 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Supervised Domain Adaptation by Augmenting Pre-trained Models with Random Units
Jun 09, 2021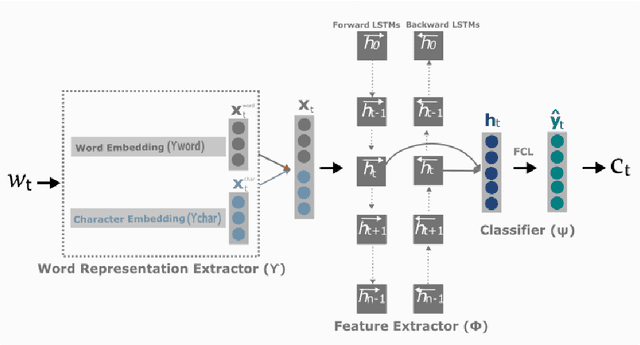
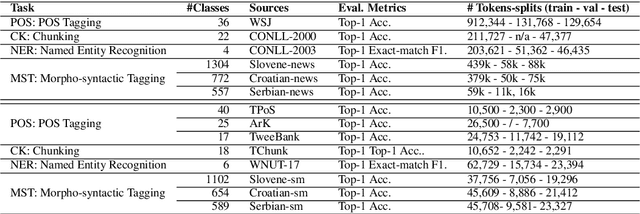
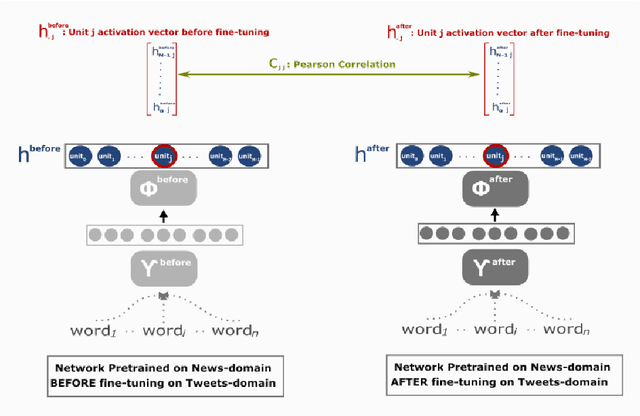

Neural Transfer Learning (TL) is becoming ubiquitous in Natural Language Processing (NLP), thanks to its high performance on many tasks, especially in low-resourced scenarios. Notably, TL is widely used for neural domain adaptation to transfer valuable knowledge from high-resource to low-resource domains. In the standard fine-tuning scheme of TL, a model is initially pre-trained on a source domain and subsequently fine-tuned on a target domain and, therefore, source and target domains are trained using the same architecture. In this paper, we show through interpretation methods that such scheme, despite its efficiency, is suffering from a main limitation. Indeed, although capable of adapting to new domains, pre-trained neurons struggle with learning certain patterns that are specific to the target domain. Moreover, we shed light on the hidden negative transfer occurring despite the high relatedness between source and target domains, which may mitigate the final gain brought by transfer learning. To address these problems, we propose to augment the pre-trained model with normalised, weighted and randomly initialised units that foster a better adaptation while maintaining the valuable source knowledge. We show that our approach exhibits significant improvements to the standard fine-tuning scheme for neural domain adaptation from the news domain to the social media domain on four NLP tasks: part-of-speech tagging, chunking, named entity recognition and morphosyntactic tagging.
