 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Safe and Accountable GenAI as a Learning Companion with Women Banned from Formal Education
Apr 08, 2026In gender-restrictive and surveilled contexts, where access to formal education may be restricted for women, pursuing education involves safety and privacy risks. When women are excluded from schools and universities, they often turn to online self-learning and generative AI (GenAI) to pursue their educational and career aspirations. However, we know little about what safe and accountable GenAI support is required in the context of surveillance, household responsibilities, and the absence of learning communities. We present a remote participatory design study with 20 women in Afghanistan, informed by a recruitment survey (n = 140), examining how participants envision GenAI for learning and employability. Participants describe using GenAI less as an information source and more as an always-available peer, mentor, and source of career guidance that helps compensate for the absence of learning communities. At the same time, they emphasize that this companionship is constrained by privacy and surveillance risks, contextually unrealistic and culturally unsafe support, and direct-answer interactions that can undermine learning by creating an illusion of progress. Beyond eliciting requirements, envisioning the future with GenAI through participatory design was positively associated with significant increases in participants' aspirations (p=.01), perceived agency (p=.01), and perceived avenues (p=.03). These outcomes show that accountable and safe GenAI is not only about harm reduction but can also actively enable women to imagine and pursue viable learning and employment futures. Building on this, we translate participants' proposals into accountability-focused design directions that center on safety-first interaction and user control, context-grounded support under constrained resources, and offer pedagogically aligned assistance that supports genuine learning rather than quick answers.
Challenges of Evaluating LLM Safety for User Welfare
Dec 11, 2025Safety evaluations of large language models (LLMs) typically focus on universal risks like dangerous capabilities or undesirable propensities. However, millions use LLMs for personal advice on high-stakes topics like finance and health, where harms are context-dependent rather than universal. While frameworks like the OECD's AI classification recognize the need to assess individual risks, user-welfare safety evaluations remain underdeveloped. We argue that developing such evaluations is non-trivial due to fundamental questions about accounting for user context in evaluation design. In this exploratory study, we evaluated advice on finance and health from GPT-5, Claude Sonnet 4, and Gemini 2.5 Pro across user profiles of varying vulnerability. First, we demonstrate that evaluators must have access to rich user context: identical LLM responses were rated significantly safer by context-blind evaluators than by those aware of user circumstances, with safety scores for high-vulnerability users dropping from safe (5/7) to somewhat unsafe (3/7). One might assume this gap could be addressed by creating realistic user prompts containing key contextual information. However, our second study challenges this: we rerun the evaluation on prompts containing context users report they would disclose, finding no significant improvement. Our work establishes that effective user-welfare safety evaluation requires evaluators to assess responses against diverse user profiles, as realistic user context disclosure alone proves insufficient, particularly for vulnerable populations. By demonstrating a methodology for context-aware evaluation, this study provides both a starting point for such assessments and foundational evidence that evaluating individual welfare demands approaches distinct from existing universal-risk frameworks. We publish our code and dataset to aid future developments.
Hope, Aspirations, and the Impact of LLMs on Female Programming Learners in Afghanistan
Nov 09, 2025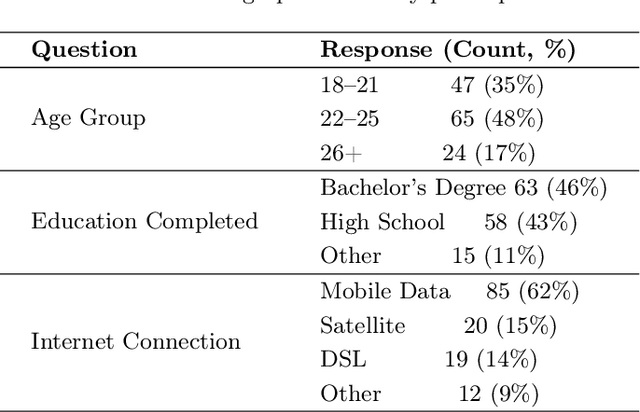
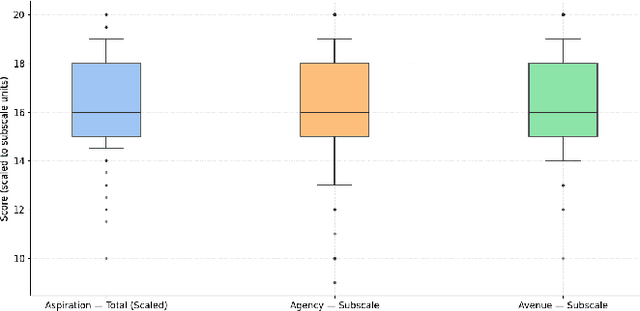
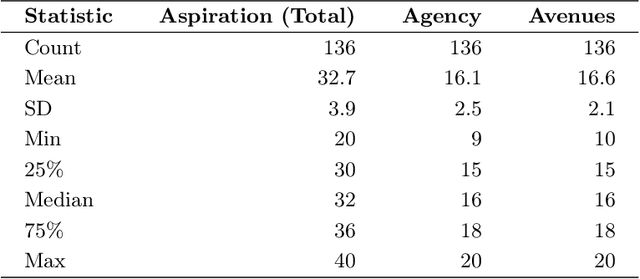
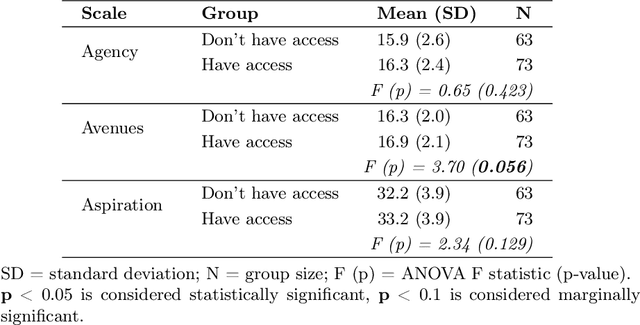
