 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptively trained Physics-informed Radial Basis Function Neural Networks for Solving Multi-asset Option Pricing Problems
Jan 19, 2026The present study investigates the numerical solution of Black-Scholes partial differential equation (PDE) for option valuation with multiple underlying assets. We develop a physics-informed (PI) machine learning algorithm based on a radial basis function neural network (RBFNN) that concurrently optimizes the network architecture and predicts the target option price. The physics-informed radial basis function neural network (PIRBFNN) combines the strengths of the traditional radial basis function collocation method and the physics-informed neural network machine learning approach to effectively solve PDE problems in the financial context. By employing a PDE residual-based technique to adaptively refine the distribution of hidden neurons during the training process, the PIRBFNN facilitates accurate and efficient handling of multidimensional option pricing models featuring non-smooth payoff conditions. The validity of the proposed method is demonstrated through a set of experiments encompassing a single-asset European put option, a double-asset exchange option, and a four-asset basket call option.
Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach
Oct 04, 2024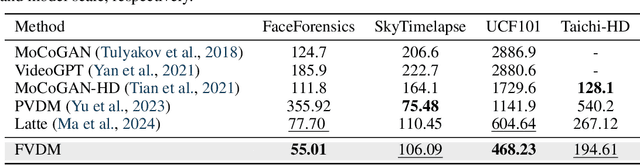
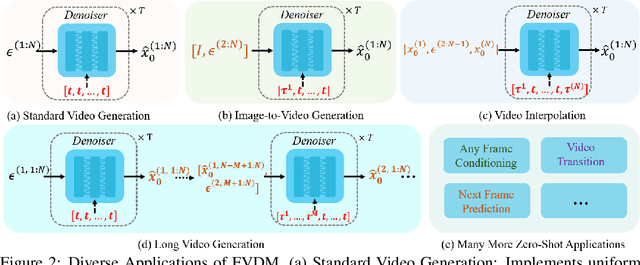
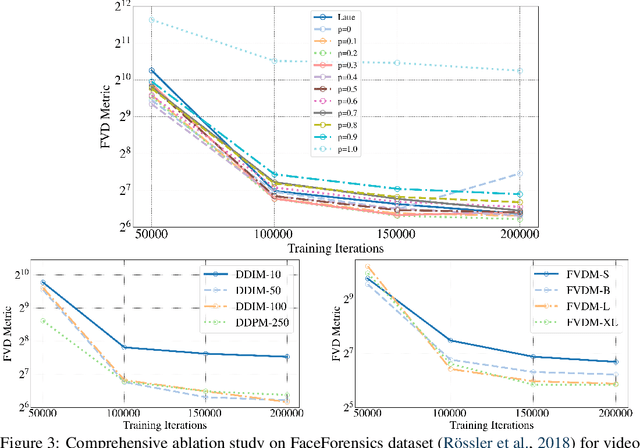

Diffusion models have revolutionized image generation, and their extension to video generation has shown promise. However, current video diffusion models~(VDMs) rely on a scalar timestep variable applied at the clip level, which limits their ability to model complex temporal dependencies needed for various tasks like image-to-video generation. To address this limitation, we propose a frame-aware video diffusion model~(FVDM), which introduces a novel vectorized timestep variable~(VTV). Unlike conventional VDMs, our approach allows each frame to follow an independent noise schedule, enhancing the model's capacity to capture fine-grained temporal dependencies. FVDM's flexibility is demonstrated across multiple tasks, including standard video generation, image-to-video generation, video interpolation, and long video synthesis. Through a diverse set of VTV configurations, we achieve superior quality in generated videos, overcoming challenges such as catastrophic forgetting during fine-tuning and limited generalizability in zero-shot methods.Our empirical evaluations show that FVDM outperforms state-of-the-art methods in video generation quality, while also excelling in extended tasks. By addressing fundamental shortcomings in existing VDMs, FVDM sets a new paradigm in video synthesis, offering a robust framework with significant implications for generative modeling and multimedia applications.
IDmUNet: A new image decomposition induced network for sparse feature segmentation
Mar 05, 2022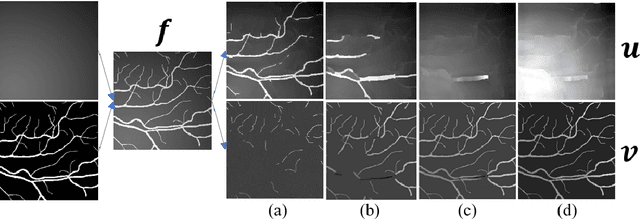
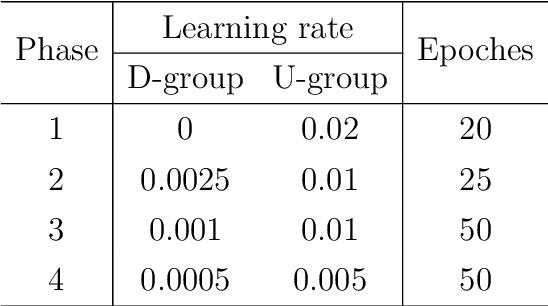
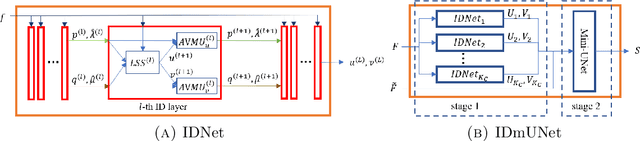
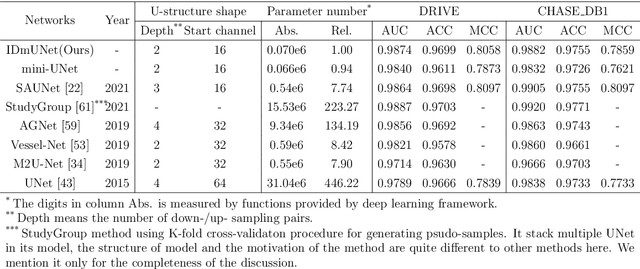
UNet and its variants are among the most popular methods for medical image segmentation. Despite their successes in task generality, most of them consider little mathematical modeling behind specific applications. In this paper, we focus on the sparse feature segmentation task and make a task-oriented network design, in which the target objects are sparsely distributed and the background is hard to be mathematically modeled. We start from an image decomposition model with sparsity regularization, and propose a deep unfolding network, namely IDNet, based on an iterative solver, scaled alternating direction method of multipliers (scaled-ADMM). The IDNet splits raw inputs into double feature layers. Then a new task-oriented segmentation network is constructed, dubbed as IDmUNet, based on the proposed IDNets and a mini-UNet. Because of the sparsity prior and deep unfolding method in the structure design, this IDmUNet combines the advantages of mathematical modeling and data-driven approaches. Firstly, our approach has mathematical interpretability and can achieve favorable performance with far fewer learnable parameters. Secondly, our IDmUNet is robust in a simple end-to-end training with explainable behaviors. In the experiments of retinal vessel segmentation (RVS), IDmUNet produces the state-of-the-art results with only 0.07m parameters, whereas SA-UNet, one of the latest variants of UNet, contains 0.54m and the original UNet 31.04m. Moreover, the training procedure of our network converges faster without overfitting phenomenon. This decomposition-based network construction strategy can be generalized to other problems with mathematically clear targets and complicated unclear backgrounds.