 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombine and Conquer: A Meta-Analysis on Data Shift and Out-of-Distribution Detection
Jun 23, 2024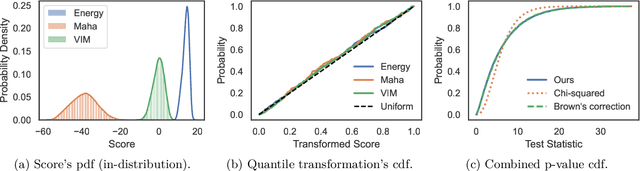
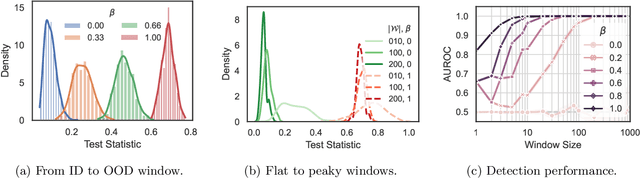
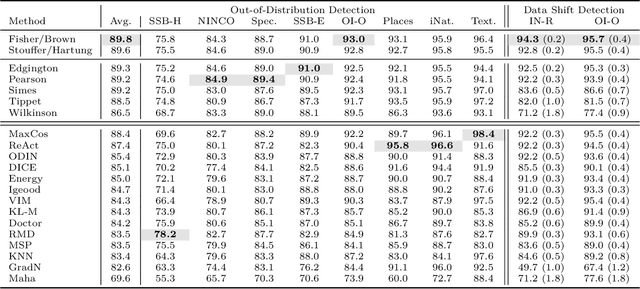
This paper introduces a universal approach to seamlessly combine out-of-distribution (OOD) detection scores. These scores encompass a wide range of techniques that leverage the self-confidence of deep learning models and the anomalous behavior of features in the latent space. Not surprisingly, combining such a varied population using simple statistics proves inadequate. To overcome this challenge, we propose a quantile normalization to map these scores into p-values, effectively framing the problem into a multi-variate hypothesis test. Then, we combine these tests using established meta-analysis tools, resulting in a more effective detector with consolidated decision boundaries. Furthermore, we create a probabilistic interpretable criterion by mapping the final statistics into a distribution with known parameters. Through empirical investigation, we explore different types of shifts, each exerting varying degrees of impact on data. Our results demonstrate that our approach significantly improves overall robustness and performance across diverse OOD detection scenarios. Notably, our framework is easily extensible for future developments in detection scores and stands as the first to combine decision boundaries in this context. The code and artifacts associated with this work are publicly available\footnote{\url{https://github.com/edadaltocg/detectors}}.
Igeood: An Information Geometry Approach to Out-of-Distribution Detection
Mar 15, 2022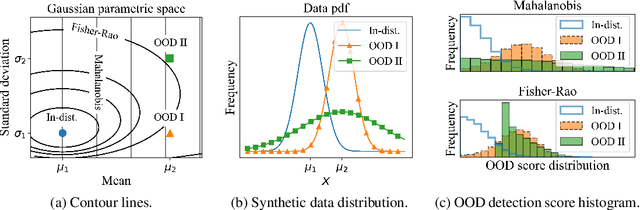

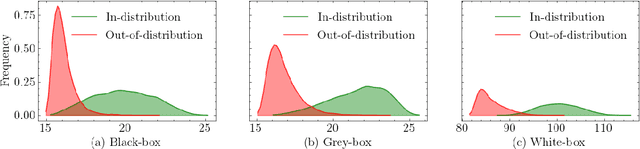
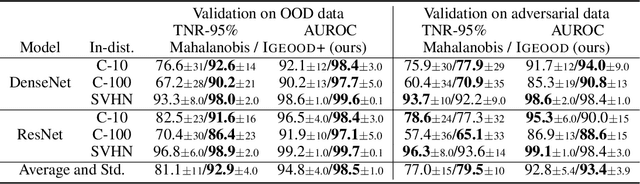
Reliable out-of-distribution (OOD) detection is fundamental to implementing safer modern machine learning (ML) systems. In this paper, we introduce Igeood, an effective method for detecting OOD samples. Igeood applies to any pre-trained neural network, works under various degrees of access to the ML model, does not require OOD samples or assumptions on the OOD data but can also benefit (if available) from OOD samples. By building on the geodesic (Fisher-Rao) distance between the underlying data distributions, our discriminator can combine confidence scores from the logits outputs and the learned features of a deep neural network. Empirically, we show that Igeood outperforms competing state-of-the-art methods on a variety of network architectures and datasets.
