 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Limits in Vehicle Re-Identification
Jun 01, 2026Vehicle re-identification focuses on retrieving images of the same vehicle from a gallery given a query image. Upon closer inspection of commonly used datasets, we observe that vehicles with few visual differences-e.g., the same make, model, and color-appear in both the training and test sets. As a result, methods that effectively memorize the training data tend to perform well on these test sets but struggle to generalize to other datasets. In this paper, we address this issue by proposing a novel evaluation approach that more effectively measures generalization capability to unseen vehicle types. To further study generalization performance, we also propose splitting the evaluation based on view, allowing us to differentiate the effect of viewpoint robustness from that of same-view re-identification. Our findings reveal that most state-of-the-art methods struggle with unseen vehicle types, and that their robustness to viewpoint changes and attention to detail are limited to vehicle types seen during training.
Fast, nonlocal and neural: a lightweight high quality solution to image denoising
Mar 06, 2024



With the widespread application of convolutional neural networks (CNNs), the traditional model based denoising algorithms are now outperformed. However, CNNs face two problems. First, they are computationally demanding, which makes their deployment especially difficult for mobile terminals. Second, experimental evidence shows that CNNs often over-smooth regular textures present in images, in contrast to traditional non-local models. In this letter, we propose a solution to both issues by combining a nonlocal algorithm with a lightweight residual CNN. This solution gives full latitude to the advantages of both models. We apply this framework to two GPU implementations of classic nonlocal algorithms (NLM and BM3D) and observe a substantial gain in both cases, performing better than the state-of-the-art with low computational requirements. Our solution is between 10 and 20 times faster than CNNs with equivalent performance and attains higher PSNR. In addition the final method shows a notable gain on images containing complex textures like the ones of the MIT Moire dataset.
* 5 pages. This paper was accepted by IEEE Signal Processing Letters on July 1, 2021
On the Importance of Large Objects in CNN Based Object Detection Algorithms
Nov 20, 2023Object detection models, a prominent class of machine learning algorithms, aim to identify and precisely locate objects in images or videos. However, this task might yield uneven performances sometimes caused by the objects sizes and the quality of the images and labels used for training. In this paper, we highlight the importance of large objects in learning features that are critical for all sizes. Given these findings, we propose to introduce a weighting term into the training loss. This term is a function of the object area size. We show that giving more weight to large objects leads to improved detection scores across all object sizes and so an overall improvement in Object Detectors performances (+2 p.p. of mAP on small objects, +2 p.p. on medium and +4 p.p. on large on COCO val 2017 with InternImage-T). Additional experiments and ablation studies with different models and on a different dataset further confirm the robustness of our findings.
L1BSR: Exploiting Detector Overlap for Self-Supervised Single-Image Super-Resolution of Sentinel-2 L1B Imagery
Apr 17, 2023



