 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEExAI: Benchmark to Evaluate Explainable AI
Paper and Code
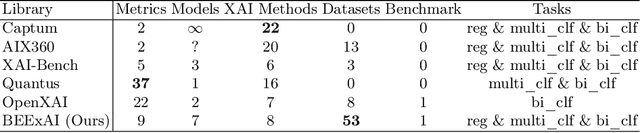
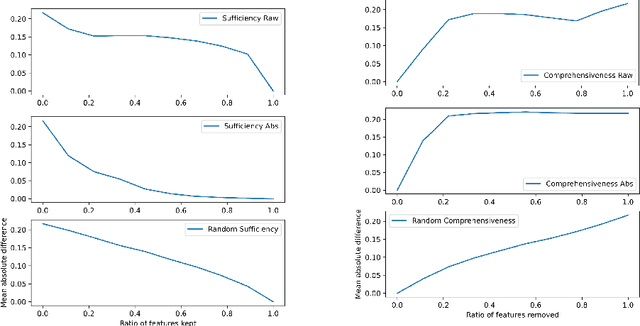
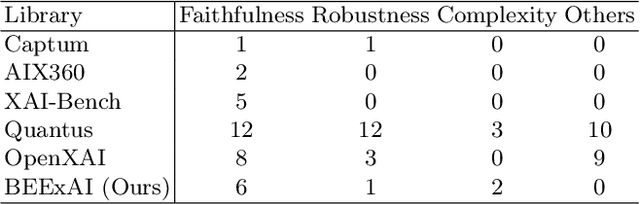
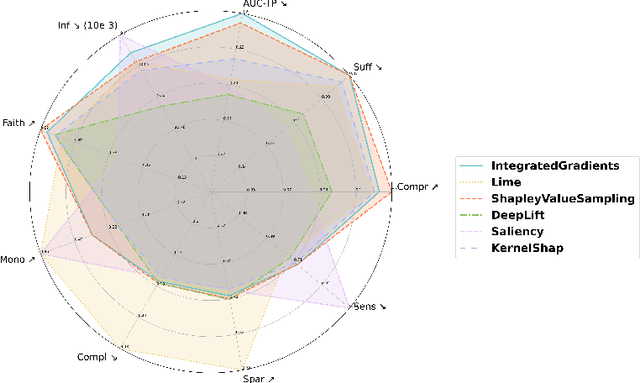
Recent research in explainability has given rise to numerous post-hoc attribution methods aimed at enhancing our comprehension of the outputs of black-box machine learning models. However, evaluating the quality of explanations lacks a cohesive approach and a consensus on the methodology for deriving quantitative metrics that gauge the efficacy of explainability post-hoc attribution methods. Furthermore, with the development of increasingly complex deep learning models for diverse data applications, the need for a reliable way of measuring the quality and correctness of explanations is becoming critical. We address this by proposing BEExAI, a benchmark tool that allows large-scale comparison of different post-hoc XAI methods, employing a set of selected evaluation metrics.