Lossless Coding of Point Cloud Geometry using a Deep Generative Model
Jul 01, 2021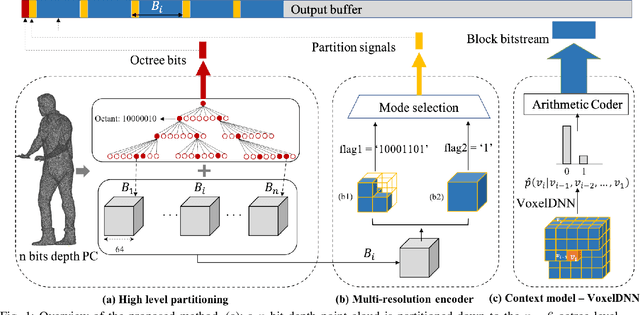

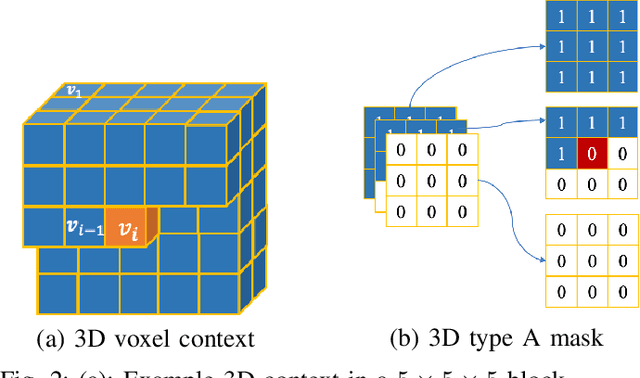
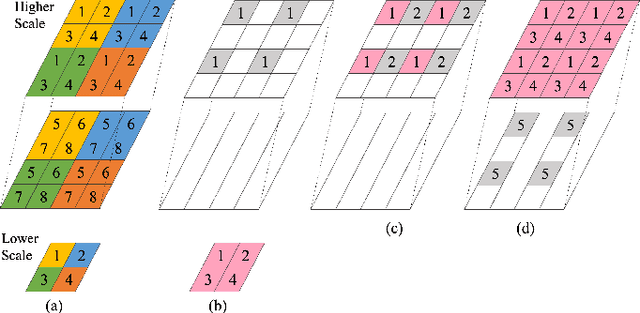
This paper proposes a lossless point cloud (PC) geometry compression method that uses neural networks to estimate the probability distribution of voxel occupancy. First, to take into account the PC sparsity, our method adaptively partitions a point cloud into multiple voxel block sizes. This partitioning is signalled via an octree. Second, we employ a deep auto-regressive generative model to estimate the occupancy probability of each voxel given the previously encoded ones. We then employ the estimated probabilities to code efficiently a block using a context-based arithmetic coder. Our context has variable size and can expand beyond the current block to learn more accurate probabilities. We also consider using data augmentation techniques to increase the generalization capability of the learned probability models, in particular in the presence of noise and lower-density point clouds. Experimental evaluation, performed on a variety of point clouds from four different datasets and with diverse characteristics, demonstrates that our method reduces significantly (by up to 30%) the rate for lossless coding compared to the state-of-the-art MPEG codec.
Multiscale deep context modeling for lossless point cloud geometry compression
Apr 20, 2021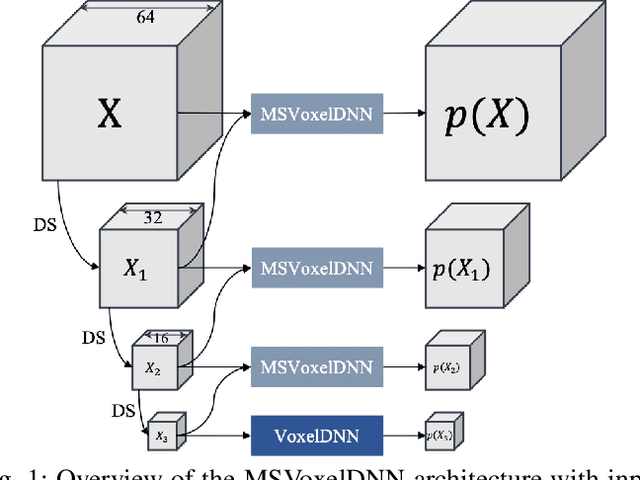
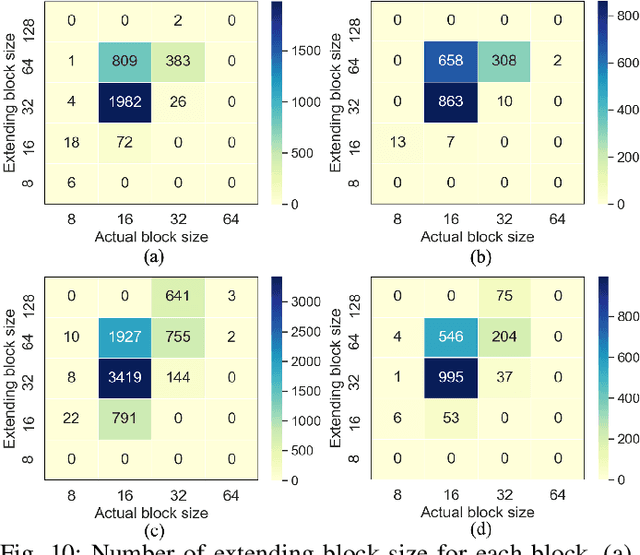
We propose a practical deep generative approach for lossless point cloud geometry compression, called MSVoxelDNN, and show that it significantly reduces the rate compared to the MPEG G-PCC codec. Our previous work based on autoregressive models (VoxelDNN) has a fast training phase, however, inference is slow as the occupancy probabilities are predicted sequentially, voxel by voxel. In this work, we employ a multiscale architecture which models voxel occupancy in coarse-to-fine order. At each scale, MSVoxelDNN divides voxels into eight conditionally independent groups, thus requiring a single network evaluation per group instead of one per voxel. We evaluate the performance of MSVoxelDNN on a set of point clouds from Microsoft Voxelized Upper Bodies (MVUB) and MPEG, showing that the current method speeds up encoding/decoding times significantly compared to the previous VoxelDNN, while having average rate saving over G-PCC of 17.5%. The implementation is available at https://github.com/Weafre/MSVoxelDNN.
