 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting MIMO video restoration networks to low latency constraints
Aug 22, 2024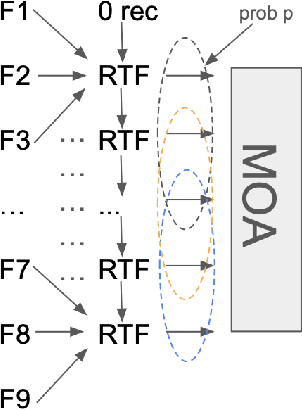


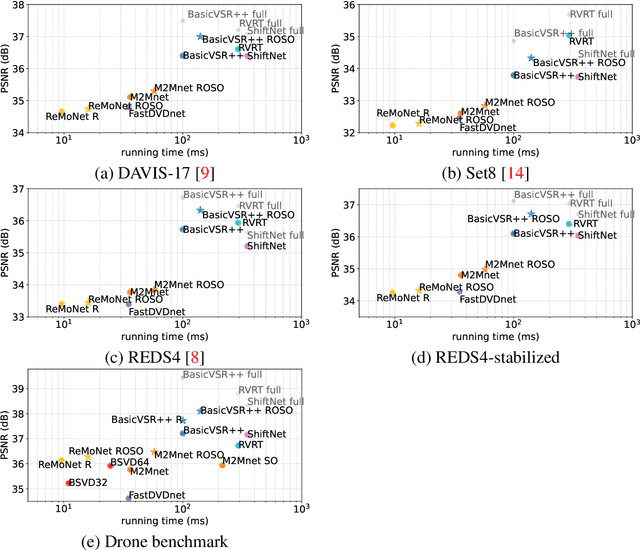
MIMO (multiple input, multiple output) approaches are a recent trend in neural network architectures for video restoration problems, where each network evaluation produces multiple output frames. The video is split into non-overlapping stacks of frames that are processed independently, resulting in a very appealing trade-off between output quality and computational cost. In this work we focus on the low-latency setting by limiting the number of available future frames. We find that MIMO architectures suffer from problems that have received little attention so far, namely (1) the performance drops significantly due to the reduced temporal receptive field, particularly for frames at the borders of the stack, (2) there are strong temporal discontinuities at stack transitions which induce a step-wise motion artifact. We propose two simple solutions to alleviate these problems: recurrence across MIMO stacks to boost the output quality by implicitly increasing the temporal receptive field, and overlapping of the output stacks to smooth the temporal discontinuity at stack transitions. These modifications can be applied to any MIMO architecture. We test them on three state-of-the-art video denoising networks with different computational cost. The proposed contributions result in a new state-of-the-art for low-latency networks, both in terms of reconstruction error and temporal consistency. As an additional contribution, we introduce a new benchmark consisting of drone footage that highlights temporal consistency issues that are not apparent in the standard benchmarks.
SING: A Plug-and-Play DNN Learning Technique
May 25, 2023We propose SING (StabIlized and Normalized Gradient), a plug-and-play technique that improves the stability and generalization of the Adam(W) optimizer. SING is straightforward to implement and has minimal computational overhead, requiring only a layer-wise standardization of the gradients fed to Adam(W) without introducing additional hyper-parameters. We support the effectiveness and practicality of the proposed approach by showing improved results on a wide range of architectures, problems (such as image classification, depth estimation, and natural language processing), and in combination with other optimizers. We provide a theoretical analysis of the convergence of the method, and we show that by virtue of the standardization, SING can escape local minima narrower than a threshold that is inversely proportional to the network's depth.
L1BSR: Exploiting Detector Overlap for Self-Supervised Single-Image Super-Resolution of Sentinel-2 L1B Imagery
Apr 17, 2023



