 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multi-class Adversarial Specularity Removal
Apr 04, 2019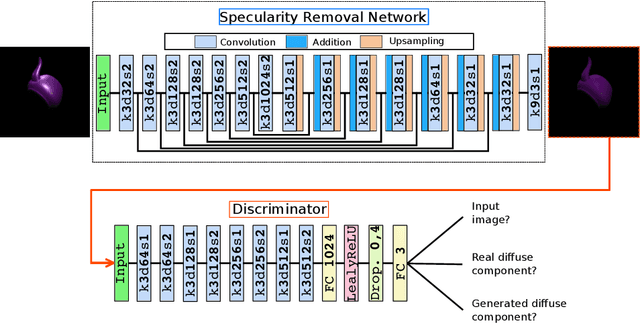

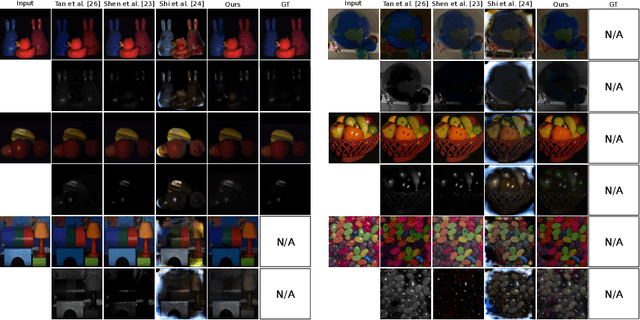
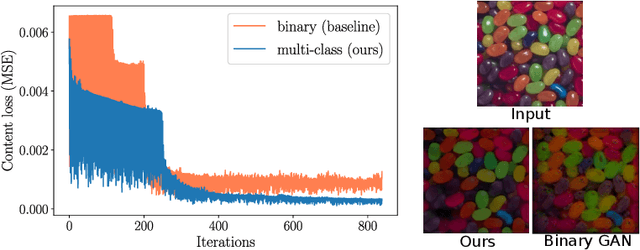
We propose a novel learning approach, in the form of a fully-convolutional neural network (CNN), which automatically and consistently removes specular highlights from a single image by generating its diffuse component. To train the generative network, we define an adversarial loss on a discriminative network as in the GAN framework and combined it with a content loss. In contrast to existing GAN approaches, we implemented the discriminator to be a multi-class classifier instead of a binary one, to find more constraining features. This helps the network pinpoint the diffuse manifold by providing two more gradient terms. We also rendered a synthetic dataset designed to help the network generalize well. We show that our model performs well across various synthetic and real images and outperforms the state-of-the-art in consistency.
Generative Collaborative Networks for Single Image Super-Resolution
Mar 12, 2019

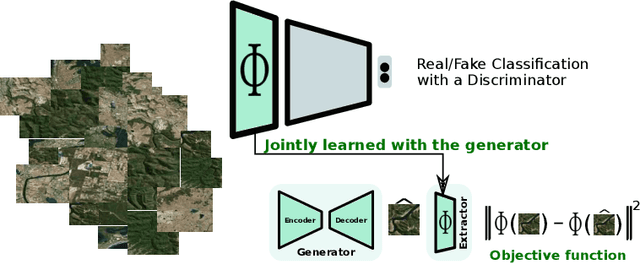

A common issue of deep neural networks-based methods for the problem of Single Image Super-Resolution (SISR), is the recovery of finer texture details when super-resolving at large upscaling factors. This issue is particularly related to the choice of the objective loss function. In particular, recent works proposed the use of a VGG loss which consists in minimizing the error between the generated high resolution images and ground-truth in the feature space of a Convolutional Neural Network (VGG19), pre-trained on the very "large" ImageNet dataset. When considering the problem of super-resolving images with a distribution "far" from the ImageNet images distribution (\textit{e.g.,} satellite images), their proposed \textit{fixed} VGG loss is no longer relevant. In this paper, we present a general framework named \textit{Generative Collaborative Networks} (GCN), where the idea consists in optimizing the \textit{generator} (the mapping of interest) in the feature space of a \textit{features extractor} network. The two networks (generator and extractor) are \textit{collaborative} in the sense that the latter "helps" the former, by constructing discriminative and relevant features (not necessarily \textit{fixed} and possibly learned \textit{mutually} with the generator). We evaluate the GCN framework in the context of SISR, and we show that it results in a method that is adapted to super-resolution domains that are "far" from the ImageNet domain.