High-resolution satellite imagery is a key element for many Earth monitoring applications. Satellites such as Sentinel-2 feature characteristics that are favorable for super-resolution algorithms such as aliasing and band-misalignment. Unfortunately the lack of reliable high-resolution (HR) ground truth limits the application of deep learning methods to this task. In this work we propose L1BSR, a deep learning-based method for single-image super-resolution and band alignment of Sentinel-2 L1B 10m bands. The method is trained with self-supervision directly on real L1B data by leveraging overlapping areas in L1B images produced by adjacent CMOS detectors, thus not requiring HR ground truth. Our self-supervised loss is designed to enforce the super-resolved output image to have all the bands correctly aligned. This is achieved via a novel cross-spectral registration network (CSR) which computes an optical flow between images of different spectral bands. The CSR network is also trained with self-supervision using an Anchor-Consistency loss, which we also introduce in this work. We demonstrate the performance of the proposed approach on synthetic and real L1B data, where we show that it obtains comparable results to supervised methods.
Improving Pixel-Level Contrastive Learning by Leveraging Exogenous Depth Information
Nov 18, 2022Self-supervised representation learning based on Contrastive Learning (CL) has been the subject of much attention in recent years. This is due to the excellent results obtained on a variety of subsequent tasks (in particular classification), without requiring a large amount of labeled samples. However, most reference CL algorithms (such as SimCLR and MoCo, but also BYOL and Barlow Twins) are not adapted to pixel-level downstream tasks. One existing solution known as PixPro proposes a pixel-level approach that is based on filtering of pairs of positive/negative image crops of the same image using the distance between the crops in the whole image. We argue that this idea can be further enhanced by incorporating semantic information provided by exogenous data as an additional selection filter, which can be used (at training time) to improve the selection of the pixel-level positive/negative samples. In this paper we will focus on the depth information, which can be obtained by using a depth estimation network or measured from available data (stereovision, parallax motion, LiDAR, etc.). Scene depth can provide meaningful cues to distinguish pixels belonging to different objects based on their depth. We show that using this exogenous information in the contrastive loss leads to improved results and that the learned representations better follow the shapes of objects. In addition, we introduce a multi-scale loss that alleviates the issue of finding the training parameters adapted to different object sizes. We demonstrate the effectiveness of our ideas on the Breakout Segmentation on Borehole Images where we achieve an improvement of 1.9\% over PixPro and nearly 5\% over the supervised baseline. We further validate our technique on the indoor scene segmentation tasks with ScanNet and outdoor scenes with CityScapes ( 1.6\% and 1.1\% improvement over PixPro respectively).
Self-Supervised Super-Resolution for Multi-Exposure Push-Frame Satellites
May 04, 2022
Modern Earth observation satellites capture multi-exposure bursts of push-frame images that can be super-resolved via computational means. In this work, we propose a super-resolution method for such multi-exposure sequences, a problem that has received very little attention in the literature. The proposed method can handle the signal-dependent noise in the inputs, process sequences of any length, and be robust to inaccuracies in the exposure times. Furthermore, it can be trained end-to-end with self-supervision, without requiring ground truth high resolution frames, which makes it especially suited to handle real data. Central to our method are three key contributions: i) a base-detail decomposition for handling errors in the exposure times, ii) a noise-level-aware feature encoding for improved fusion of frames with varying signal-to-noise ratio and iii) a permutation invariant fusion strategy by temporal pooling operators. We evaluate the proposed method on synthetic and real data and show that it outperforms by a significant margin existing single-exposure approaches that we adapted to the multi-exposure case.
Proba-V-ref: Repurposing the Proba-V challenge for reference-aware super resolution
Jan 26, 2021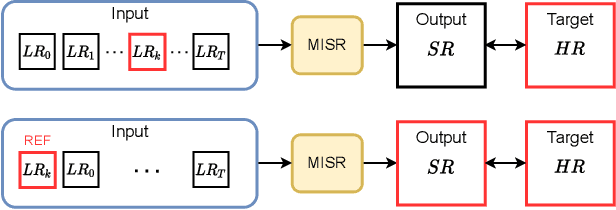