High-resolution satellite imagery is a key element for many Earth monitoring applications. Satellites such as Sentinel-2 feature characteristics that are favorable for super-resolution algorithms such as aliasing and band-misalignment. Unfortunately the lack of reliable high-resolution (HR) ground truth limits the application of deep learning methods to this task. In this work we propose L1BSR, a deep learning-based method for single-image super-resolution and band alignment of Sentinel-2 L1B 10m bands. The method is trained with self-supervision directly on real L1B data by leveraging overlapping areas in L1B images produced by adjacent CMOS detectors, thus not requiring HR ground truth. Our self-supervised loss is designed to enforce the super-resolved output image to have all the bands correctly aligned. This is achieved via a novel cross-spectral registration network (CSR) which computes an optical flow between images of different spectral bands. The CSR network is also trained with self-supervision using an Anchor-Consistency loss, which we also introduce in this work. We demonstrate the performance of the proposed approach on synthetic and real L1B data, where we show that it obtains comparable results to supervised methods.
Can neural networks extrapolate? Discussion of a theorem by Pedro Domingos
Nov 07, 2022Neural networks trained on large datasets by minimizing a loss have become the state-of-the-art approach for resolving data science problems, particularly in computer vision, image processing and natural language processing. In spite of their striking results, our theoretical understanding about how neural networks operate is limited. In particular, what are the interpolation capabilities of trained neural networks? In this paper we discuss a theorem of Domingos stating that "every machine learned by continuous gradient descent is approximately a kernel machine". According to Domingos, this fact leads to conclude that all machines trained on data are mere kernel machines. We first extend Domingo's result in the discrete case and to networks with vector-valued output. We then study its relevance and significance on simple examples. We find that in simple cases, the "neural tangent kernel" arising in Domingos' theorem does provide understanding of the networks' predictions. Furthermore, when the task given to the network grows in complexity, the interpolation capability of the network can be effectively explained by Domingos' theorem, and therefore is limited. We illustrate this fact on a classic perception theory problem: recovering a shape from its boundary.
Self-Supervised Super-Resolution for Multi-Exposure Push-Frame Satellites
May 04, 2022
Modern Earth observation satellites capture multi-exposure bursts of push-frame images that can be super-resolved via computational means. In this work, we propose a super-resolution method for such multi-exposure sequences, a problem that has received very little attention in the literature. The proposed method can handle the signal-dependent noise in the inputs, process sequences of any length, and be robust to inaccuracies in the exposure times. Furthermore, it can be trained end-to-end with self-supervision, without requiring ground truth high resolution frames, which makes it especially suited to handle real data. Central to our method are three key contributions: i) a base-detail decomposition for handling errors in the exposure times, ii) a noise-level-aware feature encoding for improved fusion of frames with varying signal-to-noise ratio and iii) a permutation invariant fusion strategy by temporal pooling operators. We evaluate the proposed method on synthetic and real data and show that it outperforms by a significant margin existing single-exposure approaches that we adapted to the multi-exposure case.
Self-supervision versus synthetic datasets: which is the lesser evil in the context of video denoising?
Apr 25, 2022

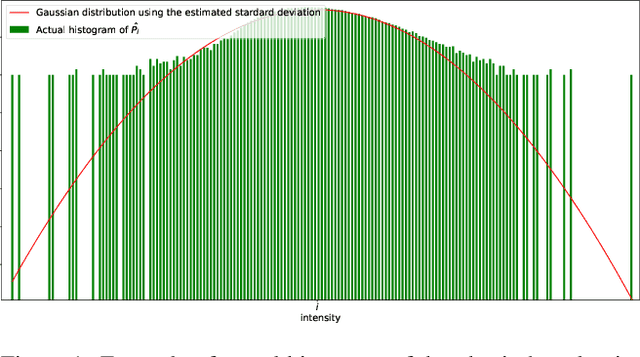

Supervised training has led to state-of-the-art results in image and video denoising. However, its application to real data is limited since it requires large datasets of noisy-clean pairs that are difficult to obtain. For this reason, networks are often trained on realistic synthetic data. More recently, some self-supervised frameworks have been proposed for training such denoising networks directly on the noisy data without requiring ground truth. On synthetic denoising problems supervised training outperforms self-supervised approaches, however in recent years the gap has become narrower, especially for video. In this paper, we propose a study aiming to determine which is the best approach to train denoising networks for real raw videos: supervision on synthetic realistic data or self-supervision on real data. A complete study with quantitative results in case of natural videos with real motion is impossible since no dataset with clean-noisy pairs exists. We address this issue by considering three independent experiments in which we compare the two frameworks. We found that self-supervision on the real data outperforms supervision on synthetic data, and that in normal illumination conditions the drop in performance is due to the synthetic ground truth generation, not the noise model.
Investigating Neural Architectures by Synthetic Dataset Design
Apr 23, 2022


