 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncongruity Detection between Bangla News Headline and Body Content through Graph Neural Network
Oct 26, 2022

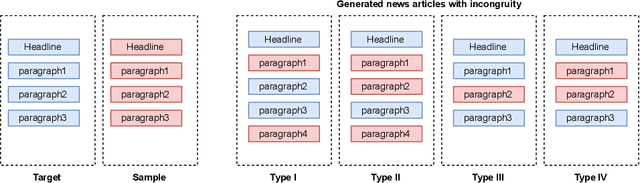

Incongruity between news headlines and the body content is a common method of deception used to attract readers. Profitable headlines pique readers' interest and encourage them to visit a specific website. This is usually done by adding an element of dishonesty, using enticements that do not precisely reflect the content being delivered. As a result, automatic detection of incongruent news between headline and body content using language analysis has gained the research community's attention. However, various solutions are primarily being developed for English to address this problem, leaving low-resource languages out of the picture. Bangla is ranked 7th among the top 100 most widely spoken languages, which motivates us to pay special attention to the Bangla language. Furthermore, Bangla has a more complex syntactic structure and fewer natural language processing resources, so it becomes challenging to perform NLP tasks like incongruity detection and stance detection. To tackle this problem, for the Bangla language, we offer a graph-based hierarchical dual encoder (BGHDE) model that learns the content similarity and contradiction between Bangla news headlines and content paragraphs effectively. The experimental results show that the proposed Bangla graph-based neural network model achieves above 90% accuracy on various Bangla news datasets.
A Review of Bangla Natural Language Processing Tasks and the Utility of Transformer Models
Jul 25, 2021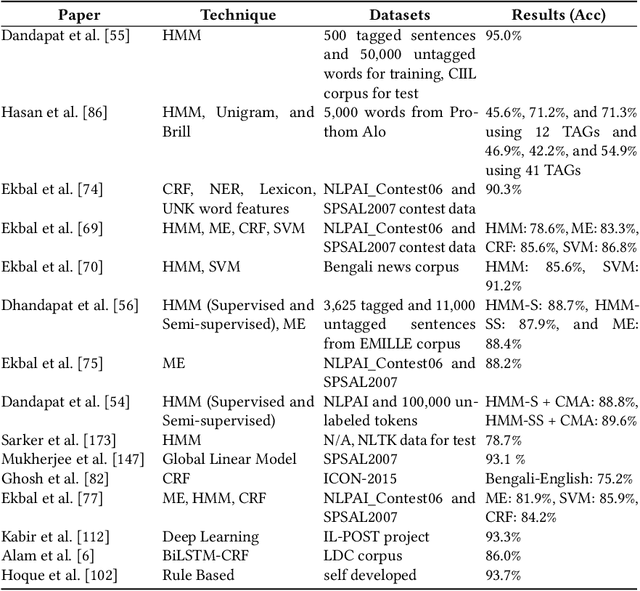
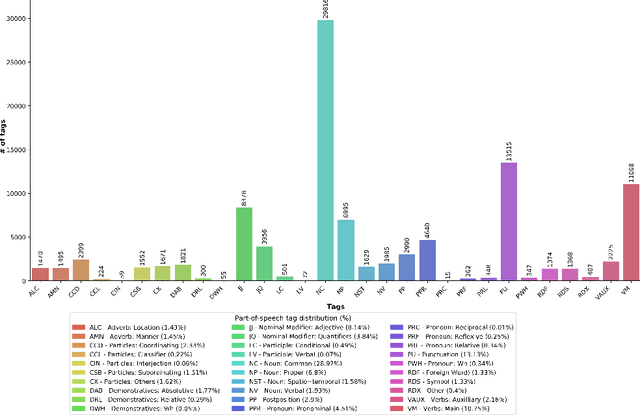
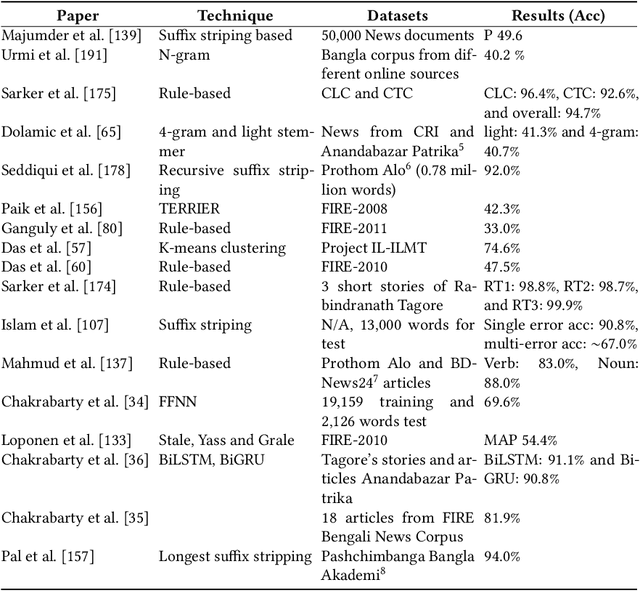
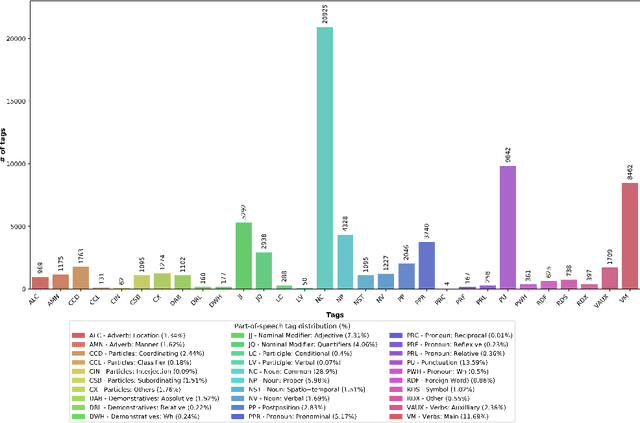
Bangla -- ranked as the 6th most widely spoken language across the world (https://www.ethnologue.com/guides/ethnologue200), with 230 million native speakers -- is still considered as a low-resource language in the natural language processing (NLP) community. With three decades of research, Bangla NLP (BNLP) is still lagging behind mainly due to the scarcity of resources and the challenges that come