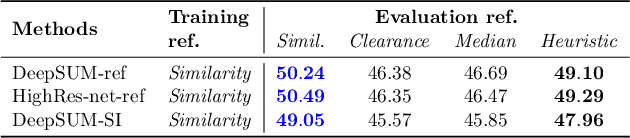

The PROBA-V Super-Resolution challenge distributes real low-resolution image series and corresponding high-resolution targets to advance research on Multi-Image Super Resolution (MISR) for satellite images. However, in the PROBA-V dataset the low-resolution image corresponding to the high-resolution target is not identified. We argue that in doing so, the challenge ranks the proposed methods not only by their MISR performance, but mainly by the heuristics used to guess which image in the series is the most similar to the high-resolution target. We demonstrate this by improving the performance obtained by the two winners of the challenge only by using a different reference image, which we compute following a simple heuristic. Based on this, we propose PROBA-V-REF a variant of the PROBA-V dataset, in which the reference image in the low-resolution series is provided, and show that the ranking between the methods changes in this setting. This is relevant to many practical use cases of MISR where the goal is to super-resolve a specific image of the series, i.e. the reference is known. The proposed PROBA-V-REF should better reflect the performance of the different methods for this reference-aware MISR problem.
Self-Supervised training for blind multi-frame video denoising
May 05, 2020
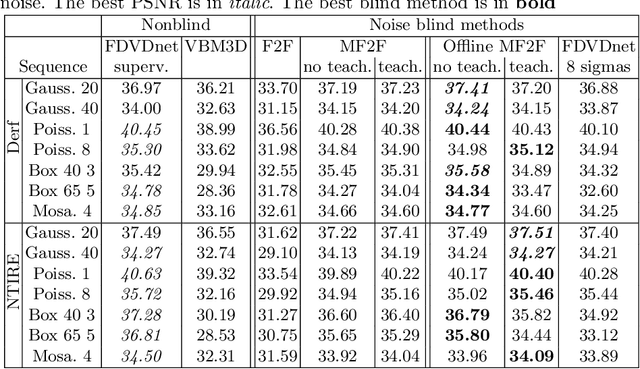
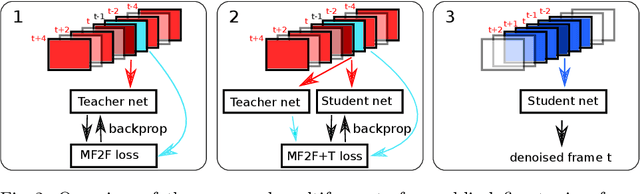
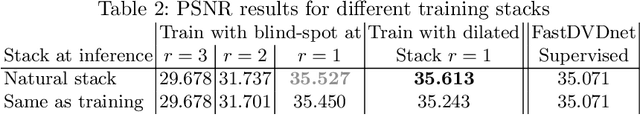
We propose a self-supervised approach for training multi-frame video denoising networks. These networks predict frame t from a window of frames around t. Our self-supervised approach benefits from the video temporal consistency by penalizing a loss between the predicted frame t and a neighboring target frame, which are aligned using an optical flow. We use the proposed strategy for online internal learning, where a pre-trained network is fine-tuned to denoise a new unknown noise type from a single video. After a few frames, the proposed fine-tuning reaches and sometimes surpasses the performance of a state-of-the-art network trained with supervision. In addition, for a wide range of noise types, it can be applied blindly without knowing the noise distribution. We demonstrate this by showing results on blind denoising of different synthetic and realistic noises.
Joint demosaicing and denoising by overfitting of bursts of raw images
May 13, 2019
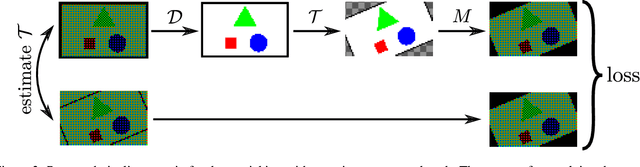


Demosaicking and denoising are the first steps of any camera image processing pipeline and are key for obtaining high quality RGB images. A promising current research trend aims at solving these two problems jointly using convolutional neural networks. Due to the unavailability of ground truth data these networks cannot be currently trained using real RAW images. Instead, they resort to simulated data. In this paper we present a method to learn demosacking directly from mosaicked images, without requiring ground truth RGB data. We apply this to learn joint demosaicking and denoising only from RAW images, thus enabling the use of real data. In addition we show that for this application overfitting a network to a specific burst improves the quality of restoration for both demosaicking and denoising.
Reducing Anomaly Detection in Images to Detection in Noise
Apr 25, 2019


Anomaly detectors address the difficult problem of detecting automatically exceptions in an arbitrary background image. Detection methods have been proposed by the thousands because each problem requires a different background model. By analyzing the existing approaches, we show that the problem can be reduced to detecting anomalies in residual images (extracted from the target image) in which noise and anomalies prevail. Hence, the general and impossible background modeling problem is replaced by simpler noise modeling, and allows the calculation of rigorous thresholds based on the a contrario detection theory. Our approach is therefore unsupervised and works on arbitrary images.
* ICIP 2018