Where is the Fake? Patch-Wise Supervised GANs for Texture Inpainting
Nov 06, 2019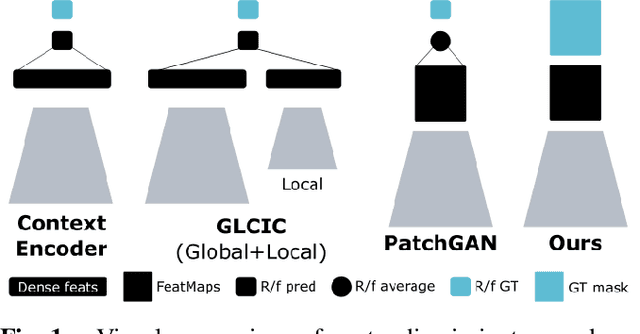
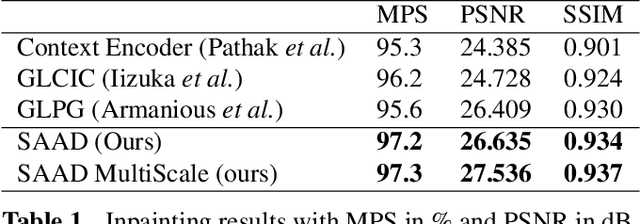

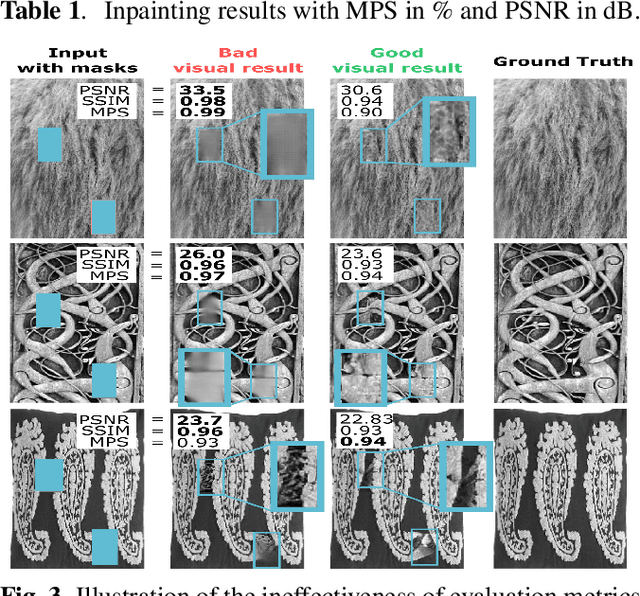
We tackle the problem of texture inpainting where the input images are textures with missing values along with masks that indicate the zones that should be generated. Many works have been done in image inpainting with the aim to achieve global and local consistency. But these works still suffer from limitations when dealing with textures. In fact, the local information in the image to be completed needs to be used in order to achieve local continuities and visually realistic texture inpainting. For this, we propose a new segmentor discriminator that performs a patch-wise real/fake classification and is supervised by input masks. During training, it aims to locate the fake and thus backpropagates consistent signal to the generator. We tested our approach on the publicly available DTD dataset and showed that it achieves state-of-the-art performances and better deals with local consistency than existing methods.
How to make a pizza: Learning a compositional layer-based GAN model
Jun 06, 2019
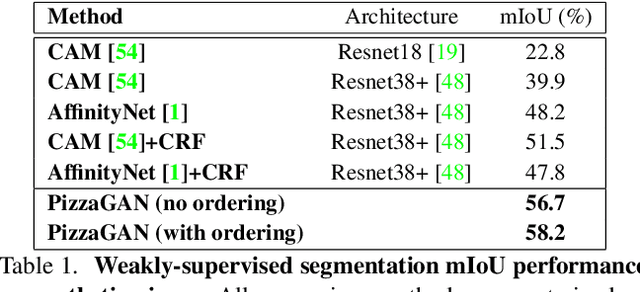


A food recipe is an ordered set of instructions for preparing a particular dish. From a visual perspective, every instruction step can be seen as a way to change the visual appearance of the dish by adding extra objects (e.g., adding an ingredient) or changing the appearance of the existing ones (e.g., cooking the dish). In this paper, we aim to teach a machine how to make a pizza by building a generative model that mirrors this step-by-step procedure. To do so, we learn composable module operations which are able to either add or remove a particular ingredient. Each operator is designed as a Generative Adversarial Network (GAN). Given only weak image-level supervision, the operators are trained to generate a visual layer that needs to be added to or removed from the existing image. The proposed model is able to decompose an image into an ordered sequence of layers by applying sequentially in the right order the corresponding removing modules. Experimental results on synthetic and real pizza images demonstrate that our proposed model is able to: (1) segment pizza toppings in a weaklysupervised fashion, (2) remove them by revealing what is occluded underneath them (i.e., inpainting), and (3) infer the ordering of the toppings without any depth ordering supervision. Code, data, and models are available online.