Designing impactful educational technologies in contexts of socio-political instability requires a nuanced understanding of educational aspirations. Currently, scalable metrics for measuring aspirations are limited. This study adapts, translates, and evaluates Snyder's Hope Scale as a metric for measuring aspirations among 136 women learning programming online during a period of systemic educational restrictions in Afghanistan. The adapted scale demonstrated good reliability (Cronbach's α = 0.78) and participants rated it as understandable and relevant. While overall aspiration-related scores did not differ significantly by access to Large Language Models (LLMs), those with access reported marginally higher scores on the Avenues subscale (p = .056), suggesting broader perceived pathways to achieving educational aspirations. These findings support the use of the adapted scale as a metric for aspirations in contexts of socio-political instability. More broadly, the adapted scale can be used to evaluate the impact of aspiration-driven design of educational technologies.
VME: A Satellite Imagery Dataset and Benchmark for Detecting Vehicles in the Middle East and Beyond
May 28, 2025Detecting vehicles in satellite images is crucial for traffic management, urban planning, and disaster response. However, current models struggle with real-world diversity, particularly across different regions. This challenge is amplified by geographic bias in existing datasets, which often focus on specific areas and overlook regions like the Middle East. To address this gap, we present the Vehicles in the Middle East (VME) dataset, designed explicitly for vehicle detection in high-resolution satellite images from Middle Eastern countries. Sourced from Maxar, the VME dataset spans 54 cities across 12 countries, comprising over 4,000 image tiles and more than 100,000 vehicles, annotated using both manual and semi-automated methods. Additionally, we introduce the largest benchmark dataset for Car Detection in Satellite Imagery (CDSI), combining images from multiple sources to enhance global car detection. Our experiments demonstrate that models trained on existing datasets perform poorly on Middle Eastern images, while the VME dataset significantly improves detection accuracy in this region. Moreover, state-of-the-art models trained on CDSI achieve substantial improvements in global car detection.
Misleading through Inconsistency: A Benchmark for Political Inconsistencies Detection
May 25, 2025Inconsistent political statements represent a form of misinformation. They erode public trust and pose challenges to accountability, when left unnoticed. Detecting inconsistencies automatically could support journalists in asking clarification questions, thereby helping to keep politicians accountable. We propose the Inconsistency detection task and develop a scale of inconsistency types to prompt NLP-research in this direction. To provide a resource for detecting inconsistencies in a political domain, we present a dataset of 698 human-annotated pairs of political statements with explanations of the annotators' reasoning for 237 samples. The statements mainly come from voting assistant platforms such as Wahl-O-Mat in Germany and Smartvote in Switzerland, reflecting real-world political issues. We benchmark Large Language Models (LLMs) on our dataset and show that in general, they are as good as humans at detecting inconsistencies, and might be even better than individual humans at predicting the crowd-annotated ground-truth. However, when it comes to identifying fine-grained inconsistency types, none of the model have reached the upper bound of performance (due to natural labeling variation), thus leaving room for improvement. We make our dataset and code publicly available.
A Weak Supervision Learning Approach Towards an Equitable Parking Lot Occupancy Estimation
May 07, 2025



The scarcity and high cost of labeled high-resolution imagery have long challenged remote sensing applications, particularly in low-income regions where high-resolution data are scarce. In this study, we propose a weak supervision framework that estimates parking lot occupancy using 3m resolution satellite imagery. By leveraging coarse temporal labels -- based on the assumption that parking lots of major supermarkets and hardware stores in Germany are typically full on Saturdays and empty on Sundays -- we train a pairwise comparison model that achieves an AUC of 0.92 on large parking lots. The proposed approach minimizes the reliance on expensive high-resolution images and holds promise for scalable urban mobility analysis. Moreover, the method can be adapted to assess transit patterns and resource allocation in vulnerable communities, providing a data-driven basis to improve the well-being of those most in need.
