 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSING: A Plug-and-Play DNN Learning Technique
May 25, 2023



We propose SING (StabIlized and Normalized Gradient), a plug-and-play technique that improves the stability and generalization of the Adam(W) optimizer. SING is straightforward to implement and has minimal computational overhead, requiring only a layer-wise standardization of the gradients fed to Adam(W) without introducing additional hyper-parameters. We support the effectiveness and practicality of the proposed approach by showing improved results on a wide range of architectures, problems (such as image classification, depth estimation, and natural language processing), and in combination with other optimizers. We provide a theoretical analysis of the convergence of the method, and we show that by virtue of the standardization, SING can escape local minima narrower than a threshold that is inversely proportional to the network's depth.
Improving Pixel-Level Contrastive Learning by Leveraging Exogenous Depth Information
Nov 18, 2022Self-supervised representation learning based on Contrastive Learning (CL) has been the subject of much attention in recent years. This is due to the excellent results obtained on a variety of subsequent tasks (in particular classification), without requiring a large amount of labeled samples. However, most reference CL algorithms (such as SimCLR and MoCo, but also BYOL and Barlow Twins) are not adapted to pixel-level downstream tasks. One existing solution known as PixPro proposes a pixel-level approach that is based on filtering of pairs of positive/negative image crops of the same image using the distance between the crops in the whole image. We argue that this idea can be further enhanced by incorporating semantic information provided by exogenous data as an additional selection filter, which can be used (at training time) to improve the selection of the pixel-level positive/negative samples. In this paper we will focus on the depth information, which can be obtained by using a depth estimation network or measured from available data (stereovision, parallax motion, LiDAR, etc.). Scene depth can provide meaningful cues to distinguish pixels belonging to different objects based on their depth. We show that using this exogenous information in the contrastive loss leads to improved results and that the learned representations better follow the shapes of objects. In addition, we introduce a multi-scale loss that alleviates the issue of finding the training parameters adapted to different object sizes. We demonstrate the effectiveness of our ideas on the Breakout Segmentation on Borehole Images where we achieve an improvement of 1.9\% over PixPro and nearly 5\% over the supervised baseline. We further validate our technique on the indoor scene segmentation tasks with ScanNet and outdoor scenes with CityScapes ( 1.6\% and 1.1\% improvement over PixPro respectively).
Can neural networks extrapolate? Discussion of a theorem by Pedro Domingos
Nov 07, 2022Neural networks trained on large datasets by minimizing a loss have become the state-of-the-art approach for resolving data science problems, particularly in computer vision, image processing and natural language processing. In spite of their striking results, our theoretical understanding about how neural networks operate is limited. In particular, what are the interpolation capabilities of trained neural networks? In this paper we discuss a theorem of Domingos stating that "every machine learned by continuous gradient descent is approximately a kernel machine". According to Domingos, this fact leads to conclude that all machines trained on data are mere kernel machines. We first extend Domingo's result in the discrete case and to networks with vector-valued output. We then study its relevance and significance on simple examples. We find that in simple cases, the "neural tangent kernel" arising in Domingos' theorem does provide understanding of the networks' predictions. Furthermore, when the task given to the network grows in complexity, the interpolation capability of the network can be effectively explained by Domingos' theorem, and therefore is limited. We illustrate this fact on a classic perception theory problem: recovering a shape from its boundary.
Investigating Neural Architectures by Synthetic Dataset Design
Apr 23, 2022


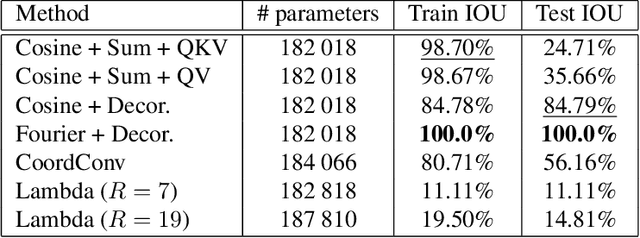
Recent years have seen the emergence of many new neural network structures (architectures and layers). To solve a given task, a network requires a certain set of abilities reflected in its structure. The required abilities depend on each task. There is so far no systematic study of the real capacities of the proposed neural structures. The question of what each structure can and cannot achieve is only partially answered by its performance on common benchmarks. Indeed, natural data contain complex unknown statistical cues. It is therefore impossible to know what cues a given neural structure is taking advantage of in such data. In this work, we sketch a methodology to measure the effect of each structure on a network's ability, by designing ad hoc synthetic datasets. Each dataset is tailored to assess a given ability and is reduced to its simplest form: each input contains exactly the amount of information needed to solve the task. We illustrate our methodology by building three datasets to evaluate each of the three following network properties: a) the ability to link local cues to distant inferences, b) the translation covariance and c) the ability to group pixels with the same characteristics and share information among them. Using a first simplified depth estimation dataset, we pinpoint a serious nonlocal deficit of the U-Net. We then evaluate how to resolve this limitation by embedding its structure with nonlocal layers, which allow computing complex features with long-range dependencies. Using a second dataset, we compare different positional encoding methods and use the results to further improve the U-Net on the depth estimation task. The third introduced dataset serves to demonstrate the need for self-attention-like mechanisms for resolving more realistic depth estimation tasks.