 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach
Oct 04, 2024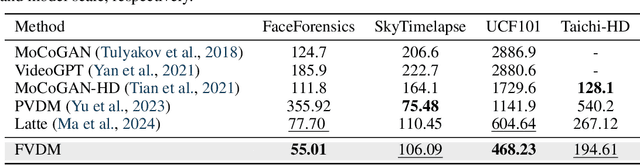
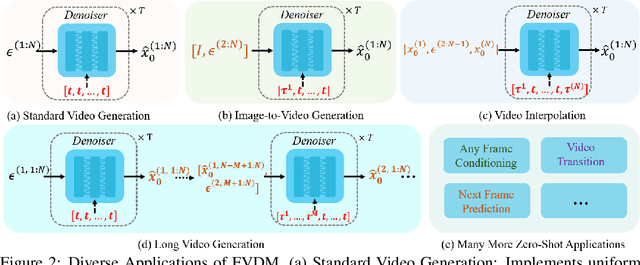
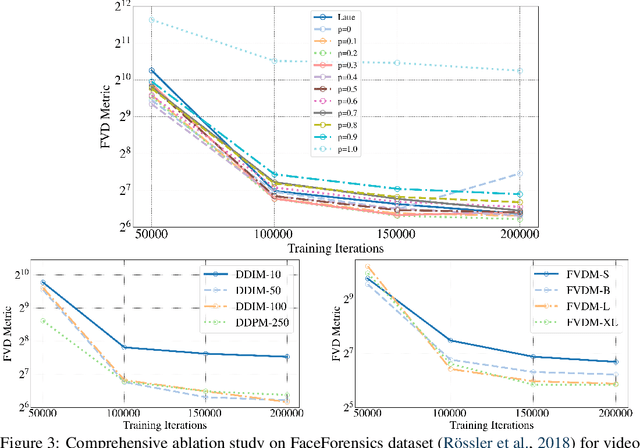

Diffusion models have revolutionized image generation, and their extension to video generation has shown promise. However, current video diffusion models~(VDMs) rely on a scalar timestep variable applied at the clip level, which limits their ability to model complex temporal dependencies needed for various tasks like image-to-video generation. To address this limitation, we propose a frame-aware video diffusion model~(FVDM), which introduces a novel vectorized timestep variable~(VTV). Unlike conventional VDMs, our approach allows each frame to follow an independent noise schedule, enhancing the model's capacity to capture fine-grained temporal dependencies. FVDM's flexibility is demonstrated across multiple tasks, including standard video generation, image-to-video generation, video interpolation, and long video synthesis. Through a diverse set of VTV configurations, we achieve superior quality in generated videos, overcoming challenges such as catastrophic forgetting during fine-tuning and limited generalizability in zero-shot methods.Our empirical evaluations show that FVDM outperforms state-of-the-art methods in video generation quality, while also excelling in extended tasks. By addressing fundamental shortcomings in existing VDMs, FVDM sets a new paradigm in video synthesis, offering a robust framework with significant implications for generative modeling and multimedia applications.
Adapting MIMO video restoration networks to low latency constraints
Aug 22, 2024


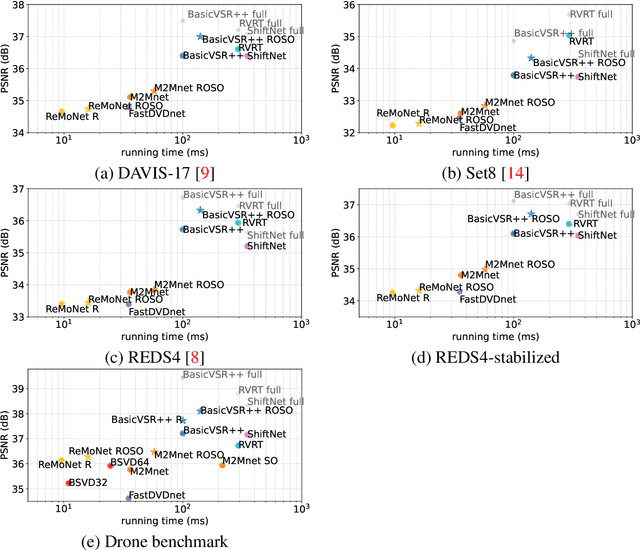
MIMO (multiple input, multiple output) approaches are a recent trend in neural network architectures for video restoration problems, where each network evaluation produces multiple output frames. The video is split into non-overlapping stacks of frames that are processed independently, resulting in a very appealing trade-off between output quality and computational cost. In this work we focus on the low-latency setting by limiting the number of available future frames. We find that MIMO architectures suffer from problems that have received little attention so far, namely (1) the performance drops significantly due to the reduced temporal receptive field, particularly for frames at the borders of the stack, (2) there are strong temporal discontinuities at stack transitions which induce a step-wise motion artifact. We propose two simple solutions to alleviate these problems: recurrence across MIMO stacks to boost the output quality by implicitly increasing the temporal receptive field, and overlapping of the output stacks to smooth the temporal discontinuity at stack transitions. These modifications can be applied to any MIMO architecture. We test them on three state-of-the-art video denoising networks with different computational cost. The proposed contributions result in a new state-of-the-art for low-latency networks, both in terms of reconstruction error and temporal consistency. As an additional contribution, we introduce a new benchmark consisting of drone footage that highlights temporal consistency issues that are not apparent in the standard benchmarks.