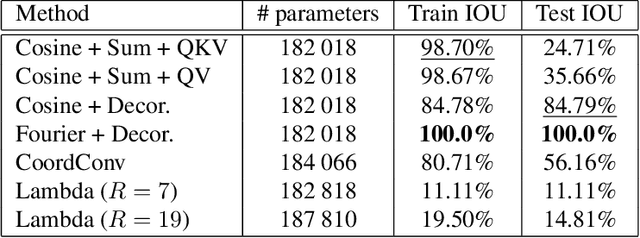
Recent years have seen the emergence of many new neural network structures (architectures and layers). To solve a given task, a network requires a certain set of abilities reflected in its structure. The required abilities depend on each task. There is so far no systematic study of the real capacities of the proposed neural structures. The question of what each structure can and cannot achieve is only partially answered by its performance on common benchmarks. Indeed, natural data contain complex unknown statistical cues. It is therefore impossible to know what cues a given neural structure is taking advantage of in such data. In this work, we sketch a methodology to measure the effect of each structure on a network's ability, by designing ad hoc synthetic datasets. Each dataset is tailored to assess a given ability and is reduced to its simplest form: each input contains exactly the amount of information needed to solve the task. We illustrate our methodology by building three datasets to evaluate each of the three following network properties: a) the ability to link local cues to distant inferences, b) the translation covariance and c) the ability to group pixels with the same characteristics and share information among them. Using a first simplified depth estimation dataset, we pinpoint a serious nonlocal deficit of the U-Net. We then evaluate how to resolve this limitation by embedding its structure with nonlocal layers, which allow computing complex features with long-range dependencies. Using a second dataset, we compare different positional encoding methods and use the results to further improve the U-Net on the depth estimation task. The third introduced dataset serves to demonstrate the need for self-attention-like mechanisms for resolving more realistic depth estimation tasks.
Proba-V-ref: Repurposing the Proba-V challenge for reference-aware super resolution
Jan 26, 2021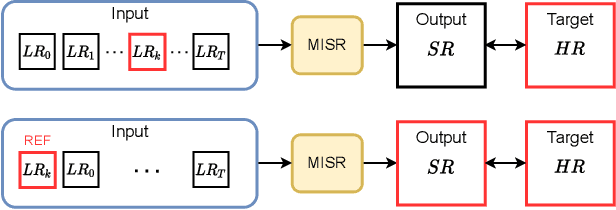