Joint Learning of Pre-Trained and Random Units for Domain Adaptation in Part-of-Speech Tagging
Apr 07, 2019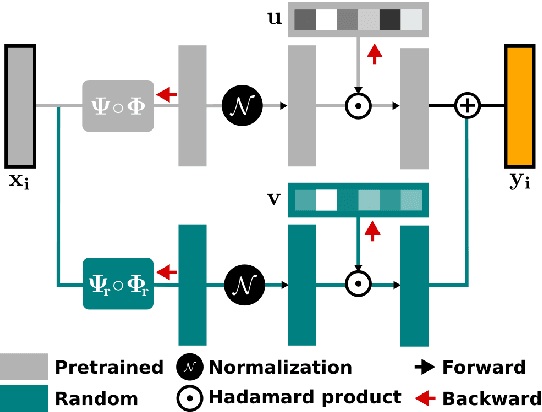
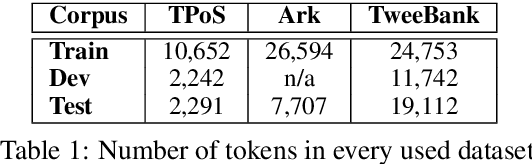
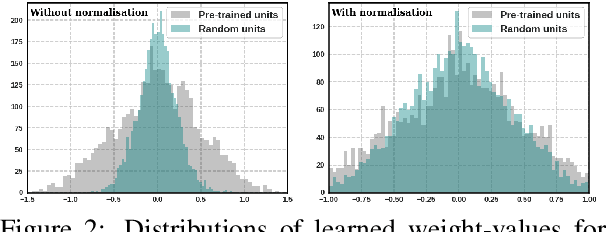
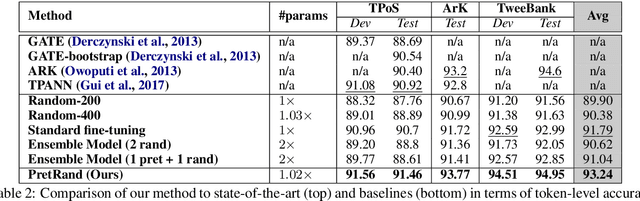
Fine-tuning neural networks is widely used to transfer valuable knowledge from high-resource to low-resource domains. In a standard fine-tuning scheme, source and target problems are trained using the same architecture. Although capable of adapting to new domains, pre-trained units struggle with learning uncommon target-specific patterns. In this paper, we propose to augment the target-network with normalised, weighted and randomly initialised units that beget a better adaptation while maintaining the valuable source knowledge. Our experiments on POS tagging of social media texts (Tweets domain) demonstrate that our method achieves state-of-the-art performances on 3 commonly used datasets.
