 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumAID: Human-Annotated Disaster Incidents Data from Twitter with Deep Learning Benchmarks
Paper and Code
Apr 08, 2021
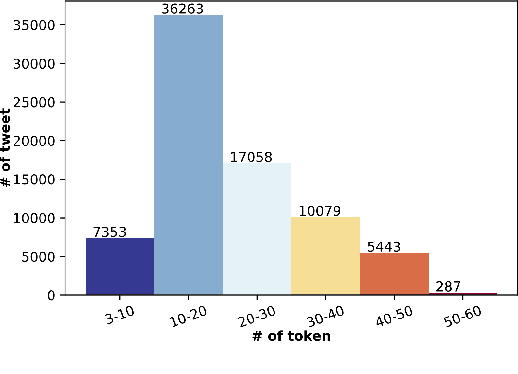


Social networks are widely used for information consumption and dissemination, especially during time-critical events such as natural disasters. Despite its significantly large volume, social media content is often too noisy for direct use in any application. Therefore, it is important to filter, categorize, and concisely summarize the available content to facilitate effective consumption and decision-making. To address such issues automatic classification systems have been developed using supervised modeling approaches, thanks to the earlier efforts on creating labeled datasets. However, existing datasets are limited in different aspects (e.g., size, contains duplicates) and less suitable to support more advanced and data-hungry deep learning models. In this paper, we present a new large-scale dataset with ~77K human-labeled tweets, sampled from a pool of ~24 million tweets across 19 disaster events that happened between 2016 and 2019. Moreover, we propose a data collection and sampling pipeline, which is important for social media data sampling for human annotation. We report multiclass classification results using classic and deep learning (fastText and transformer) based models to set the ground for future studies. The dataset and associated resources are publicly available. https://crisisnlp.qcri.org/humaid_dataset.html