Learning-based lossless compression of 3D point cloud geometry
Nov 30, 2020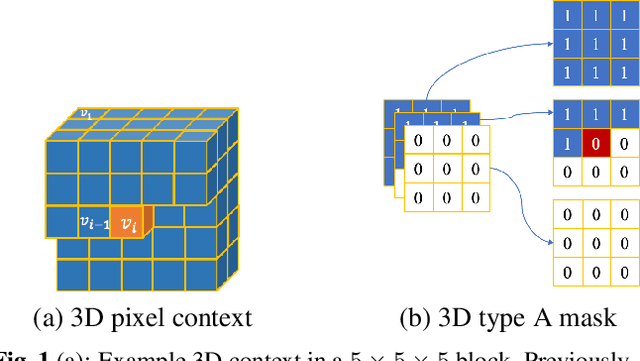
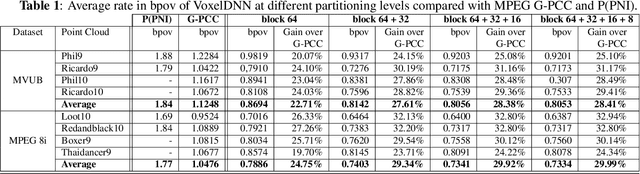
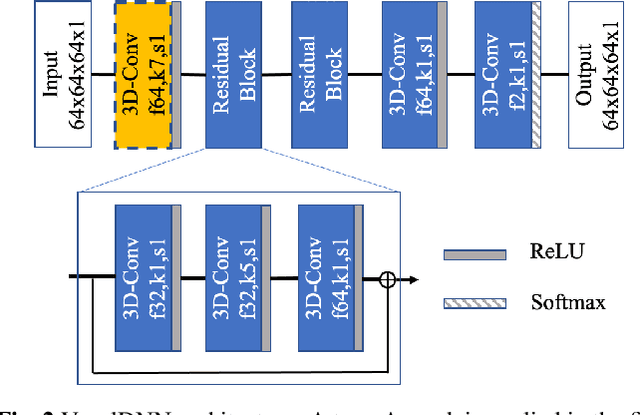
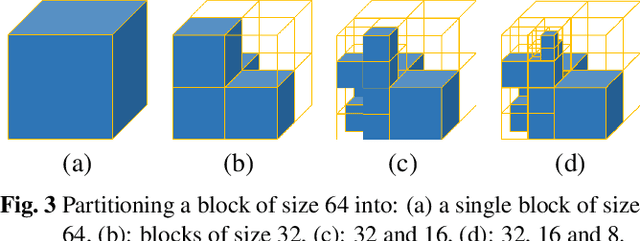
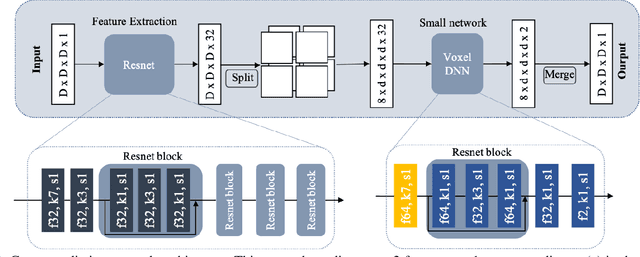
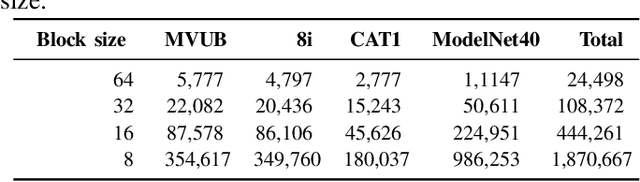
This paper presents a learning-based, lossless compression method for static point cloud geometry, based on context-adaptive arithmetic coding. Unlike most existing methods working in the octree domain, our encoder operates in a hybrid mode, mixing octree and voxel-based coding. We adaptively partition the point cloud into multi-resolution voxel blocks according to the point cloud structure and use octree to signal the partitioning. On the one hand, octree representation can eliminate the sparsity in the point cloud. On the other hand, in the voxel domain, convolutions can be naturally expressed, and geometric information (i.e., planes, surfaces, etc.) is explicitly processed by a neural network. Our context model benefits from these properties and learns a probability distribution of the voxels using a deep convolutional neural network with masked filters, called VoxelDNN. Experiments show that our method outperforms the state-of-the-art MPEG G-PCC standard with average rate savings of 28% on a diverse set of point clouds from the Microsoft Voxelized Upper Bodies (MVUB) and MPEG.