Deep Multi-class Adversarial Specularity Removal
Apr 04, 2019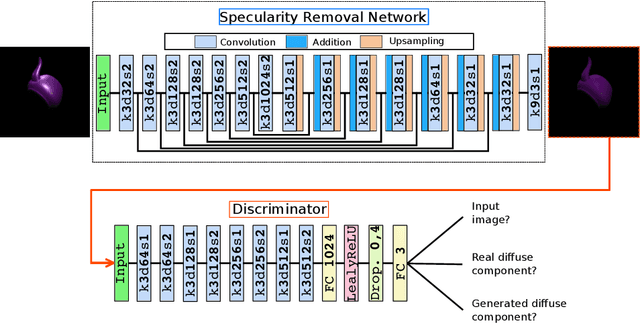

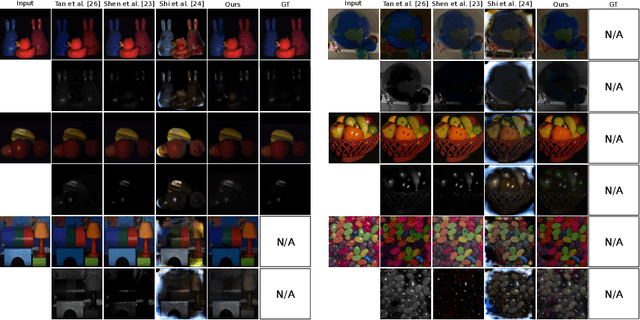
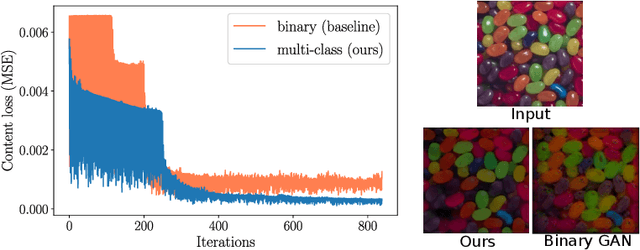
We propose a novel learning approach, in the form of a fully-convolutional neural network (CNN), which automatically and consistently removes specular highlights from a single image by generating its diffuse component. To train the generative network, we define an adversarial loss on a discriminative network as in the GAN framework and combined it with a content loss. In contrast to existing GAN approaches, we implemented the discriminator to be a multi-class classifier instead of a binary one, to find more constraining features. This helps the network pinpoint the diffuse manifold by providing two more gradient terms. We also rendered a synthetic dataset designed to help the network generalize well. We show that our model performs well across various synthetic and real images and outperforms the state-of-the-art in consistency.
Learning More Universal Representations for Transfer-Learning
Sep 03, 2018

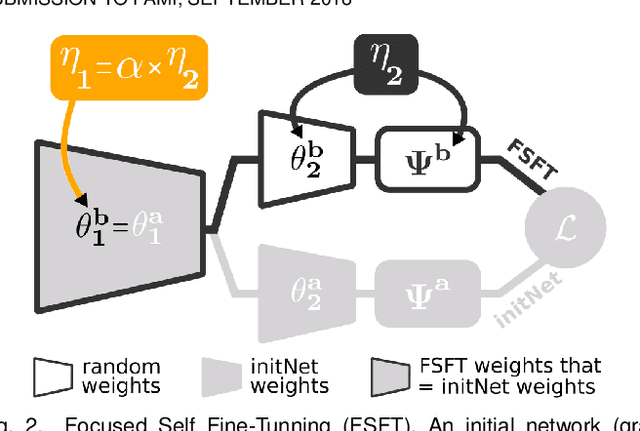

A representation is supposed universal if it encodes any element of the visual world (e.g., objects, scenes) in any configuration (e.g., scale, context). While not expecting pure universal representations, the goal in the literature is to improve the universality level, starting from a representation with a certain level. To do so, the state-of-the-art consists in learning CNN-based representations on a diversified training problem (e.g., ImageNet modified by adding annotated data). While it effectively increases universality, such approach still requires a large amount of efforts to satisfy the needs in annotated data. In this work, we propose two methods to improve universality, but pay special attention to limit the need of annotated data. We also propose a unified framework of the methods based on the diversifying of the training problem. Finally, to better match Atkinson's cognitive study about universal human representations, we proposed to rely on the transfer-learning scheme as well as a new metric to evaluate universality. This latter, aims us to demonstrates the interest of our methods on 10 target-problems, relating to the classification task and a variety of visual domains.