 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBangla Text Classification using Transformers
Paper and Code
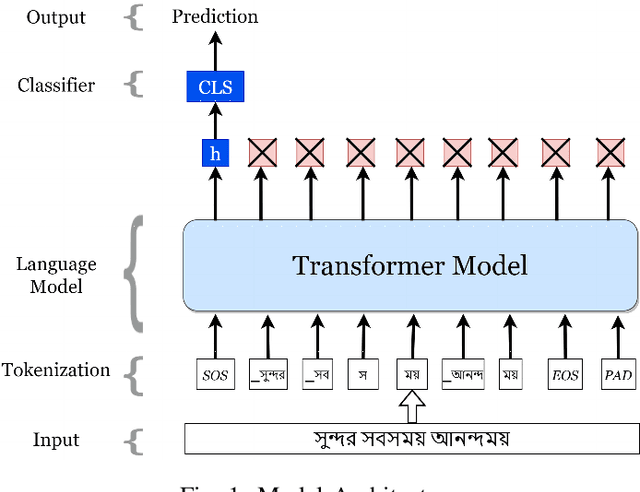
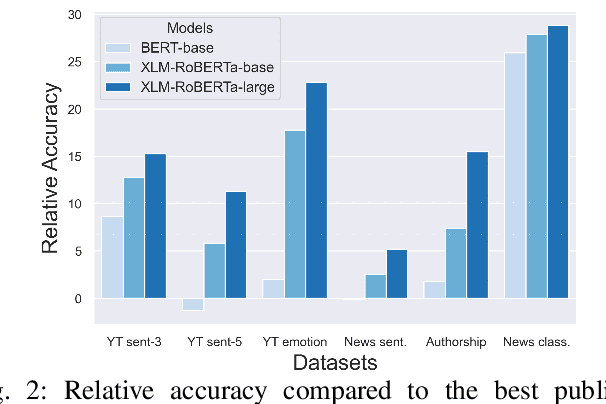
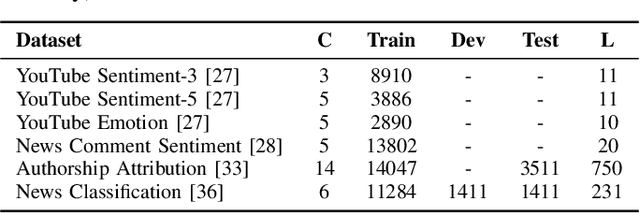
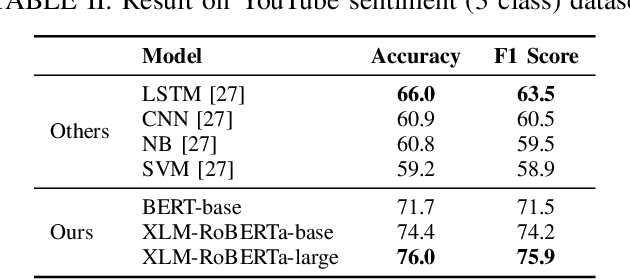
Text classification has been one of the earliest problems in NLP. Over time the scope of application areas has broadened and the difficulty of dealing with new areas (e.g., noisy social media content) has increased. The problem-solving strategy switched from classical machine learning to deep learning algorithms. One of the recent deep neural network architecture is the Transformer. Models designed with this type of network and its variants recently showed their success in many downstream natural language processing tasks, especially for resource-rich languages, e.g., English. However, these models have not been explored fully for Bangla text classification tasks. In this work, we fine-tune multilingual transformer models for Bangla text classification tasks in different domains, including sentiment analysis, emotion detection, news categorization, and authorship attribution. We obtain the state of the art results on six benchmark datasets, improving upon the previous results by 5-29% accuracy across different tasks.