 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEExAI: Benchmark to Evaluate Explainable AI
Jul 29, 2024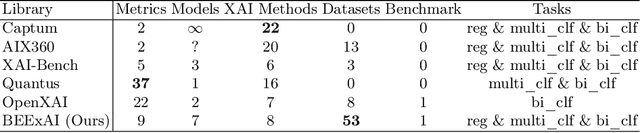
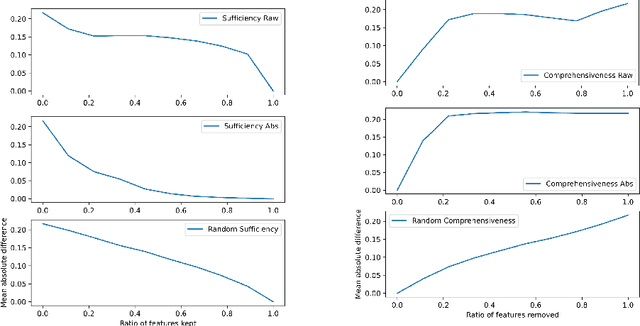
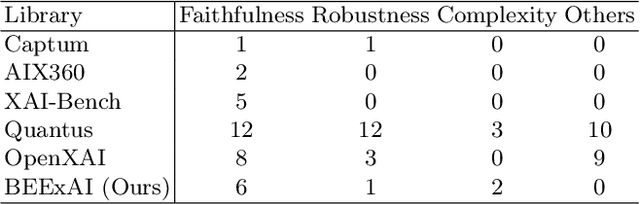
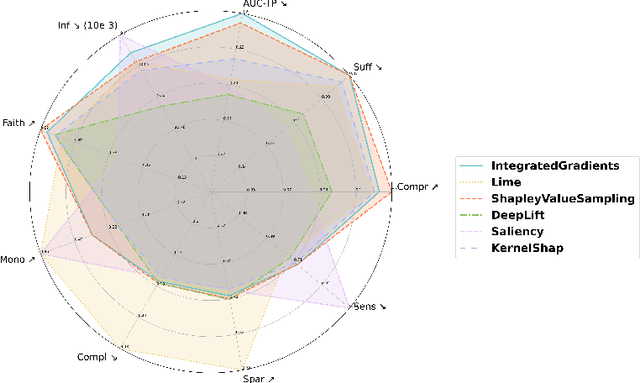
Recent research in explainability has given rise to numerous post-hoc attribution methods aimed at enhancing our comprehension of the outputs of black-box machine learning models. However, evaluating the quality of explanations lacks a cohesive approach and a consensus on the methodology for deriving quantitative metrics that gauge the efficacy of explainability post-hoc attribution methods. Furthermore, with the development of increasingly complex deep learning models for diverse data applications, the need for a reliable way of measuring the quality and correctness of explanations is becoming critical. We address this by proposing BEExAI, a benchmark tool that allows large-scale comparison of different post-hoc XAI methods, employing a set of selected evaluation metrics.
Learning Anonymized Representations with Adversarial Neural Networks
Feb 26, 2018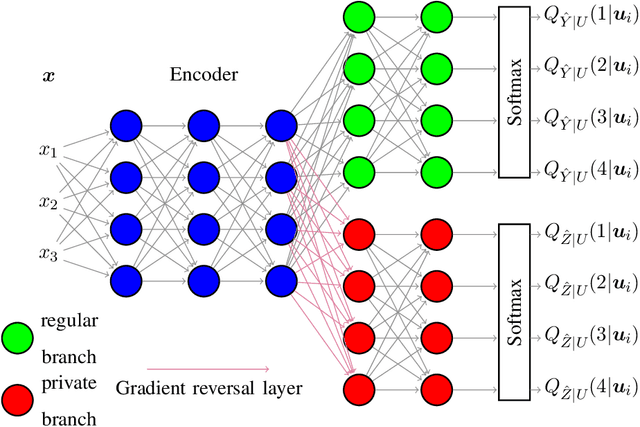

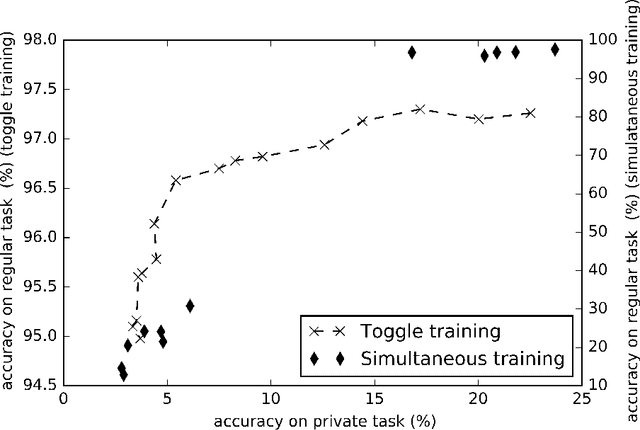
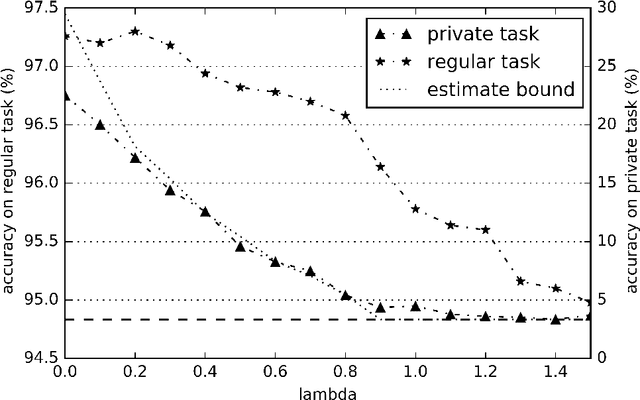
Statistical methods protecting sensitive information or the identity of the data owner have become critical to ensure privacy of individuals as well as of organizations. This paper investigates anonymization methods based on representation learning and deep neural networks, and motivated by novel information theoretical bounds. We introduce a novel training objective for simultaneously training a predictor over target variables of interest (the regular labels) while preventing an intermediate representation to be predictive of the private labels. The architecture is based on three sub-networks: one going from input to representation, one from representation to predicted regular labels, and one from representation to predicted private labels. The training procedure aims at learning representations that preserve the relevant part of the information (about regular labels) while dismissing information about the private labels which correspond to the identity of a person. We demonstrate the success of this approach for two distinct classification versus anonymization tasks (handwritten digits and sentiment analysis).