Coverage Biases in High-Resolution Satellite Imagery
May 05, 2025Satellite imagery is increasingly used to complement traditional data collection approaches such as surveys and censuses across scientific disciplines. However, we ask: Do all places on earth benefit equally from this new wealth of information? In this study, we investigate coverage bias of major satellite constellations that provide optical satellite imagery with a ground sampling distance below 10 meters, evaluating both the future on-demand tasking opportunities as well as the availability of historic images across the globe. Specifically, forward-looking, we estimate how often different places are revisited during a window of 30 days based on the satellites' orbital paths, thus investigating potential coverage biases caused by physical factors. We find that locations farther away from the equator are generally revisited more frequently by the constellations under study. Backward-looking, we show that historic satellite image availability -- based on metadata collected from major satellite imagery providers -- is influenced by socio-economic factors on the ground: less developed, less populated places have less satellite images available. Furthermore, in three small case studies on recent conflict regions in this world, namely Gaza, Sudan and Ukraine, we show that also geopolitical events play an important role in satellite image availability, hinting at underlying business model decisions. These insights lay bare that the digital dividend yielded by satellite imagery is not equally distributed across our planet.
Ten Years after ImageNet: A 360° Perspective on AI
Oct 01, 2022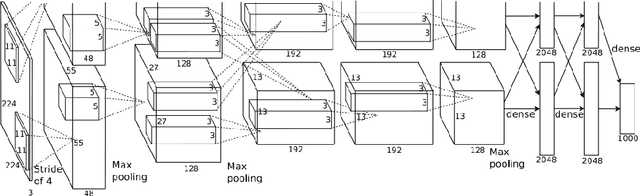
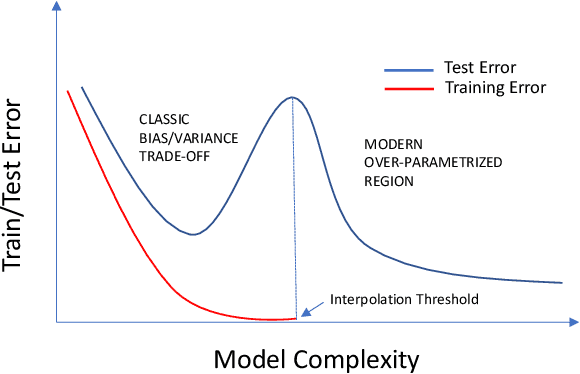
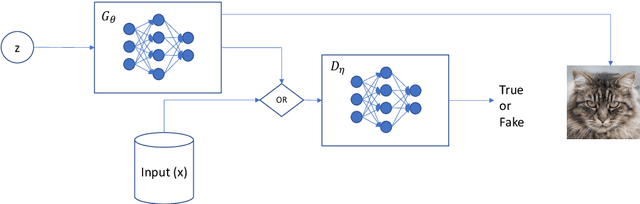
It is ten years since neural networks made their spectacular comeback. Prompted by this anniversary, we take a holistic perspective on Artificial Intelligence (AI). Supervised Learning for cognitive tasks is effectively solved - provided we have enough high-quality labeled data. However, deep neural network models are not easily interpretable, and thus the debate between blackbox and whitebox modeling has come to the fore. The rise of attention networks, self-supervised learning, generative modeling, and graph neural networks has widened the application space of AI. Deep Learning has also propelled the return of reinforcement learning as a core building block of autonomous decision making systems. The possible harms made possible by new AI technologies have raised socio-technical issues such as transparency, fairness, and accountability. The dominance of AI by Big-Tech who control talent, computing resources, and most importantly, data may lead to an extreme AI divide. Failure to meet high expectations in high profile, and much heralded flagship projects like self-driving vehicles could trigger another AI winter.
