 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEExAI: Benchmark to Evaluate Explainable AI
Jul 29, 2024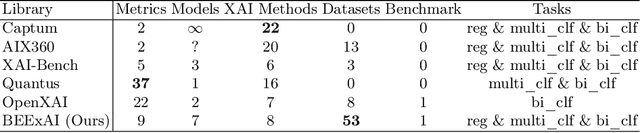
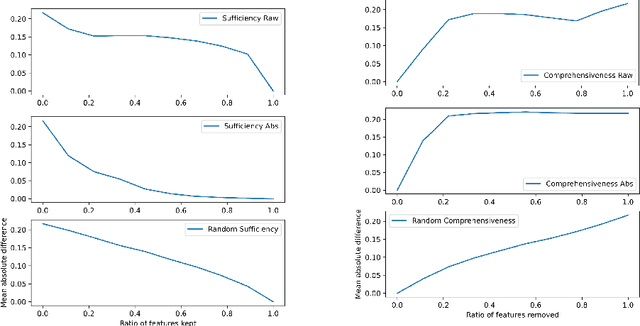
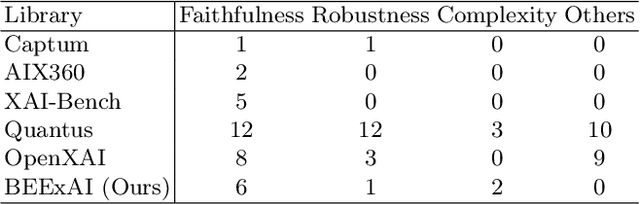
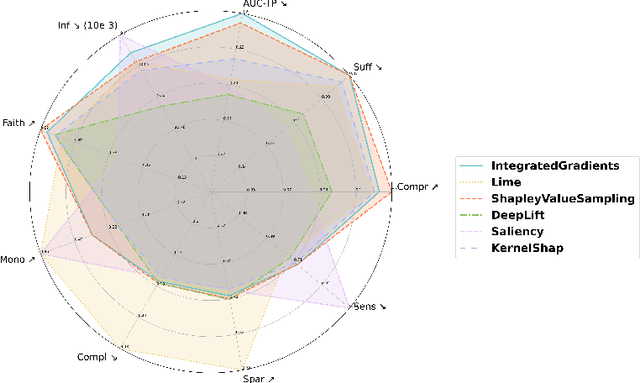
Recent research in explainability has given rise to numerous post-hoc attribution methods aimed at enhancing our comprehension of the outputs of black-box machine learning models. However, evaluating the quality of explanations lacks a cohesive approach and a consensus on the methodology for deriving quantitative metrics that gauge the efficacy of explainability post-hoc attribution methods. Furthermore, with the development of increasingly complex deep learning models for diverse data applications, the need for a reliable way of measuring the quality and correctness of explanations is becoming critical. We address this by proposing BEExAI, a benchmark tool that allows large-scale comparison of different post-hoc XAI methods, employing a set of selected evaluation metrics.
Neural Supervised Domain Adaptation by Augmenting Pre-trained Models with Random Units
Jun 09, 2021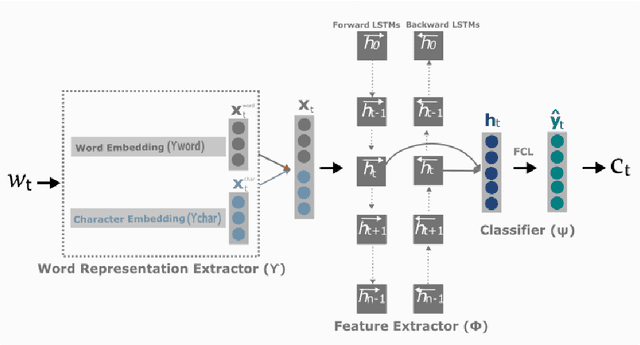
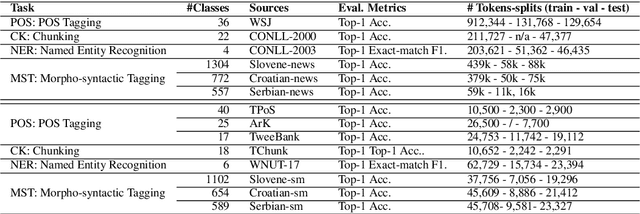
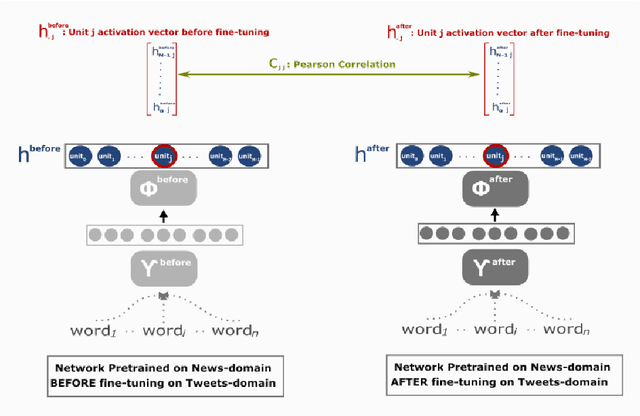

Neural Transfer Learning (TL) is becoming ubiquitous in Natural Language Processing (NLP), thanks to its high performance on many tasks, especially in low-resourced scenarios. Notably, TL is widely used for neural domain adaptation to transfer valuable knowledge from high-resource to low-resource domains. In the standard fine-tuning scheme of TL, a model is initially pre-trained on a source domain and subsequently fine-tuned on a target domain and, therefore, source and target domains are trained using the same architecture. In this paper, we show through interpretation methods that such