with it. There is sparse work in different areas of BNLP; however, a thorough survey reporting previous work and recent advances is yet to be done. In this study, we first provide a review of Bangla NLP tasks, resources, and tools available to the research community; we benchmark datasets collected from various platforms for nine NLP tasks using current state-of-the-art algorithms (i.e., transformer-based models). We provide comparative results for the studied NLP tasks by comparing monolingual vs. multilingual models of varying sizes. We report our results using both individual and consolidated datasets and provide data splits for future research. We reviewed a total of 108 papers and conducted 175 sets of experiments. Our results show promising performance using transformer-based models while highlighting the trade-off with computational costs. We hope that such a comprehensive survey will motivate the community to build on and further advance the research on Bangla NLP.
Bangla Text Classification using Transformers
Nov 09, 2020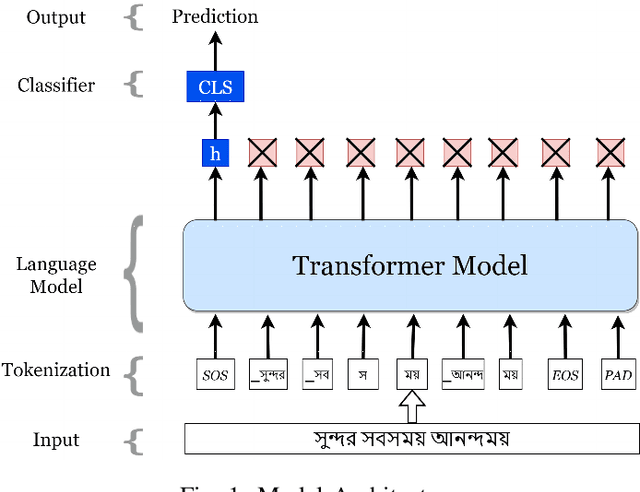
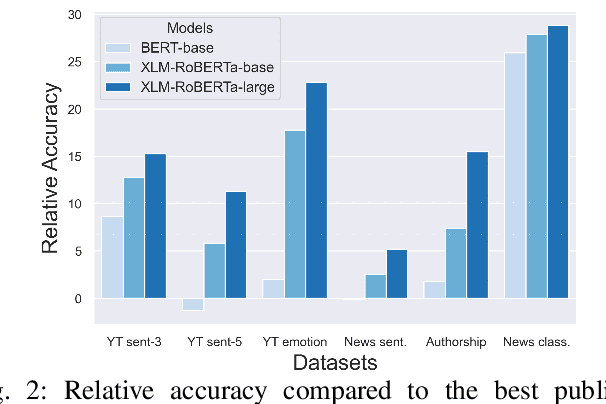
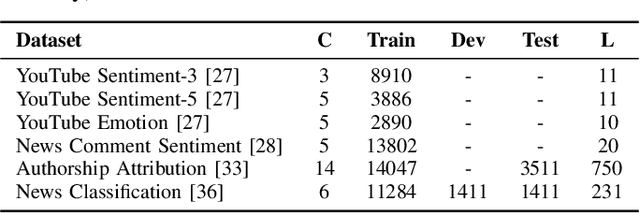
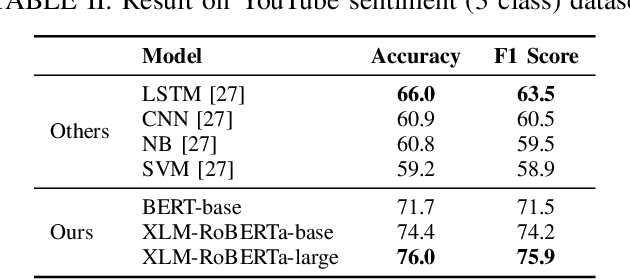
Text classification has been one of the earliest problems in NLP. Over time the scope of application areas has broadened and the difficulty of dealing with new areas (e.g., noisy social media content) has increased. The problem-solving strategy switched from classical machine learning to deep learning algorithms. One of the recent deep neural network architecture is the Transformer. Models designed with this type of network and its variants recently showed their success in many downstream natural language processing tasks, especially for resource-rich languages, e.g., English. However, these models have not been explored fully for Bangla text classification tasks. In this work, we fine-tune multilingual transformer models for Bangla text classification tasks in different domains, including sentiment analysis, emotion detection, news categorization, and authorship attribution. We obtain the state of the art results on six benchmark datasets, improving upon the previous results by 5-29% accuracy across different tasks.