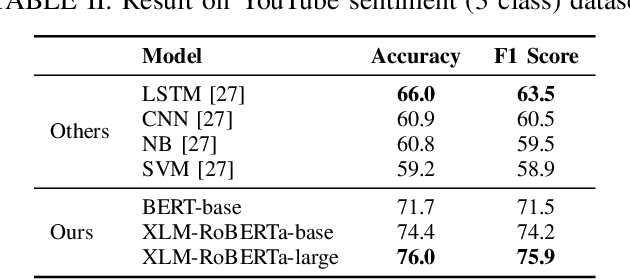
Text classification has been one of the earliest problems in NLP. Over time the scope of application areas has broadened and the difficulty of dealing with new areas (e.g., noisy social media content) has increased. The problem-solving strategy switched from classical machine learning to deep learning algorithms. One of the recent deep neural network architecture is the Transformer. Models designed with this type of network and its variants recently showed their success in many downstream natural language processing tasks, especially for resource-rich languages, e.g., English. However, these models have not been explored fully for Bangla text classification tasks. In this work, we fine-tune multilingual transformer models for Bangla text classification tasks in different domains, including sentiment analysis, emotion detection, news categorization, and authorship attribution. We obtain the state of the art results on six benchmark datasets, improving upon the previous results by 5-29% accuracy across different tasks.