scheme, despite its efficiency, is suffering from a main limitation. Indeed, although capable of adapting to new domains, pre-trained neurons struggle with learning certain patterns that are specific to the target domain. Moreover, we shed light on the hidden negative transfer occurring despite the high relatedness between source and target domains, which may mitigate the final gain brought by transfer learning. To address these problems, we propose to augment the pre-trained model with normalised, weighted and randomly initialised units that foster a better adaptation while maintaining the valuable source knowledge. We show that our approach exhibits significant improvements to the standard fine-tuning scheme for neural domain adaptation from the news domain to the social media domain on four NLP tasks: part-of-speech tagging, chunking, named entity recognition and morphosyntactic tagging.
Joint Learning of Pre-Trained and Random Units for Domain Adaptation in Part-of-Speech Tagging
Apr 07, 2019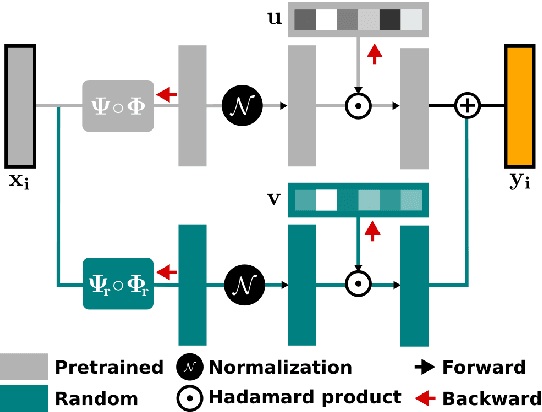
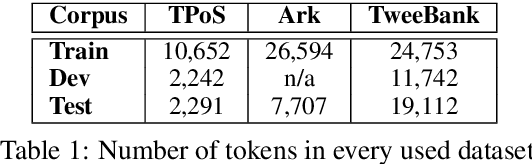
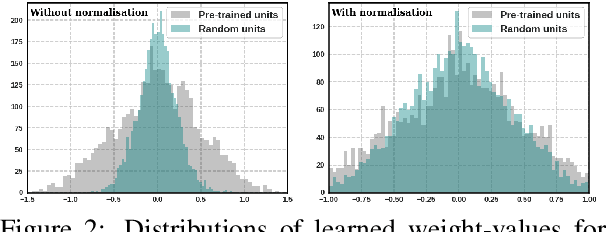
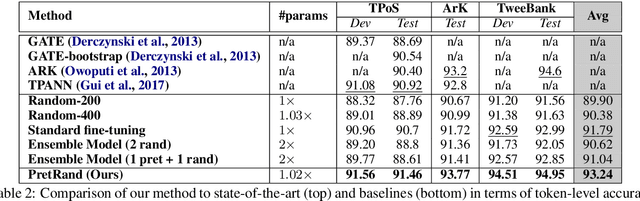
Fine-tuning neural networks is widely used to transfer valuable knowledge from high-resource to low-resource domains. In a standard fine-tuning scheme, source and target problems are trained using the same architecture. Although capable of adapting to new domains, pre-trained units struggle with learning uncommon target-specific patterns. In this paper, we propose to augment the target-network with normalised, weighted and randomly initialised units that beget a better adaptation while maintaining the valuable source knowledge. Our experiments on POS tagging of social media texts (Tweets domain) demonstrate that our method achieves state-of-the-art performances on 3 commonly used datasets.