Learning Anonymized Representations with Adversarial Neural Networks
Feb 26, 2018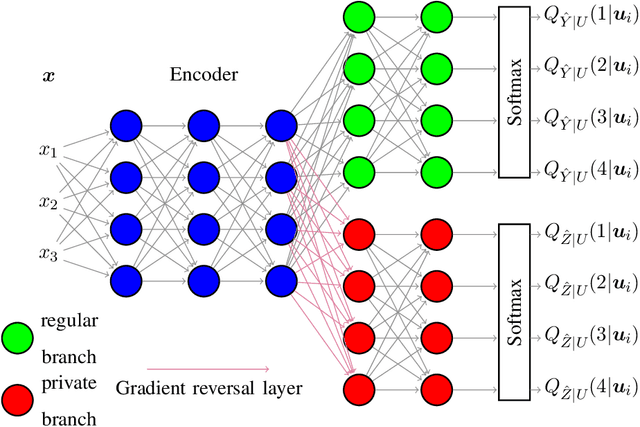

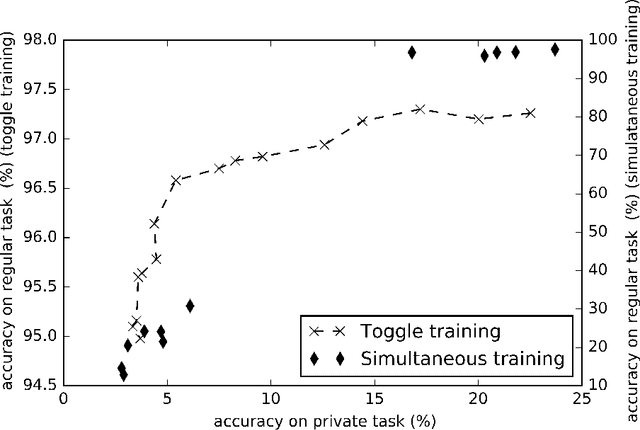
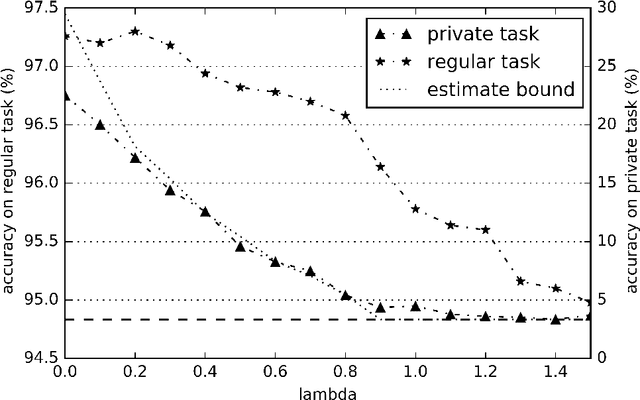
Statistical methods protecting sensitive information or the identity of the data owner have become critical to ensure privacy of individuals as well as of organizations. This paper investigates anonymization methods based on representation learning and deep neural networks, and motivated by novel information theoretical bounds. We introduce a novel training objective for simultaneously training a predictor over target variables of interest (the regular labels) while preventing an intermediate representation to be predictive of the private labels. The architecture is based on three sub-networks: one going from input to representation, one from representation to predicted regular labels, and one from representation to predicted private labels. The training procedure aims at learning representations that preserve the relevant part of the information (about regular labels) while dismissing information about the private labels which correspond to the identity of a person. We demonstrate the success of this approach for two distinct classification versus anonymization tasks (handwritten digits and sentiment analysis).