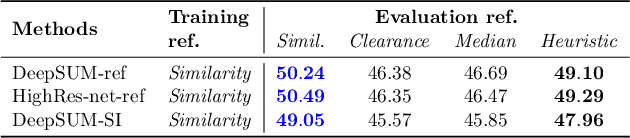

The PROBA-V Super-Resolution challenge distributes real low-resolution image series and corresponding high-resolution targets to advance research on Multi-Image Super Resolution (MISR) for satellite images. However, in the PROBA-V dataset the low-resolution image corresponding to the high-resolution target is not identified. We argue that in doing so, the challenge ranks the proposed methods not only by their MISR performance, but mainly by the heuristics used to guess which image in the series is the most similar to the high-resolution target. We demonstrate this by improving the performance obtained by the two winners of the challenge only by using a different reference image, which we compute following a simple heuristic. Based on this, we propose PROBA-V-REF a variant of the PROBA-V dataset, in which the reference image in the low-resolution series is provided, and show that the ranking between the methods changes in this setting. This is relevant to many practical use cases of MISR where the goal is to super-resolve a specific image of the series, i.e. the reference is known. The proposed PROBA-V-REF should better reflect the performance of the different methods for this reference-aware MISR problem.
Self-Supervised training for blind multi-frame video denoising
May 05, 2020
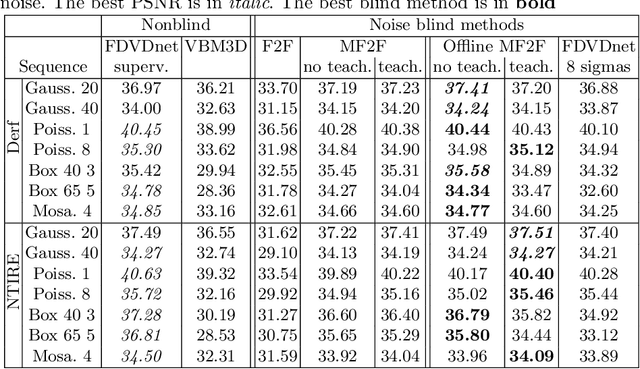
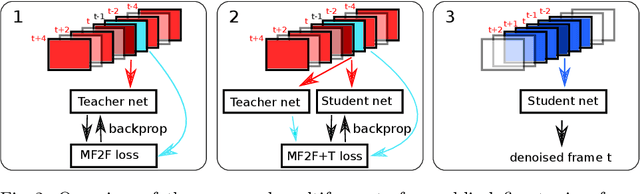
We propose a self-supervised approach for training multi-frame video denoising networks. These networks predict frame t from a window of frames around t. Our self-supervised approach benefits from the video temporal consistency by penalizing a loss between the predicted frame t and a neighboring target frame, which are aligned using an optical flow. We use the proposed strategy for online internal learning, where a pre-trained network is fine-tuned to denoise a new unknown noise type from a single video. After a few frames, the proposed fine-tuning reaches and sometimes surpasses the performance of a state-of-the-art network trained with supervision. In addition, for a wide range of noise types, it can be applied blindly without knowing the noise distribution. We demonstrate this by showing results on blind denoising of different synthetic and realistic noises.
Implementation of the VBM3D Video Denoising Method and Some Variants
Jan 06, 2020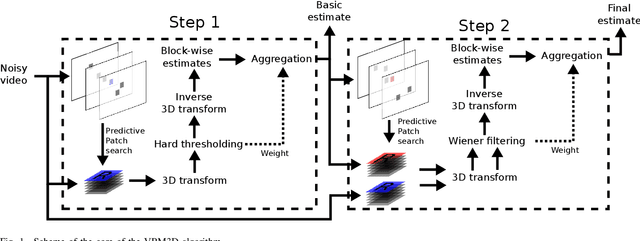
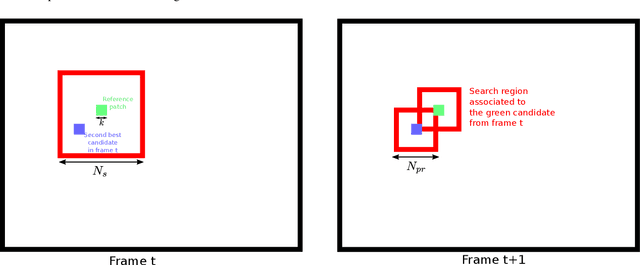


VBM3D is an extension to video of the well known image denoising algorithm BM3D, which takes advantage of the sparse representation of stacks of similar patches in a transform domain. The extension is rather straightforward: the similar 2D patches are taken from a spatio-temporal neighborhood which includes neighboring frames. In spite of its simplicity, the algorithm offers a good trade-off between denoising performance and computational complexity. In this work we revisit this method, providing an open-source C++ implementation reproducing the results. A detailed description is given and the choice of parameters is thoroughly discussed. Furthermore, we discuss several extensions of the original algorithm: (1) a multi-scale implementation, (2) the use of 3D patches, (3) the use of optical flow to guide the patch search. These extensions allow to obtain results which are competitive with even the most recent state of the art.