Going beyond accuracy: estimating homophily in social networks using predictions
Jan 30, 2020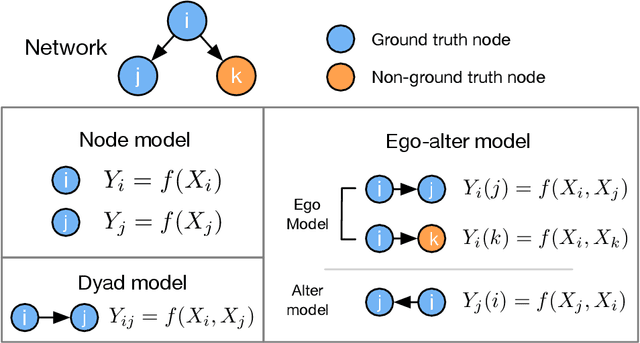
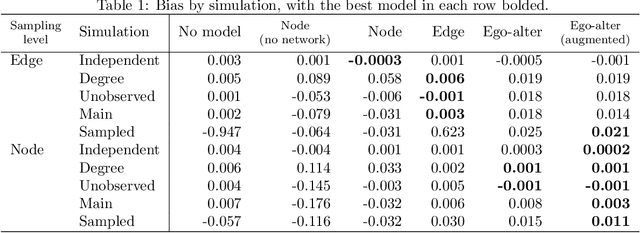
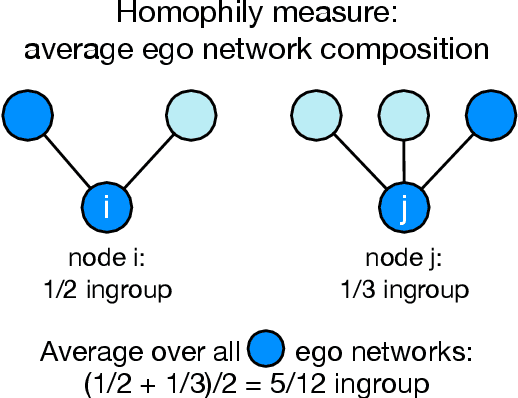
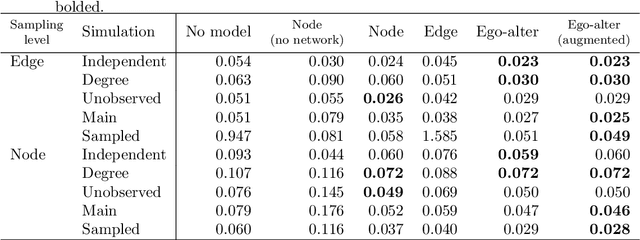
In online social networks, it is common to use predictions of node categories to estimate measures of homophily and other relational properties. However, online social network data often lacks basic demographic information about the nodes. Researchers must rely on predicted node attributes to estimate measures of homophily, but little is known about the validity of these measures. We show that estimating homophily in a network can be viewed as a dyadic prediction problem, and that homophily estimates are unbiased when dyad-level residuals sum to zero in the network. Node-level prediction models, such as the use of names to classify ethnicity or gender, do not generally have this property and can introduce large biases into homophily estimates. Bias occurs due to error autocorrelation along dyads. Importantly, node-level classification performance is not a reliable indicator of estimation accuracy for homophily. We compare estimation strategies that make predictions at the node and dyad levels, evaluating performance in different settings. We propose a novel "ego-alter" modeling approach that outperforms standard node and dyad classification strategies. While this paper focuses on homophily, results generalize to other relational measures which aggregate predictions along the dyads in a network. We conclude with suggestions for research designs to study homophily in online networks. Code for this paper is available at https://github.com/georgeberry/autocorr.
How to make a pizza: Learning a compositional layer-based GAN model
Jun 06, 2019
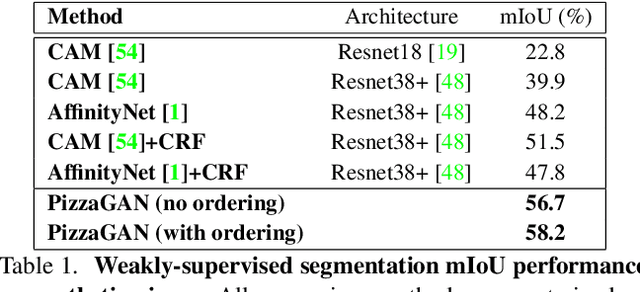


A food recipe is an ordered set of instructions for preparing a particular dish. From a visual perspective, every instruction step can be seen as a way to change the visual appearance of the dish by adding extra objects (e.g., adding an ingredient) or changing the appearance of the existing ones (e.g., cooking the dish). In this paper, we aim to teach a machine how to make a pizza by building a generative model that mirrors this step-by-step procedure. To do so, we learn composable module operations which are able to either add or remove a particular ingredient. Each operator is designed as a Generative Adversarial Network (GAN). Given only weak image-level supervision, the operators are trained to generate a visual layer that needs to be added to or removed from the existing image. The proposed model is able to decompose an image into an ordered sequence of layers by applying sequentially in the right order the corresponding removing modules. Experimental results on synthetic and real pizza images demonstrate that our proposed model is able to: (1) segment pizza toppings in a weaklysupervised fashion, (2) remove them by revealing what is occluded underneath them (i.e., inpainting), and (3) infer the ordering of the toppings without any depth ordering supervision. Code, data, and models are available online.