 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal and Efficient Binary Questioning for Human-in-the-Loop Annotation
Jul 04, 2023Even though data annotation is extremely important for interpretability, research and development of artificial intelligence solutions, most research efforts such as active learning or few-shot learning focus on the sample efficiency problem. This paper studies the neglected complementary problem of getting annotated data given a predictor. For the simple binary classification setting, we present the spectrum ranging from optimal general solutions to practical efficient methods. The problem is framed as the full annotation of a binary classification dataset with the minimal number of yes/no questions when a predictor is available. For the case of general binary questions the solution is found in coding theory, where the optimal questioning strategy is given by the Huffman encoding of the possible labelings. However, this approach is computationally intractable even for small dataset sizes. We propose an alternative practical solution based on several heuristics and lookahead minimization of proxy cost functions. The proposed solution is analysed, compared with optimal solutions and evaluated on several synthetic and real-world datasets. On these datasets, the method allows a significant improvement ($23-86\%$) in annotation efficiency.
Improving Pixel-Level Contrastive Learning by Leveraging Exogenous Depth Information
Nov 18, 2022Self-supervised representation learning based on Contrastive Learning (CL) has been the subject of much attention in recent years. This is due to the excellent results obtained on a variety of subsequent tasks (in particular classification), without requiring a large amount of labeled samples. However, most reference CL algorithms (such as SimCLR and MoCo, but also BYOL and Barlow Twins) are not adapted to pixel-level downstream tasks. One existing solution known as PixPro proposes a pixel-level approach that is based on filtering of pairs of positive/negative image crops of the same image using the distance between the crops in the whole image. We argue that this idea can be further enhanced by incorporating semantic information provided by exogenous data as an additional selection filter, which can be used (at training time) to improve the selection of the pixel-level positive/negative samples. In this paper we will focus on the depth information, which can be obtained by using a depth estimation network or measured from available data (stereovision, parallax motion, LiDAR, etc.). Scene depth can provide meaningful cues to distinguish pixels belonging to different objects based on their depth. We show that using this exogenous information in the contrastive loss leads to improved results and that the learned representations better follow the shapes of objects. In addition, we introduce a multi-scale loss that alleviates the issue of finding the training parameters adapted to different object sizes. We demonstrate the effectiveness of our ideas on the Breakout Segmentation on Borehole Images where we achieve an improvement of 1.9\% over PixPro and nearly 5\% over the supervised baseline. We further validate our technique on the indoor scene segmentation tasks with ScanNet and outdoor scenes with CityScapes ( 1.6\% and 1.1\% improvement over PixPro respectively).
Where is the Fake? Patch-Wise Supervised GANs for Texture Inpainting
Nov 06, 2019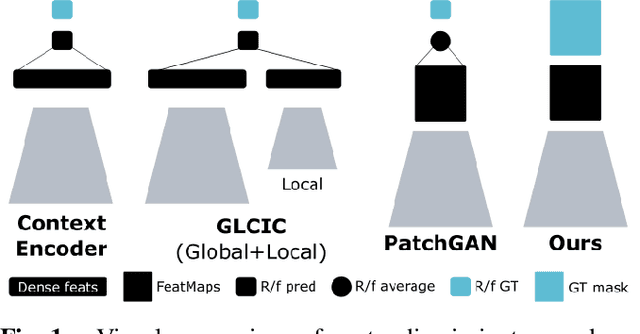
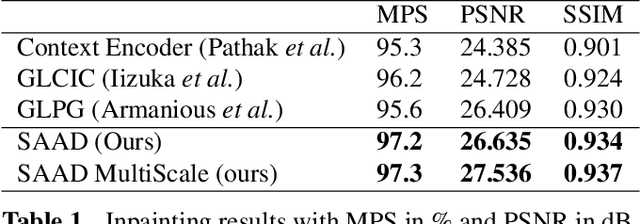

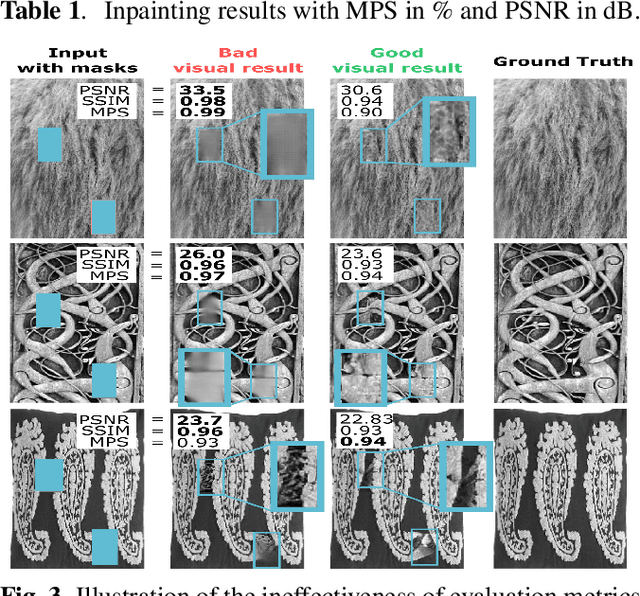
We tackle the problem of texture inpainting where the input images are textures with missing values along with masks that indicate the zones that should be generated. Many works have been done in image inpainting with the aim to achieve global and local consistency. But these works still suffer from limitations when dealing with textures. In fact, the local information in the image to be completed needs to be used in order to achieve local continuities and visually realistic texture inpainting. For this, we propose a new segmentor discriminator that performs a patch-wise real/fake classification and is supervised by input masks. During training, it aims to locate the fake and thus backpropagates consistent signal to the generator. We tested our approach on the publicly available DTD dataset and showed that it achieves state-of-the-art performances and better deals with local consistency than existing methods.